【干货】手把手教你用苹果Core ML和Swift开发人脸目标识别APP
【导读】CoreML是2017年苹果WWDC发布的最令人兴奋的功能之一。它可用于将机器学习整合到应用程序中,并且全部脱机。CoreML提供的机器学习 API,包括面部识别的视觉 API、自然语言处理 API 。苹果软件主管兼高级副总裁 Craig Federighi 在大会上介绍说,Core ML 致力于加速在 iPhone、iPad、Apple Watch 等移动设备上的人工智能任务,支持深度神经网络、循环神经网络、卷积神经网络、支持向量机、树集成、线性模型等。本文将带你从最初的数据处理开始教你一步一步的实现一个“霉霉”检测器,来自动从一堆手机照片中找出“霉霉”。专知内容组编辑整理。
Build a Taylor Swift detector with the TensorFlow Object Detection API, ML Engine, and Swift
by Sara Robinson

注释:本文没有用TensorFlow官方库,我用Swift构建了基于我的模型构建了应用程序。这在将来可能会改变,但Taylor对此有最终的发言权。
目前为止还没有官方swift接口的TensorFlow 库,所以我们用单纯的swift在我们模型的基础上建立预测过程的客户端程序
下图是我们应用程序APP的演示:(动图)
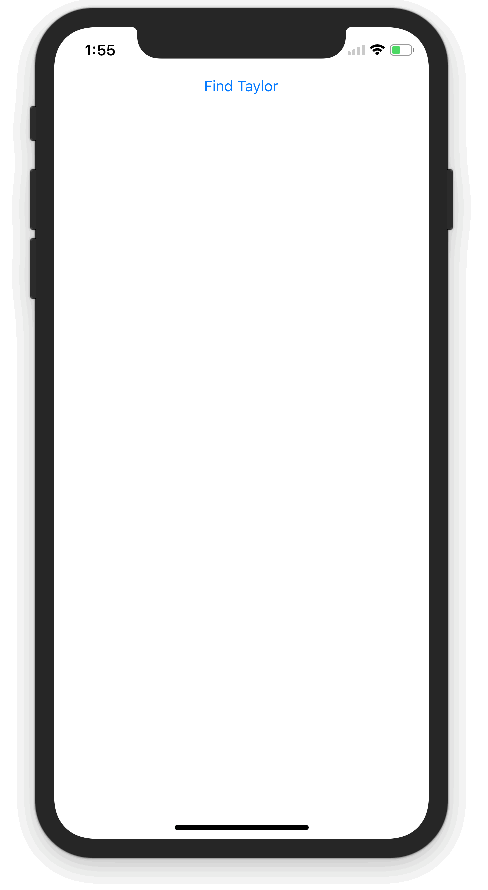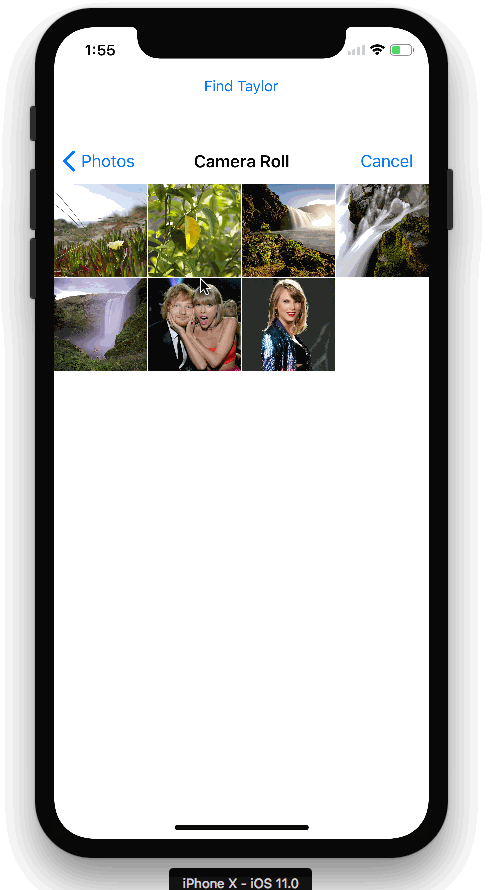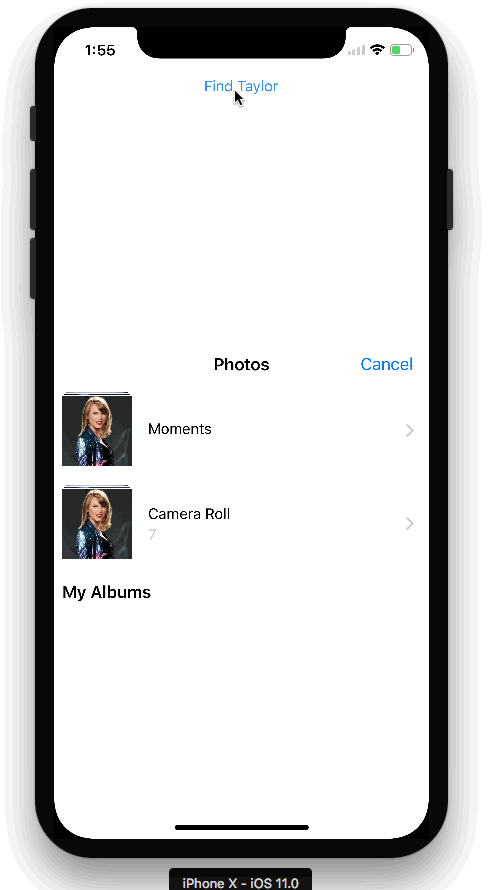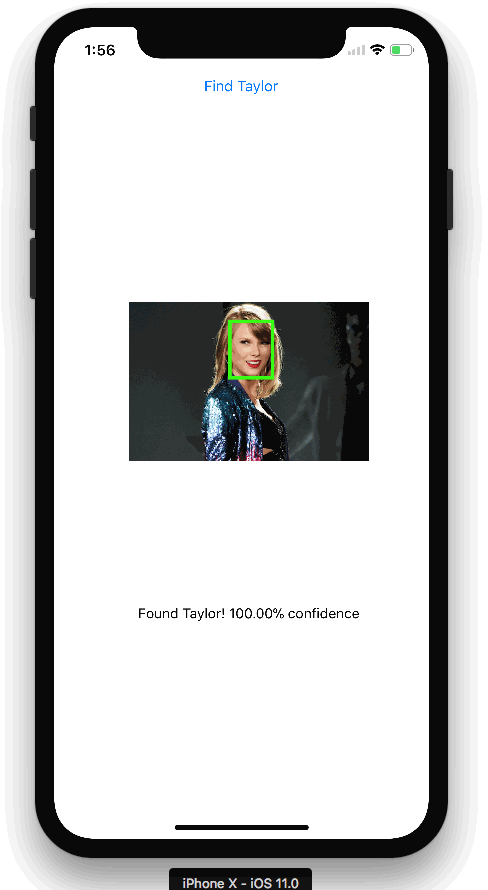
TensorFlow对象目标检测API demo可以让您识别图像中目标的位置,这可以应用到一些很酷的的应用程序中。 有时我们可能会拍摄更多人物照片而不是景物照片,所以可以用同样的技术来识别人脸。 事实证明,它同样工作得很好! 我用它来构建了上图中的Taylor Swift检测器。
在这篇文章中,我概述了从一组TSwift格式的图像到一个iOS app的建立步骤,该app在一个训练好的模型对测试图像进行预测;
1. 预训练图片:调整大小,标签,将它们分成训练和测试集,并得到Pascal VOC格式;
2. 将图像转换为TFRecords格式,从而用作API输入;
3. 在Cloud ML引擎上使用MobileNet训练模型;
