【论文笔记】强化学习+对抗,面向任务的神经对话模型新思路
【导读】在这篇即将发表在SIGDIAL的文章中,为了优化面向任务的神经对话模型,作者提出了一种强化学习奖励评估的对抗学习方法。目前大多数基于强化学习的面向任务的对话系统都需要从用户反馈或用户评分中获得奖励信号。然而,这样的用户评级在实践中可能并不一致或可用。此外,使用强化学习进行在线对话策略学习通常需要向用户提供大量查询,这些问题都存在样本效率问题。
为了解决这些挑战,作者提出了一种对抗学习方法,以直接从对话样本中学习对话奖励。这些奖励进一步用于优化基于policy gradient的强化学习对话策略。作者在DSTC2数据集(餐馆搜索任务)上验证了自己的模型。
【SIGDIAL 2018 论文】
Adversarial Learning of Task-Oriented Neural Dialog Models

原文链接:https://arxiv.org/abs/1805.11762
简介
面向任务的对话系统旨在帮助用户完成日常任务,如完成预订和提供客户支持。与单轮问答模型相比,面向任务的对话系统涉及从外部资源中检索信息并通过多次对话转换推理,需要依赖上下文信息。
最近在面向任务的对话系统上,研究人员侧重于使用人 - 人或人机对话的数据驱动方法学习对话模型。 研究人员将对话模型看成是一个强化学习的过程。如下所示:将用户看成是强化学习中的环境,系统的目标是设计一个Agent,能够自动生成对用户的回复(Action)。而生成器的优化,依赖于环境(用户)对生成的回复的反馈(reward)和当前任务完成的情况(state)。
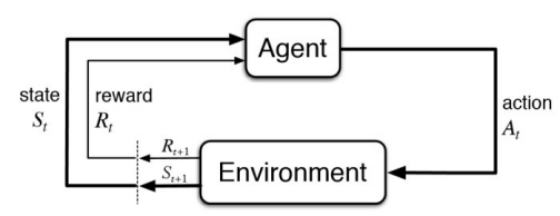
由于在实际生活中,用户的反馈并不是那么容易获得,即使获得也存在不一致问题。所以在奖励函数的设计上,作者融入了对抗学习的思想。将Agent生成回复的过程看成是一个生成器,并使用额外的判别器来生成reward,判别数据集中真实的客服与用户的对话与系统生成的对话之间的“真”与“假”。将生成器与判别器进行对抗学习,生成器的目标是生成“以假乱真”的样本迷惑判别器,判别器的目标是尽可能的判别真实的数据与生成的样本。当模型训练好之后,就能像真正的客服一样回复用户了(理想状态下)。
模型结构
生成器的结构
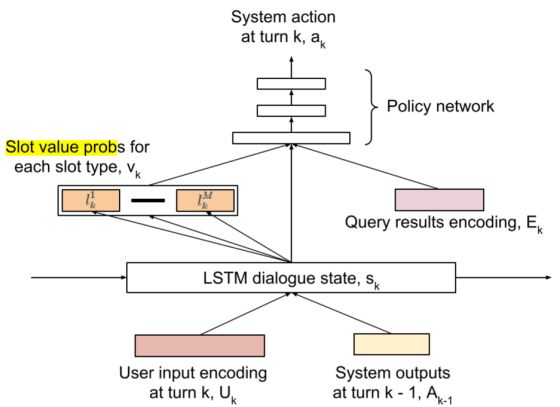
生成器的模型如上图所示,Agent使用一个LSTM来进行序列建模。在每轮对话中,用户的输入和系统上一轮的输出首先被编码成向量表示,第k轮对话系统的隐层状态就可以更新为:
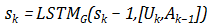
