【AAAI2018 Oral】基于Self-attention的文本向量表示方法,悉尼科技大学和华盛顿大学最新工作(附代码)
【导读】循环神经网络(RNN)与卷积神经网络(CNN)被广泛使用在深度神经网络里来解决不同的自然语言处理(NLP)任务,但是受限于各自的缺点(即,RNN效果较好但参数较多效率较低,CNN效率高参数少但效果欠佳)。最近,来自悉尼科技大学(UTS)与华盛顿大学(UW)的科研人员提出了一种Self-attention网络用于生成Sentence Encoding(句子向量化)。在不使用任何RNN和CNN结构的情况下,此网络使用较少的参数同样可以在多个数据集上达到state-of-the-art的性能。此文章已被AAAI-18接收为Oral presentation。
论文: DiSAN: Directional Self-Attention Network for RNN/CNN-Free Language Understanding

论文链接: https://arxiv.org/abs/1709.04696
论文代码: https://github.com/taoshen58/DiSAN
张成奇,杰出教授,现任悉尼科技大学(UTS)副校长, 澳大利亚人工智能理事会理事长。他从事人工智能相关研究长达35年,并发表近300篇的学术论文,他于1992年6月在 “国际人工智能杂志(Artificial Intelligence Journal)”发表了大陆华人的第一篇论文。根据2018年1月份Google Scholar统计,文章被引用总数超过万次,H-Index为44。他曾担任ICDM和KDD等五个国际会议的大会主席,程序委员会主席和组织委员会主席等职务,并曾担任国际人工智能大会IJCAI 2017年当地组织委员会主席。自2014年6月起,任IEEE计算机学会智能信息技术委员会(TCII)主席。
▌摘要
RNN与CNN被广泛使用在NLP任务中用于分别捕捉长期(long-term)和本地(local)的依赖关系(dependencies)。注意力机制(Attention Mechanism)最近吸引了大量的关注因为它的可并行化的计算,较少的模型训练时间和长期/本地依赖捕捉的灵活性。
我们提出一种新颖的注意力机制,用于捕捉序列中不同的元素之间的attention信息。而且这种attention是有方向的并且是多维度的。然后,基于这种注意力机制,一个轻量级的网络,"Directional Self-Attention Network (DiSAN)",被提出用于学习句子的向量(句子向量化)。DiSAN不需要基于任何的RNN或CNN结构而仅仅是注意力机制。DiSAN由directional self-attention(用于编码上下文和方向信息)和multi-dimensional attention(用于将一序列压缩成一个向量)组成。
尽管结构简单,DiSAN可以在预测效果和时间效率上超过复杂的RNN模型。DiSAN在Stanford Natural Language Inference (SNLI) 数据集上可以达到最好的效果。并且在Stanford Sentiment Treebank (SST)数据集上可以达到state-of-the-art效果。同时,文章还在其他基准数据集上达到state-of-the-art水平,包括Multi-Genre natural language inference (MultiNLI), Sentences Involving Compositional Knowledge (SICK), Customer Review, MPQA, TREC question-type classification 和 Subjectivity (SUBJ) 数据集。
▌1. 动机与目标
1.1 动机
上下文依赖(Contextual dependency)在NLP任务中一直处于重要的地位,最流行的方法是使用RNN(LSTM,GRU等)或者是CNN模型来捕捉这些依赖。最近的研究工作发现,给这些基于RNN或CNN的方法加上注意力机制可以在不同的任务上达到新的state-of-the-art的效果,例如机器翻译,自然语言推断,对话生成,机器问答,机器理解等。注意力机制可以计算序列中每个元素的重要程度,并按照其重要程度把所有元素合并起来。由于这种合并是位置无关的,所以可以提供补充的信息给RNN或者CNN这类distance-aware的模型。同时,attention的计算是高度可并行的,不需要像RNN那样需要时域的迭代。
在最近的工作中,一种仅仅基于注意力机制的Seq2Seq模型被提出(“Transformer”),并在机器翻译上取得了新的state-of-the-art的翻译效果。其主要的组成,“multi-head attention”,实际上就是一种自注意力(self-attention)机制。