4. 把训练好的模型导出,并将其部署到ML引擎中以提供服务;
5. 构建一个iOS前端,对训练过的模型做出预测请求。
用下面的架构图,说明这几部分组合在一起:
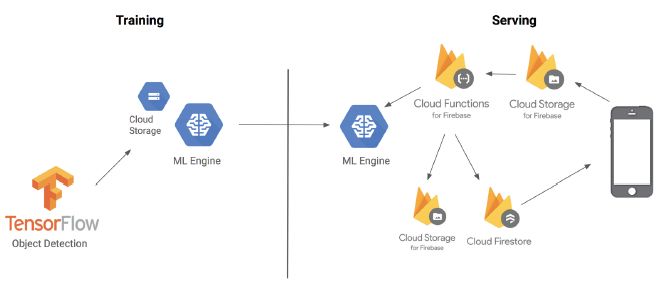
你可以直接从GitHub上找到这个项目,地址是:
https://github.com/sararob/tswift-detection
现在看来,一切似乎都很简单
在我深入讨论这些步骤之前,需要先解释一下术语:TensorFlow对象检测API是基于TensorFlow构建的框架,用于在图像中识别对象。例如,你可以用许多猫的照片来训练对象检测器,一旦训练好了你就可以输入一个待遇测的猫的图像,它会返回一个矩形列表,每个矩形中有一个猫。虽然是API,但您可以把它看作是一组用于迁移学习的方便实用的工具。
训练一个对象识别模型需要大量时间和大量的数据。对象检测中最牛的部分是它支持五种预训练的迁移学习模型。转移学习迁移学习是如何工作的?举个例子:当一个孩子在学习他们的第一语言时,他们会接触到很多例子,如果他们错认了什么,他们就会改正。例如,他们第一次识别一只猫时,他们会看到他们的父母指向猫,然后说“猫”这个词,这种重复强化了他们大脑中的认识。当他们学习如何识别狗时,孩子不需要从头开始学习。他们可以使用他们识别猫的过程,但将其应用于稍微不同的任务。这就是迁移学习的原理。
我没有时间去找到并且标记太多TSwift的图像,但是我可以利用从这些模型中提取出来的特征,通过修改最后的几层来训练数以百万计的图像,并将它们应用到我的分类任务中(检测TSwift)。
▌第一步:图像预处理
非常感谢Dat Tran,他写的一篇博文非常棒(地址:https://towardsdatascience.com/how-to-train-your-own-object-detector-with-tensorflows-object-detector-api-bec72ecfe1d9 ),博文中介绍了如何用TF对象检测训练一个浣熊探测器。我的图像标记和图像转化都follow他的博客,将图片转换为TensorFlow需要的格式。我在这里总结一下我的步骤。
第一步:从谷歌图片下载200张Taylor Swift的照片。我发现有一个Chrome扩展程序,可以下载Google种搜索的所有图片结果。 在标记图像之前,我将它们分成两个数据集:训练集和测试集。使用测试集测试模型的准确性。 根据Dat的建议,我写了一个脚本来调整图像分辨率,以确保没有任何图像宽于600像素。
