【论文推荐】最新七篇自动问答相关论文—答案重排序、电影问答、句子间交互、用户意图、实体链接、多尺度匹配对抗训练
【导读】专知内容组整理了最近七篇自动问答(Question Answering)相关文章,为大家进行介绍,欢迎查看!
1. Evidence Aggregation for Answer Re-Ranking in Open-Domain Question Answering(开放域问答中基于证据聚合的答案重排序)
作者:Shuohang Wang,Mo Yu,Jing Jiang,Wei Zhang,Xiaoxiao Guo,Shiyu Chang,Zhiguo Wang,Tim Klinger,Gerald Tesauro,Murray Campbell
机构:Singapore Management University
摘要:A popular recent approach to answering open-domain questions is to first search for question-related passages and then apply reading comprehension models to extract answers. Existing methods usually extract answers from single passages independently. But some questions require a combination of evidence from across different sources to answer correctly. In this paper, we propose two models which make use of multiple passages to generate their answers. Both use an answer-reranking approach which reorders the answer candidates generated by an existing state-of-the-art QA model. We propose two methods, namely, strength-based re-ranking and coverage-based re-ranking, to make use of the aggregated evidence from different passages to better determine the answer. Our models have achieved state-of-the-art results on three public open-domain QA datasets: Quasar-T, SearchQA and the open-domain version of TriviaQA, with about 8 percentage points of improvement over the former two datasets.

期刊:arXiv, 2018年4月26日
网址:
http://www.zhuanzhi.ai/document/463b2ad03fb33842e872260ab48f30f2
2. Movie Question Answering: Remembering the Textual Cues for Layered Visual Contents(电影问答:记住分层视觉内容的文本线索)
作者:Bo Wang,Youjiang Xu,Yahong Han,Richang Hong
机构:Tianjin University,Hefei University of Technology
摘要:Movies provide us with a mass of visual content as well as attracting stories. Existing methods have illustrated that understanding movie stories through only visual content is still a hard problem. In this paper, for answering questions about movies, we put forward a Layered Memory Network (LMN) that represents frame-level and clip-level movie content by the Static Word Memory module and the Dynamic Subtitle Memory module, respectively. Particularly, we firstly extract words and sentences from the training movie subtitles. Then the hierarchically formed movie representations, which are learned from LMN, not only encode the correspondence between words and visual content inside frames, but also encode the temporal alignment between sentences and frames inside movie clips. We also extend our LMN model into three variant frameworks to illustrate the good extendable capabilities. We conduct extensive experiments on the MovieQA dataset. With only visual content as inputs, LMN with frame-level representation obtains a large performance improvement. When incorporating subtitles into LMN to form the clip-level representation, we achieve the state-of-the-art performance on the online evaluation task of 'Video+Subtitles'. The good performance successfully demonstrates that the proposed framework of LMN is effective and the hierarchically formed movie representations have good potential for the applications of movie question answering.
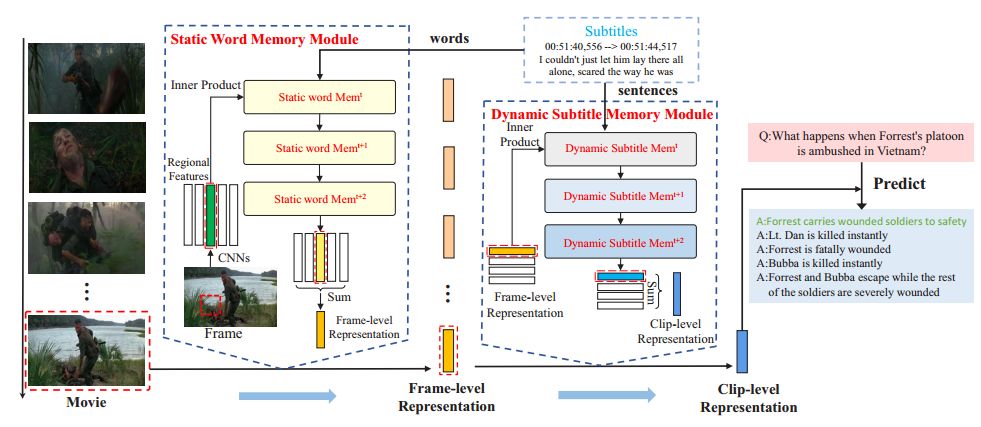
期刊:arXiv, 2018年4月25日
网址:
http://www.zhuanzhi.ai/document/9f5331fc73fc7c715fe26d3aa4933cc5
3. End-Task Oriented Textual Entailment via Deep Exploring Inter-Sentence Interactions(通过深度探索句子间交互实现面向任务的文本蕴涵)
作者:Wenpeng Yin,Dan Roth,Hinrich Schütze
机构:University of Pennsylvania