Attention能够比RNN/CNN更灵活地处理不同长度的句子,而且在捕捉依赖的时候更加的数据/任务驱动(task/data-driven)。不同于序列模型,attention可以更好的利用当前的并行和分布式运算来加速。
但是,据我们所知,除了用于Seq2seq模型的Transformer,还没有其他模型仅仅使用attention被提出用于解决其他NLP任务。另外,self-attention过程中不会考虑两个元素的位置关系,所以如何在self-attention过程中引入时域顺序信息一直是重要的问题。“multi-head attention”引入positional encoding直接与输入的序列相加来解决这个问题。
1.2 目标
这篇文章的主要目的是开发出一可以被广泛使用的和RNN/CNN-free的self-attention网络,可以用于在不同NLP任务中的自然语句编码上,其中任务包括自然语言推断(natural language inference),情感分析(sentiment analysis),语句分类(sentence classification),语义相关(semantic relatedness)等。
我们提出了一种新颖的self-attention机制,在以下两点不同于以前的工作:
(1)多维度的,也就是说attention是基于每个特征的(feature);
(2)有方向的,使用“位置掩码(Positional Masks)”来提供元素间的非对称attention,用于捕捉位置信息。
我们计算feature级别的Attention,因为在神经网络中,NLP中的每个token都以特征向量(low-dimension feature vector representation)的形式存在。在不同特征上的attention可以包含不同的依赖信息,因此可以更有效地处理同一个单词上下文的变化,即,一词多义。另外,此attention使用位置掩码来建模先验的结构信息,例如时域顺序或依赖关系。这使得提出的attention机制可以克服现有的Attention无法捕捉序列的时域顺序的缺点。
基于上述的attention机制,一个轻量和不依赖RNN/CNN的网络,“Directional Self-Attention Network (DiSAN)”,被提出。在DiSAN中,输入首先被directional(前向和后向) self-attentions 处理,来得到每个元素的上下文感知的(context-aware)向量表达,然后用multi-dimensional attention来压缩这些元素来得到整个序列的向量表达,完成sentence encoding的目标。
在实验中,我们在不同的NLP任务上对比DiSAN与现在最流行的方法。实验结果表明,DiSAN可以再自然语言推断,情感分析,语句分类,语义相关等任务上取得最好或者state-of-the-art的预测质量。并且使用较少的参数和拥有更高的计算效率。
▌2. 提出的模型
2.1 Multi-dimensional Attention
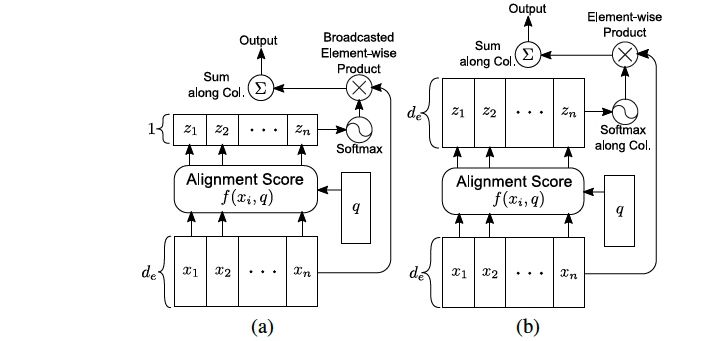
图1:(a)传统的Attention,和(b)multi-dimensional attention. 表示alignment scores, 在(a)中是标量但在(b)中是向量。
图1对比了一般的attention与提出的Multi-dimensional Attention的区别,即,Multi-dimensional Attention中由兼容性函数(compatibility function)计算得出的每个元素的attention分数(alignment score)与输入是同维向量,而传统的方法仅生成一个标量。
Multi-dimensional Attention兼容性函数为:
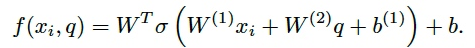
因此attention的结果可以写成:
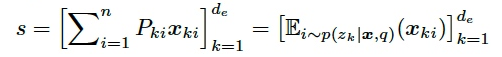
2.2 Two Types of Multi-dimensional Self-Attention
“token2token” self-attention
token2token self-attention目的是为序列中的每个元素生成上下文感知的向量表达,这里简单的将上文提到的兼容性函数中的query替换为输入序列的中的某个元素,即:
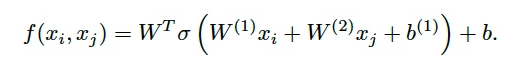
因此,此兼容性函数可以建模同个序列两个不同元素的依赖关系,并根据这个依赖关系来建立两个元素间的attention.