由于对象检测API(Object Detection API)会输出对象在图像中的位置,因此不能将图像和标签作为训练数据传递给对象。 需要传递一个边界框(bounding box)来标识图像中的对象以及与边界框的标签(在我们的数据集中,我们只有一个标签,就是tswift)。
要生成图像的边界框,我使用了LabelImg(https://github.com/tzutalin/labelImg ),LabelImg是一个Python程序,可以让你手动给图像打标签,并返回每个图像的边界框和相关标签的XML文件。下面是它的工作原理,我定义了一个图像的边界框,并打标签tswift:
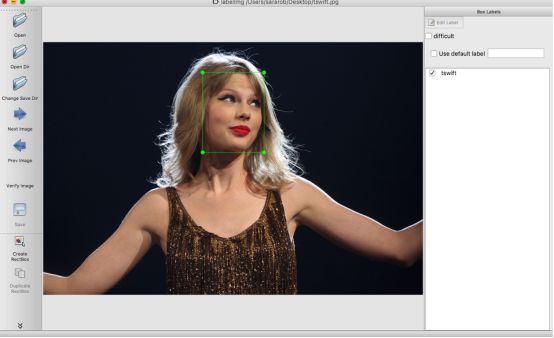
然后LabelImg自动生成一个xml文件:

现在我有一个图像,一个边界框和一个标签,但我需要将其转换为TensorFlow接受的格式 – TFRecord(这种数据的一种二进制表示)。我写了一个脚本来实现格式转换。要使用我的脚本,您需要安装tensorflow / models,从tensorflow / models / research目录运行脚本,参数传递如下(运行两次:一次用于训练数据,一次用于测试数据):
脚本:
https://github.com/sararob/tswift-detection/blob/master/convert_to_tfrecord.py

▌第二步:在云机器学习引擎上训练TSwift 探测器
我可以在我的笔记本电脑上训练这个模型,但这耗费大量的时间和资源,导致电脑不能做其他工作。 云计算就是为了解决这个问题! 我们可以利用云来进行多核训练,从而在几个小时内完成整个工作。 当我使用云机器学习引擎时,我可以利用GPU(图形处理单元)进行更快地训练。有了这种处理能力,就可以开始训练了,然后把模型训练的几个小时交给TSwift。
设置云机器学习引擎
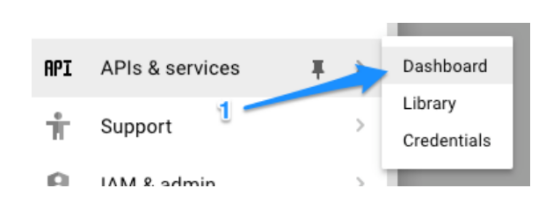
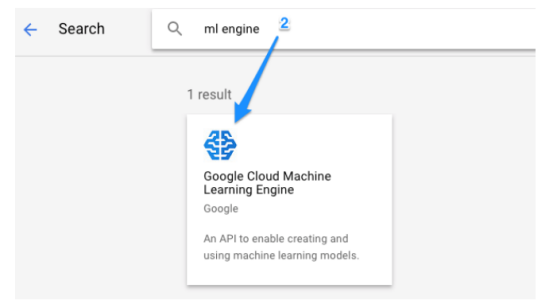
所有的数据都是TFRecord格式,我将数据上传到云端开始训练。 首先,我在Google云端控制台中创建一个项目,并开启了云机器学习引擎:
然后,我将创建一个云存储桶(Cloud Storage bucket)来打包我模型的所有资源。
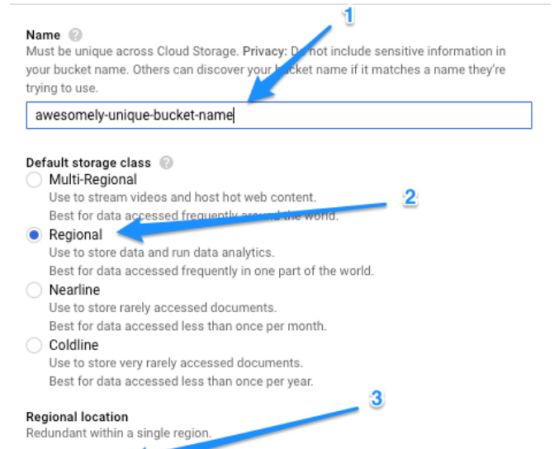
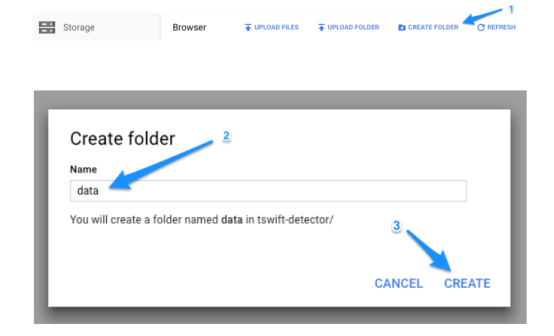