在生成隐层状态之后,可以对它进行进一步计算,得到用户的目标的表示(Slot Value)。以订餐的任务而言,slot 的类型可以是“菜系”、“地点”、“时间”等。如“五道口东来顺,今天六点,两个人的位子”就可以提取出(place=五道口),(restaurant=东来顺),(time=6pm)等slot-value对。除此之外,生成回答时,还需要从额外的数据库中查找对应的信息,如订餐的任务,首先要查找该餐馆对应时间还有没有空余的座位等,查询的结果经过编码之后,用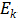
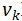
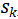
在这里,Policy Network使用的是单层感知机,输出一个softmax,即系统中每个可能的回复的概率。
判别器的结构
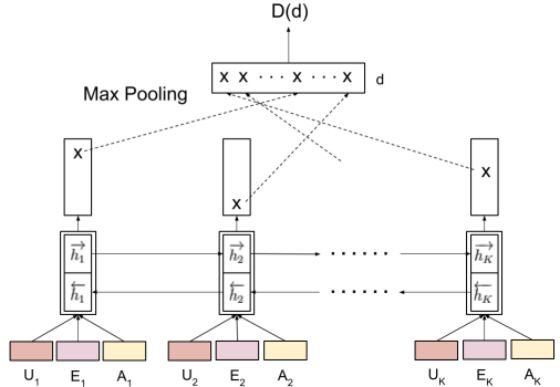
在一组多轮对话的任务完成之后,接下来就依靠判别器对整个回复的过程进行判别,生成reward。
首先将对话过程中每一轮的用户的话,系统中检索到的结果,系统的回复输入到一个双向LSTM中,并取结果中的LSTM最终输出、max-pooling(将输出向量中每一维最大的拼接起来),Average-pooling(输出向量每一维的平均),attention(每一维按照计算得到的attention加权)等方式组成最后的输出向量,判别最后的结果。
实验结果
实验是在Dialog State Tracking Challenge比赛提供的(DSTC2)数据集上进行的。作者将数据集中的实体提取出来,构成知识库,作为检索的来源。
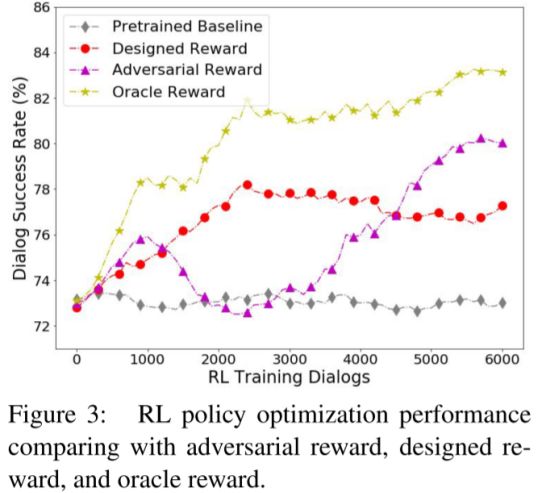
作者使用别的奖励函数作为对比,如 Oracle reward,Designed Reward. Pretrained Baseline等,并使用对话成功率作为指标。对比结果如下所示,可见对抗奖励函数在训练轮数较少的情况下优势不大,但是最终还是超过了大多数方法,也超过了baseline的方法7.4%的百分点。但是缺点还是显而易见的,虽然在最后结果还算不错,但是在训练的过程中,方差较大,表现的不稳定,极端时候甚至略差于baseline。这是因为在强化学习的训练过程中,agent的目标在不断改变。当agent和判别器都逐渐趋于收敛时,模型也就稳定了。
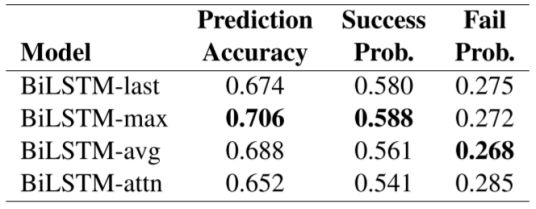
除此之外,作者还分析了在判别器中使用什么特征能够得到最好的效果。可见使用max-pooling的效果是最好的。但是用上attention的反而效果不好,作者分析了原因可能是因为训练样本不够导致的。
原文链接:
https://arxiv.org/abs/1805.11762
更多专业AI教程资料请加入专知人工智能知识星球群获取,扫描下面二维码即可!
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取。欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知
展开全文