摘要:This work deals with SciTail, a natural entailment problem derived from a multi-choice question answering task. The premises and hypotheses in SciTail were authored independent of each other and independent of the entailment task, which makes it more challenging than other entailment tasks as linguistic variations in it are not limited by the coverage of hand-designed rules or the creativity of crowd-workers. We propose DEISTE (deep exploring inter-sentence interactions for textual entailment) for this entailment task. Given word-to-word interactions between the premise-hypothesis pair ($P$, $H$), DEISTE consists of: (i) A parameter-dynamic convolution to make important words in $P$ and $H$ play a dominant role in learnt representations; (ii) A position-aware attentive convolution to encode the representation and position information of the aligned word pairs. Experiments show DEISTEe gets ~ 5% improvement over prior state of the art. Code & model: https://github.com/yinwenpeng/SciTail
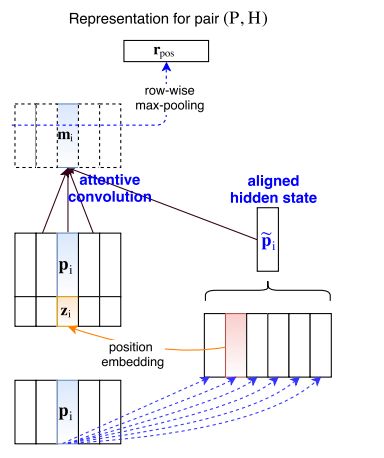
期刊:arXiv, 2018年4月24日
网址:
http://www.zhuanzhi.ai/document/858eaabc6a22e2d642a8296b9ba3c37d
4. Analyzing and Characterizing User Intent in Information-seeking Conversations(信息检索会话中用户意图的分析与表征)
作者:Chen Qu,Liu Yang,W. Bruce Croft,Johanne R. Trippas,Yongfeng Zhang,Minghui Qiu
机构:Rutgers University,RMIT University
摘要:Understanding and characterizing how people interact in information-seeking conversations is crucial in developing conversational search systems. In this paper, we introduce a new dataset designed for this purpose and use it to analyze information-seeking conversations by user intent distribution, co-occurrence, and flow patterns. The MSDialog dataset is a labeled dialog dataset of question answering (QA) interactions between information seekers and providers from an online forum on Microsoft products. The dataset contains more than 2,000 multi-turn QA dialogs with 10,000 utterances that are annotated with user intent on the utterance level. Annotations were done using crowdsourcing. With MSDialog, we find some highly recurring patterns in user intent during an information-seeking process. They could be useful for designing conversational search systems. We will make our dataset freely available to encourage exploration of information-seeking conversation models.
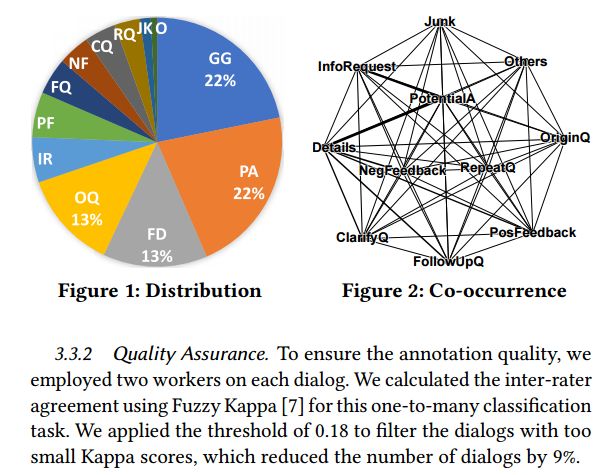
期刊:arXiv, 2018年4月24日
网址:
http://www.zhuanzhi.ai/document/441137793741ef3efe70d17a25cfd0b2
5. Mixing Context Granularities for Improved Entity Linking on Question Answering Data across Entity Categories(跨实体类别问答数据中混合上下文粒度改进实体链接)
作者:Daniil Sorokin,Iryna Gurevych
机构:Technische Universitat Darmstadt
摘要:The first stage of every knowledge base question answering approach is to link entities in the input question. We investigate entity linking in the context of a question answering task and present a jointly optimized neural architecture for entity mention detection and entity disambiguation that models the surrounding context on different levels of granularity. We use the Wikidata knowledge base and available question answering datasets to create benchmarks for entity linking on question answering data. Our approach outperforms the previous state-of-the-art system on this data, resulting in an average 8% improvement of the final score. We further demonstrate that our model delivers a strong performance across different entity categories.