我将在这个桶中创建一个名为/ data的子目录来放置训练和测试的TFRecord文件
API还需要一个pbtxt文件将标签映射成整型的ID。 由于只有一个标签,所以该文件很小:

添加MobileNet校验文件进行进行学习
我不是从零开始训练这个模型,所以当我进行训练时,我需要使用预训练模型。 我选择使用MobileNet模型 - MobileNets是一系列针对移动优化的小模型。尽管MobileNet训练很快,并且预测更快, 但是我不会直接在移动设备上使用我的模型。 我下载了MobileNet校验文件进行训练。 校验文件是一个二进制文件,它包含了训练过程中TensorFlow模型在一些特殊点的状态。下载并解压缩校验文件后,您会看到它包含以下三个文件:
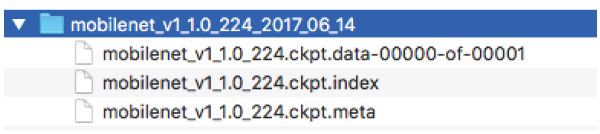
训练模型需要所有的这些文件,所以需要将它们放在我的云存储桶中的同一个data/目录下。
在进行训练工作之前,还需要补充一点。 对象检测脚本需要一个方法来绑定我们的模型校验文件,标签映射和训练数据, 我们将使用配置文件来实现。repo对五个预先训练的模型类型都有配置文件。 我在这里使用了MobileNet,并使用云存储区中的相应路径更新了所有PATH_TO_BE_CONFIGURED。 该文件除了将我的模型连接到云存储中的数据,还为我的模型配置了几个参数,例如卷积大小,激活函数和步数。
以下是开始训练之前/data云存储分区中应该存在的所有文件:
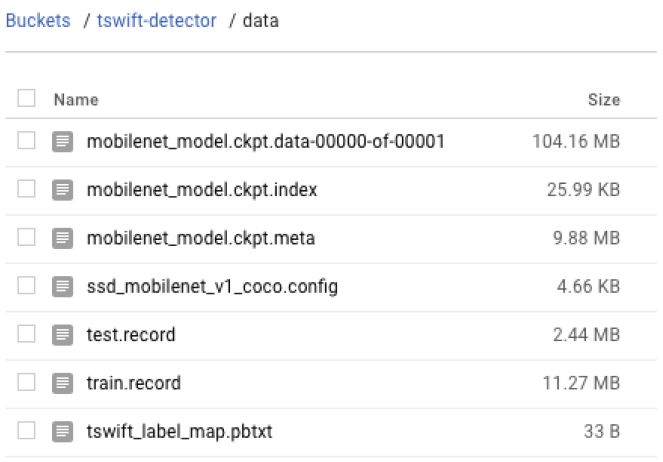
我还会在我的云存储桶中创建train /和eval /子目录 - 这是TensorFlow进行训练和评估时模型校验文件存放的地方。
现在已经准备好所有的训练文件,我可以使用gcloud命令来开始训练。 请注意,您需要在本地拷贝一份tensorcow / models / research并在该目录下运行以下的训练脚本:
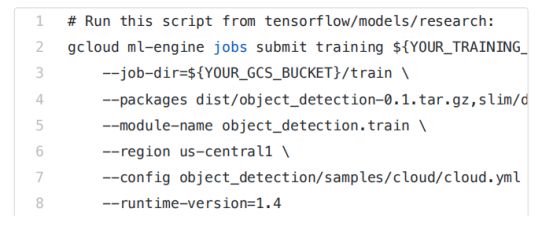
在进行训练的同时,也开始进行评估工作。 使用以前没有训练过的数据来评估我的模型的准确性:
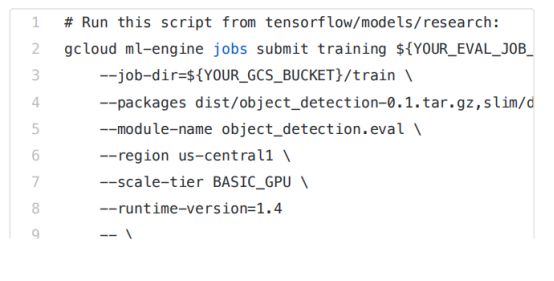
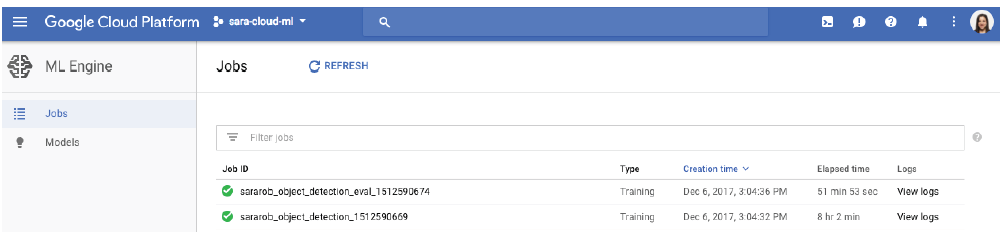
您可以通过云端控制台来浏览机器学习引擎的“作业”部分,这一部分可以验证您的作业是否运行正确,并且可以检查作业的日志。