“source2token” self-attention
source2token self-attention 目的是压缩序列为一个向量表达而不是通过一般的max-pooling来完成这一步骤。这里简单的将query去掉,这更加体现了attention的任务驱动性(task-driven)。兼容函数变为:
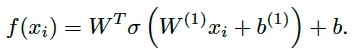
2.3 Directional Self-Attention(DiSA)
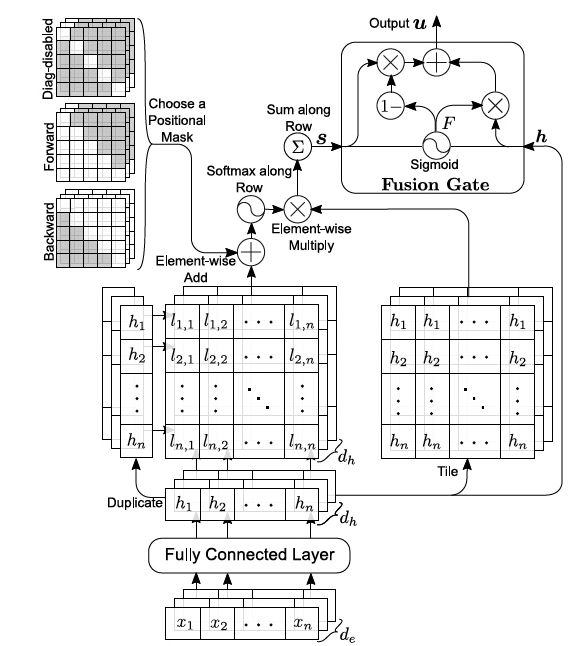
图2:Directional self-attention (DiSA)机制。这里用表示公式15中的
图2展示了DiSA的结构图,其中包含了两个关键组成部分:
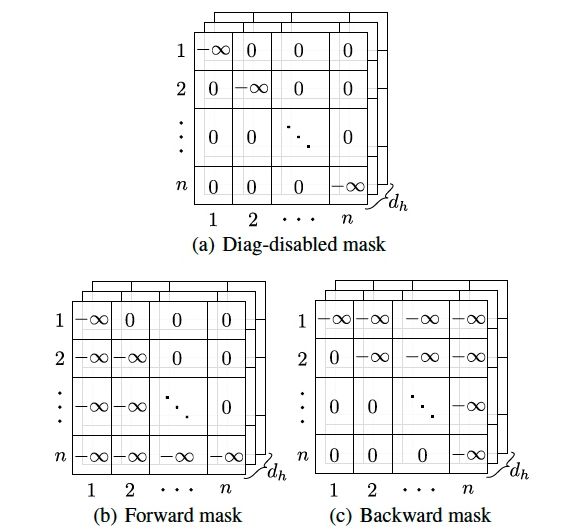
图3:三种positional masks:(a)为diag-disable mask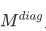
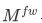
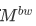
Positional Masks(位置掩码)
用于捕捉时域顺序信息和model非对称Attention。融入DiSA的方式就是将其直接加在兼容性函数的结果(即Attention分数)上。其定义如下(或如图3)。Mask的值为0或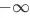
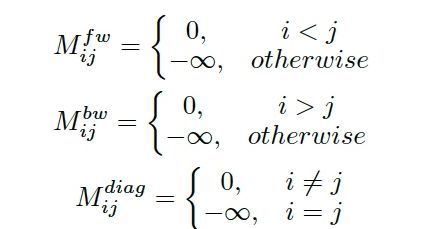
Fusion Gate(融合门)
用于结合此self-attention的输入(原始表达)和输出(上下文特征),为了得到上下文感知的向量表达。其定义如下。
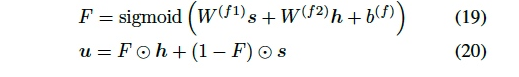
其中h是self-attention输入;s为self-attention输出(仅包含了contextual features)。F是element-wise的融合门的值。
2.4 Directional Self-Attention Network (DiSAN)
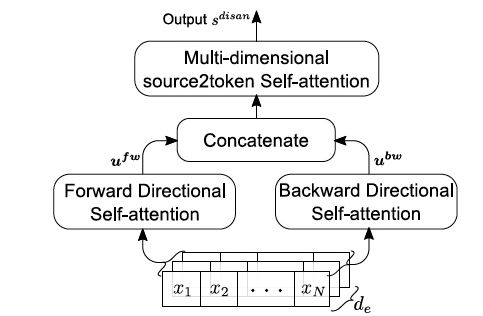
图4:Directional self-attention network (DiSAN)