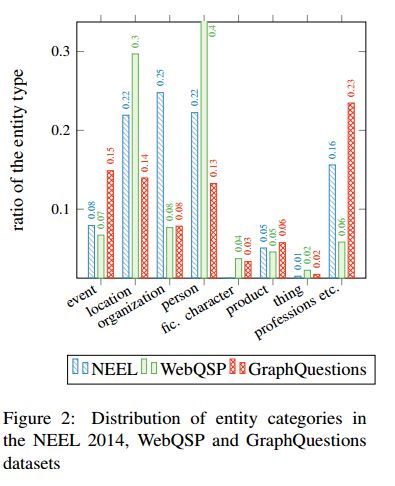
期刊:arXiv, 2018年4月23日
网址:
http://www.zhuanzhi.ai/document/1c20e5f5b06e71c9d01526272a079c12
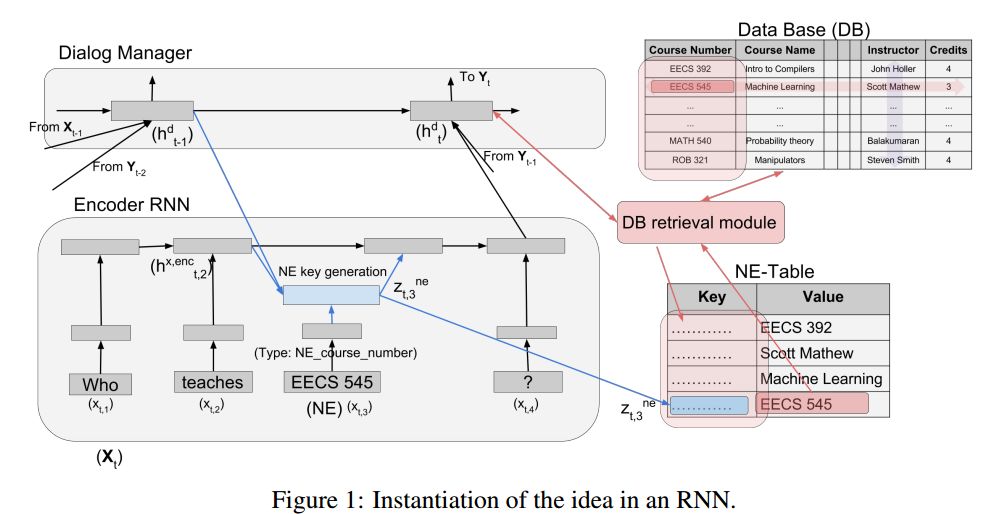
6. Named Entities troubling your Neural Methods? Build NE-Table: A neural approach for handling Named Entities(Build NE-Table: 一种命名实体的神经网络方法)
作者:Janarthanan Rajendran,Jatin Ganhotra,Xiaoxiao Guo,Mo Yu,Satinder Singh
机构:University of Michigan
摘要:Many natural language processing tasks require dealing with Named Entities (NEs) in the texts themselves and sometimes also in external knowledge sources. While this is often easy for humans, recent neural methods that rely on learned word embeddings for NLP tasks have difficulty with it, especially with out of vocabulary or rare NEs. In this paper, we propose a new neural method for this problem, and present empirical evaluations on a structured Question-Answering task, three related Goal-Oriented dialog tasks and a reading-comprehension-based task. They show that our proposed method can be effective in dealing with both in-vocabulary and out of vocabulary (OOV) NEs. We create extended versions of dialog bAbI tasks 1,2 and 4 and Out-of-vocabulary (OOV) versions of the CBT test set which will be made publicly available online.
期刊:arXiv, 2018年4月23日
网址:
http://www.zhuanzhi.ai/document/33f728fba0ca90194fbcd797697961b7
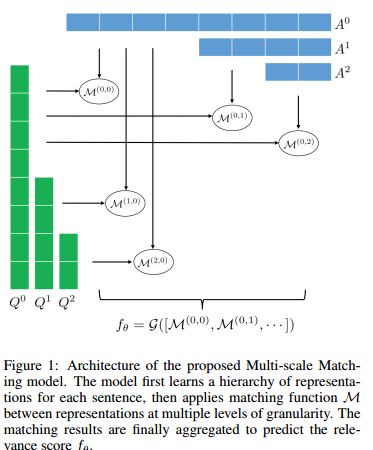
7. Adversarial Training for Community Question Answer Selection Based on Multi-scale Matching(基于多尺度匹配对抗训练的社区问答选择)
作者:Xiao Yang,Miaosen Wang,Wei Wang,Madian Khabsa,Ahmed Awadallah
机构:Pennsylvania State University
摘要:Community-based question answering (CQA) websites represent an important source of information. As a result, the problem of matching the most valuable answers to their corresponding questions has become an increasingly popular research topic. We frame this task as a binary (relevant/irrelevant) classification problem, and propose a Multi-scale Matching model that inspects the correlation between words and ngrams (word-to-ngrams) of different levels of granularity. This is in addition to word-to-word correlations which are used in most prior work. In this way, our model is able to capture rich context information conveyed in ngrams, therefore can better differentiate good answers from bad ones. Furthermore, we present an adversarial training framework to iteratively generate challenging negative samples to fool the proposed classification model. This is completely different from previous methods, where negative samples are uniformly sampled from the dataset during training process. The proposed method is evaluated on SemEval 2017 and Yahoo Answer dataset and achieves state-of-the-art performance.
期刊:arXiv, 2018年4月22日
网址:
http://www.zhuanzhi.ai/document/1ff91cd3d76b67da54c65a022d8cf333
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取

点击上面图片加入会员
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

点击“阅读原文”,使用专知
展开全文