▌第3步:部署模型进行预测
将模型部署到机器学习引擎我需要将我的模型检查点转换为ProtoBuf。 在我的训练过程中,我可以看到从几个检查点保存的文件:
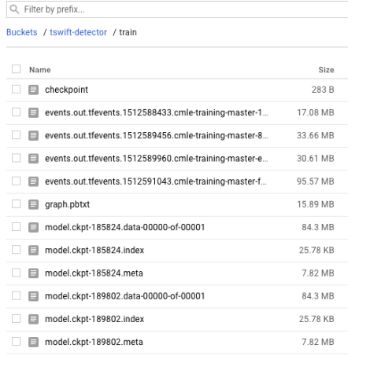
检查点文件的第一行将告诉我最新的检查点路径,我将从该检查点本地下载3个文件。每个检查点应该有一个.index,.meta和.data文件。这些保存在本地目录中,我可以使用目标检测手动脚本export_inference_graph将它们转换为ProtoBuf。要运行下面的脚本,您需要在MobileNet配置文件添加本地路径,你需要从训练任务中下载模型检查点的编号,以及要导出的图形的目录名称:
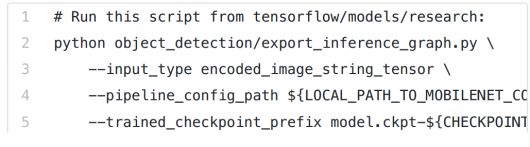
这个脚本运行后,你应该在你的.pb输出目录里面看到一个saved_model 目录。上传saved_model.pb ble(不要担心其它生成的文件)到你云存储下/ data目录中。
现在您已经准备好将模型部署到机器学习引擎上进行服务。首先,使用gcloud命令创建你的模型:

然后通过将模型指向刚刚上传到云存储的已保存模型ProtoBuf来创建模型的第一个版本:

一旦模型部署完成,就可以使用机器学习引擎的在线预测API来预测新图像。
▌第4步:使用Firebase和Swift构建预测客户端
我在Swift中编写了一个iOS客户端来对我的模型进行预测请求(因为为什么不用其他语言编写TSwift检测器?)Swift客户端将图像上传到云存储,这会触发Firebase,在Node.js中发出预测请求,并将生成的预测图像和数据保存到云存储和Firestore中。
首先,在我的Swift客户端中,我添加了一个按钮,供用户访问设备照片库。用户选择照片后,会自动将图像上载到云端存储:

接下来,我编写了上传到我的项目的云存储触发的Firebase数据库。它把图像进行64位编码,并发送到机器学习引擎进行预测。你可以在这里找到完整功能的代码。下面是我向机器学习引擎预测API发出请求的函数部分。
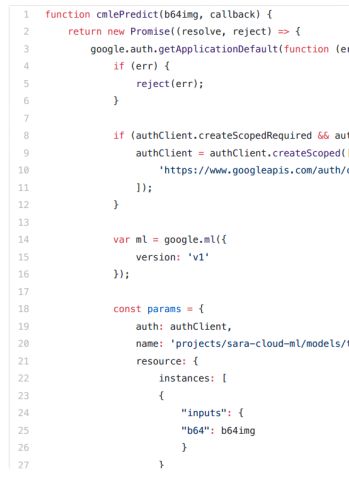
在机器学习响应中,我们得到:
detection_box来定义TSwift周围的边界框(如果她在图像中检测到的话)
detection_scores为每个检测框返回一个分数值。我将分数高于70%的检测认为是正确的。
detection_classes告诉我们与检测相关的标签ID。在我的实验中,因为只有一个标签,它总是1