图四表示了文章的语句编码(Sentence Encoding)模型,其包含前向与后向的DiSA(即 DiSA with forward and backward positional masks);最后,source2token self-attention用于将序列压缩称为一个向量来表征整个句子。
▌3. 实验结果
Baselines:
词向量 + 传统的Attention机制
词向量 + 文章提出的source2token self-attention
multi-head attention + source2token self-attention
Bi-LSTM + source2token self-attention
没有positional masks的DiSAN
3.1 自然语言推断(Natural Language Inference)
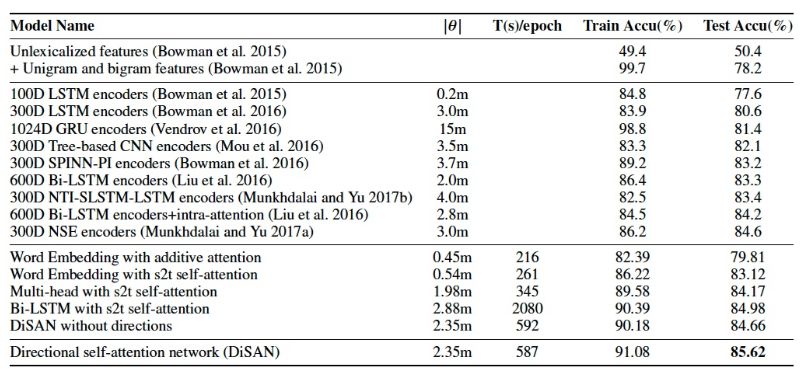
表1:SNLI数据集上的实验结果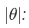
与其他sentence-encoding模型进行对比,在拥有较高时间效率和使用较少参数的情况下,比之前基于RNN,CNN或更加复杂的的model效果更好。
3.2 情感分析(Sentiment Analysis)
情感分析的实验使用的是Stanford Sentiment Treebank (SST) 数据集,并在细粒度(5分类)的数据上进行了实验。实验结果见表2。
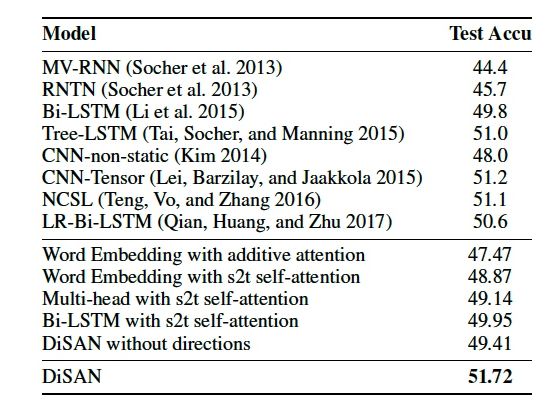
表2:Stanford Sentiment Treebank数据集上细粒度情感分类的效果。
在SST的测试集上,不同长度的句子的预测正确率的折线图如图5,其对比了LSTM,Bi-LSTM和Tree-LSTM。
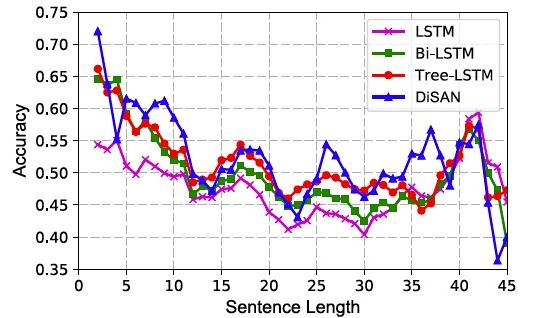
图5:细粒度情感分析精度 vs. 句子长度。
3.3 Multi-Genre Natural Language Inference
因为官方没有像SNLI一样提供针针对sentence-encoding专门的leaderboard,所以这里只与官方提供的sentence-encoding的baselines进行对比,结果如下:
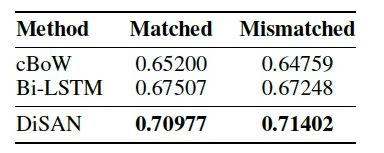
表3:在MultiNLI数据集上的实验结果。
3.4 Semantic Relatedness
在语句相关性分析任务中的Sentences Involving Compositional Knowledge (SICK)数据集上,DiSAN与其他的方法对比如表4。
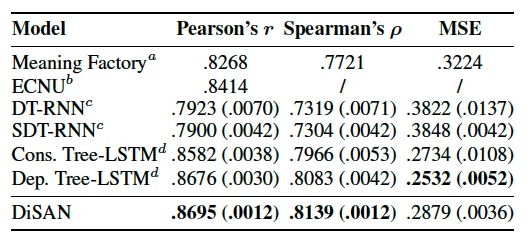
