多模态多任务学习新论文
【导读】在本文中,我们提出了一个多任务模型,能够共同学习这些多模式任务,并在任务中传递单词的知识及其在视觉对象中的基础。
【摘要】
最近在使用深度强化学习的语言训练视觉导航智能体方面的努力已经成功地学习了用于不同多模态任务的策略,例如语义目标导航和问答。在本文中,我们提出了一个多任务模型,能够共同学习这些多模式任务,并在任务中传递单词的知识及其在视觉对象中的基础。论文中所提出的模型使用新颖的双注意单元来解开视觉表示中的文本表示和视觉概念中的单词的知识,并使它们彼此对齐。这种解耦的任务不变的表示对齐有助于跨两个任务的基础和知识转移。我们表明,所提出的模型在模拟3D环境中优于两个任务的一系列基线。我们还表明,这种表示的解开使我们的模型模块化,可解释,并允许通过利用对象检测器转移到包含新单词的指令。

【简介】
多模态任务: 我们专注于两个基于视觉的语言导航任务的多任务学习:在语义目标导航(Semantic Goal Navigation: SGN)中,智能体被给予语言指令(“转到红色火炬”)以导航到目标位置。 在Embodied Question Answering(EQA)中,智能体会被问道:“火炬的颜色是什么?”,它必须在3D环境中切换以探索环境并收集信息以回答问题(“红色”)。

跨任务知识转移。 创建训练和测试集以测试SGN和EQA之间的跨任务知识转移。 在SGN的测试集中,包含一个在SGN训练集中不存在,但是在EQA训练集中存在的单词。在EQA测试集中,包含一个EQA训练集中不存在,但是在SGN训练集中存在的单词。
【模型】
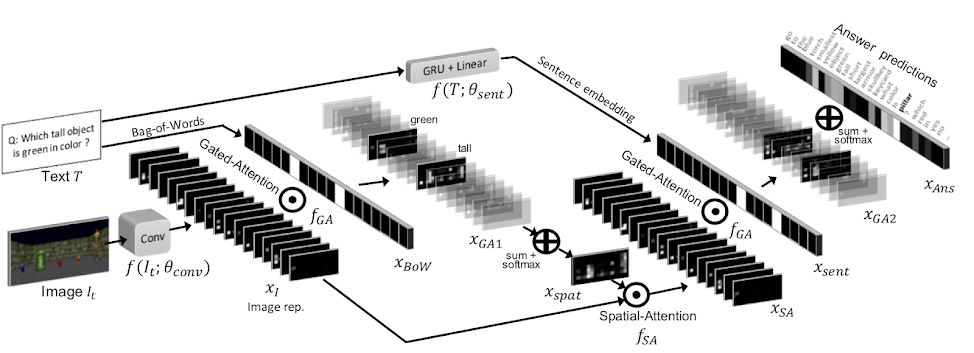
双注意力模型
原文链接:
https://sites.google.com/view/emml/
论文地址:
https://arxiv.org/abs/1902.01385
-END-
专 · 知
专知《深度学习:算法到实战》课程全部完成!470+位同学在学习,现在报名,限时优惠!网易云课堂人工智能畅销榜首位!

请加专知小助手微信(扫一扫如下二维码添加),咨询《深度学习:算法到实战》参团限时优惠报名~

欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

点击“阅读原文”,了解报名专知《深度学习:算法到实战》课程
展开全文