在函数中,如果检测到Taylor,则使用detection_boxes在图像上绘制一个框,并给出判断分数。将带有新框的图像保存到云存储,然后将图像的文件路径写入Cloud Firestore,以便在iOS应用程序中读取路径并下载新图像(使用矩形):

最后,在我的iOS应用程序中,可以监听图像Firestore路径的更新。如果检测到,我会下载图像,并与检测分数一起显示在应用程序中。这个函数将替换上面第一个Swift代码片段中的注释:
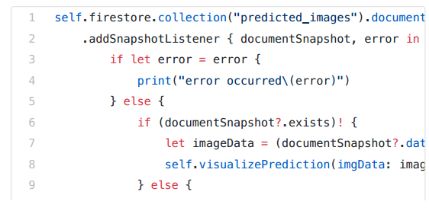
我们有一个Taylor Swift检测器。这里的重点不是准确性(因为我的训练集中只有140张图像),所以模型错误地识别了一些可能会误认为tswift的人的图像。但是,我会花时间来标识更多的图片,我将更新模型,并在应用程序商店发布应用程序:)
▌下一步是什么?
这篇文章涵盖了很多信息。要想自己构建这个系统? 可参考下面步骤:
预处理数据:我遵循Dat的博客文章,使用LabelImg来处理标签图像,并生成边框数据的xml文件。 然后我写了一个脚本来将标记的图像转换为TFRecords。
脚本:
https://github.com/sararob/tswift-detection/blob/master/convert_to_tfrecord.py
训练和评估目标检测模型:使用本博客的方法,我将训练和测试数据上传到云存储,并使用机器学习引擎进行训练和评估。
将模型部署到机器学习引擎:我使用gcloud CLI将我的模型部署到机器学习引擎
我的模型:https://cloud.google.com/ml-engine/docs/deploying-models。
预测请求:我使用Firebase SDK for Cloud功能向我的机器学习引擎模型发出在线预测请求。此请求是由我的Swift应用上传到Firebase存储触发的。在我的函数中,我向Firestore写预测元数据。
参考链接:
https://towardsdatascience.com/build-a-taylor-swift-detector-with-the-tensorflow-object-detection-api-ml-engine-and-swift-82707f5b4a56
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

点击“阅读原文”,使用专知!
展开全文