表4:在SICK数据集上的实验结果。报告的实验结果为5次运行的平均值(括号内为方差)。
3.5 Sentence Classifications
文章在以下四个Sentence Classification的benchmark数据集上做了实验:
1)CR: Customer review;
2)MPQA;
3)SUBJ: Subjectivity dataset;
4)TREC: TREC question-type classification dataset。
实验结果如表5。
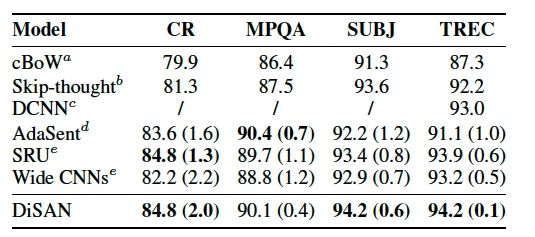
表5:在不同的句子分类的benchmark上的实验结果。在CR,MPQA,和SUBJ报告的精度为10次交叉验证的平均结果;在TREC上报告的为5次平均的结果。(括号中的值为标准差)
3.6 Case Study
文章最后给出了case study分析,这里仅简要地把attention的热力图给出,具体地分析请参考原文的对应章节。
1. 前向与后向的Attention分数
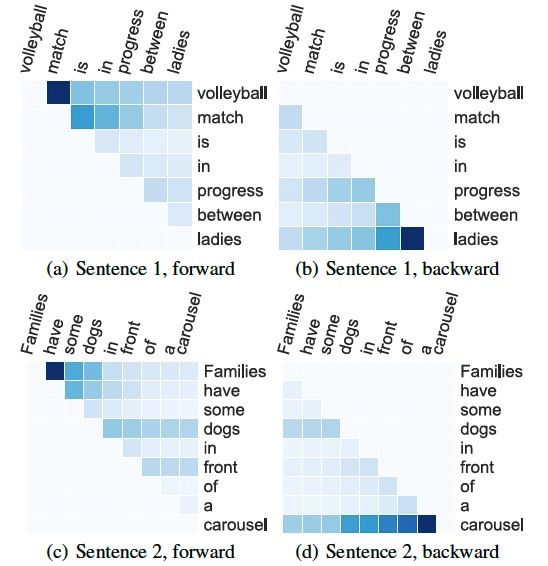
图6:两个句子在前向/后向DiSA模块中的Attention概率值。
2. 融合门的值
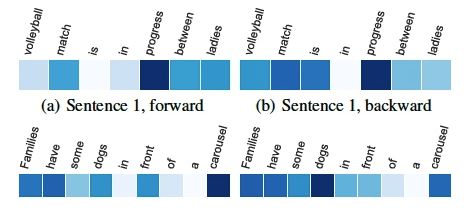
图7:两个句子在前向/后向DiSA模块中Fusion Gate的值。
3. Source2token attention的每个维度的Attention分数

图8:两对同一单词在不同语境下的attention概率值的对比。其中,Pair 1 为 【The glass bottle is big;A man is pouring a glass of tea】,Pair 2为【The restaurant is about to close;A biker is close to the fountain】
▌4. 后记
这篇文章详细地介绍了目前主流的Attention和self-attention的方法,并在前人的基础上提出了两种新的Attention方式,在NLP的句子向量化领域成功地超越了目前比较流行的RNN、CNN或者其他复杂的方法。文章的实验也比较饱满,提出的模型在8个benchmark数据集上达到了competitive的结构。
参考文献:https://arxiv.org/abs/1709.04696
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!

点击“阅读原文”,使用专知!
展开全文



