【论文笔记】自注意力机制学习句子embedding
【导读】这篇发表在ICLR 2017的文章,提出了一种基于 self-attention 学习 sentence embedding 的监督学习方法。该文章使用 matrix 来表示 sentence embedding, 保留了句子的多种特征, 一个行向量表示一种特征. 缓解行向量的冗余问题。并在author profiling、sentiment classification以及texual entailment任务上做了实验。
【ICLR 2017 论文】
A Structured Self-attentive Sentence Embedding

本文提出了一种基于 self-attention 学习 sentence embedding 的监督学习方法. 使用 matrix 来表示 sentence embedding, 保留了句子的多种特征, 一个行向量表示一种特征. 为缓解行向量的冗余问题 (即行向量之间太相似, 只学到重复特征), 文中引入了一个鼓励行向量学习不同特征的惩罚项.
Key Points
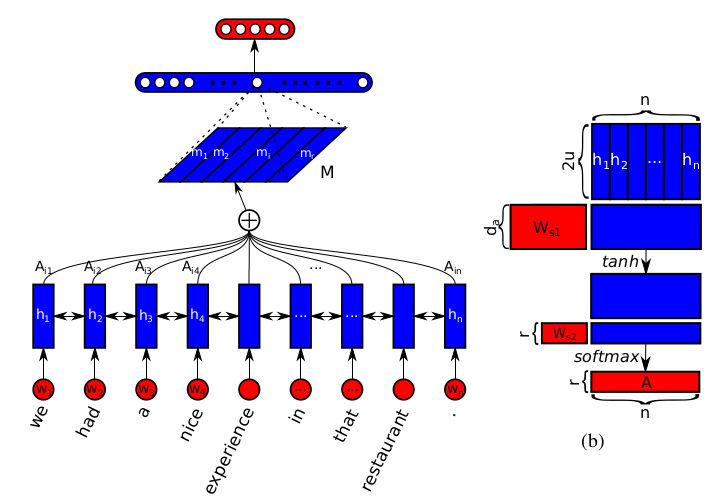
句子的向量表示往往只关注句子的一个特定成分, 比如相关的词或词组, 从而只学到一种特征. 据此, 本文提出用矩阵来表示句子, 充分考虑句子的不同成分 (词, 词组, 分句等), 从而保留句子的不同特征. 用一个行向量表示一种特征:
文中用
来计算 attention matrix. 其中, H 是 LSTM 状态向量构成的矩阵,
和
是要学习的权值参数矩阵. 如果将
通过
, 就得到了 sentence embedding matrix.
由于
embedding matrix 存在冗余的问题, 即学到的 embedding vector 之间过分相似, 实际只学到了少量几种特征. 为此, 文章引入了一项惩罚:
用
来度量冗余程度. 其中 I 是单位矩阵,
是 Frobenius 范数:
因此, 减小 P 将鼓励
向零阵看齐. 由于减了一个单位矩阵, 随着学习,
的对角元素将接近于 1. 按文中的说法, 这将使得每一个 attention vector 尽可能专注于一种成分, 即一种特征, 同时不同 attention vector 又尽可能不同.
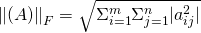
使用矩阵表示句子带来了一个问题, attention layer 的后接 FC (全连阶层) 将变得很臃肿. 事实上, 文中使用的模型, 90% 的参数都集中在这个 FC 上, 设 M 的大小为 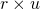
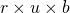
文中根据矩阵的二维特点, 提出了一种 weight pruning method. 具体地, 将 M 按行映射为 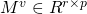
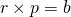
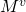
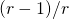
Notes/Questions
embedding matrix 的想法很具有创新性, 让人眼前一亮.
除了 weight pruning 部分, 模型不复杂, 就是 Bi-LSTM + self-attention mechanism.
从考察 M 的行数对模型性能的影响的实验来看, 当行数取 1, 即 embedding matrix 退化为 embedding vector, 模型的性能有明显下降, 和 baselines 处于同一级别. 很难说文中提出的模型的性能提升来自 self-attention mechanism 还是 embedding matrix. 怕是 embedding matrix 更多一些, 感觉这是变相的 ensemble, 于 Dropout 异曲同工吧.
模型对于 sentence representation 的学习是依赖于具体的 NLP 任务的监督学习方法.
在惩罚项部分, 文章考虑过 KL 散度, 放弃的原因可以借鉴:
对于 A, 面临的是最大化不同 attention vector 之间的 KL 散度集的问题. A 中大量的零值使得训练不稳定;
作者希望 A 的每一行专注于句子的一种特征, 这是 KL 散度无法提供的.
个人感觉, 文章附录部分写得很难懂, 而且使用的符号和正文不一致.
的依据,
本文经授权转载自赵喧典:kissg_mp,点击“阅读原文”可查阅原文。
更多教程资料请访问:专知AI会员计划
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取

[点击上面图片加入会员]
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知
展开全文



