【干货】用PyTorch进行RNN语言建模 - Packed Batching和Tied Weight
【导读】PyTorch是一个日益流行的神经网络框架,自然支持RNN。但是关于RNN,Pytorch的官方教程描述的不怎么详细,这篇文章将介绍使用Pytorch实现权值绑定、对词嵌入向量进行Packed Sequence batching,及展示Pytorch的RNN可扩展性,最后也介绍了自己对PyTorch实现循环神经网络功能的一些优缺点的阐述。
作者 | Florijan Stamenković
编译 | 专知
翻译 | Yingying, Huaiwen
RNN Language Modelling with PyTorch — Packed Batching and Tied Weights
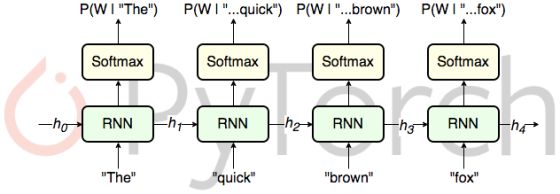
语言模型
语言模型是文本生成系统的关键部分。它们用于图像标注,语音转换为文本,机器翻译,情感分析等。它们对单词序列出现的概率进行建模。例如,“Fine weather today”这个单词序列的可能性比“walk. pair REd ”可能性高。
循环神经网络(RNN)
如果你对RNN不是很了解,请先看看关于它的介绍,这是一个很好的入门教程:http://karpathy.github.io/2015/05/21/rnn-effectiveness/。使用RNN进行自然语言建模是一种非常常见的方法。
上下文
语言模型的常用数据集是WikiText:https://einstein.ai/research/the-wikitext-long-term-dependency-language-modeling-dataset,它由维基百科文章建模而成。在本文中,将使用包含大约250万字的WikiText-2版本。
本文所有代码链接:
https://github.com/florijanstamenkovic/PytorchRnnLM
词嵌入绑定权值
在基于神经网络的语言模型(NNLM)中,每个单词被编码为维度为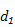
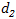
Press和Wolf于2016年提出了输入和输出嵌入绑定的想法。如果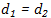
在PyTorch中绑定嵌入
使用pytorch.nn.Embedding类在PyTorch中使用词嵌入非常简单,可以参考这个教程(https://pytorch.org/tutorials/beginner/nlp/wordembeddingstutorial.html)。
那么,如何使用绑定权重?有两种方法:使用torch.nn.Embedding或torch.nn.Linear。
使用torch.nn.Embedding类绑定权重
如果你使用torch.nn.Embedding,请注意它的重量初始化策略。它用具有零均值和单位方差的正态分布初始化权重。一般来说,这对于完全连接的层(例如softmax激活层)来说不是一个好的初始化策略。出于这个原因,一些初始化技巧是必要的:
# custom weight init in torch.nn.Embedding
emb_w = torch.Tensor(V, d)
stdv = 1. / math.sqrt(emb_w.size(1)) # like in nn.Linear
emb_w.uniform_(-stdv, stdv)
embedding = nn.Embedding(vocab_size, embedding_dim,
_weight=emb_w)
# use it as an embedding layer
word_inds = torch.tensor([3,1,7])
word_vecs = embedding(word_vecs)
# use it for softmax
out = preious_layers(word_vecs).mm(s.embedding.weight.t()) + out_b
请注意,embedding权重必须从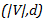
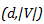
使用torch.nn.Linear绑定权重
使用绑定权重的另一种方法是使用torch.nn.Linear:
fc = nn.Linear(d, V)
# here's how to treat it as an embedding layer
word_inds = torch.tensor([3,1,7])
word_vecs = fc.weight.index_select(0, word_inds)
# standard usage for output activation
out = fc(preious_layers(word_vecs))
使用这种方法,你会失去一些nn.Embedding的附加功能,但总的来说代码更简单。当将它们用于输入嵌入时,不需要转置fc权重,因为使用nn.Linear要求保持向量的形状与输入的构造参数匹配。
Batching with Embeddings and PackedSequence
语言模型的单个训练序列是一个句子,但是要记住句子的长度是不一样的。
与此同时,神经网络通常会分批进行培训,因为这既能稳定梯度,又能大大提高现代硬件(GPU)的训练吞吐量。在一个简单的PyTorch实验中,我使用小型RNN进行批量训练时,吞吐量增加了10倍。当然,这取决于网络,数据集等。就我所知,批量化RNN训练在PyTorch教程中没有解释,但是有很好的库支持。详见https://pytorch.org/docs/stable/nn.html#utilities。
那么,我们如何才能将长度不一样的序列放到一个batch里训练呢?
填充
这个问题的一个常见解决方案是将句子拆分/修剪到某个最大长度和/或填充较短的句子,使它们的长度一致。这种方法有几个问题:
• 分割/裁剪句子会导致上下文和数据丢失。
• 填充在前向传播中增加无用的开销。
• 必须从损失计算中删除填充以将其从backprop中排除,这是乏味且笨拙的。
• 一切都需要更多的内存。
如果考虑WikiText-2数据集中的句子长度,所有这些都会特别糟糕:
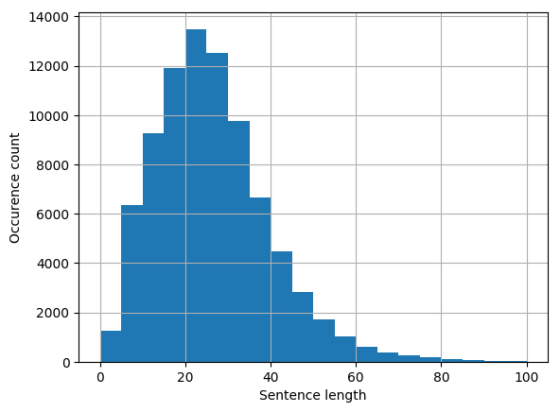
有其他选择吗?有!
打包
我们可以将所有序列打包到一个单独的向量中,而不是填充在矩阵中保留可变长度的句子。为了确保句子仍然可以独立处理,必须保留关于它们长度的信息。所有这些都通过PyTorch的torch.nn.utils.rnn.PackedSequence和非常方便地处理。更酷的是,PackedSequence可以直接送入PyTorch的RNN层!这在API规范中有详细记录(https://pytorch.org/docs/stable/nn.html#recurrent-layers),但在教程中搜索相关关键字不会产生任何结果。
打包和词嵌入
官方网页或第三方教程中没有如何将PackedSequence函数与词嵌入结合起来,并且不使用填充(padding)作为中间格式的解释。它是这样工作的:
为句子创建一个PackedSequence(单词标记)。
将PackedSequence.data转换为嵌入的vecs。
从结果和旧的序列长度构建一个新的PackedSequence。这不是由API正式支持的。
将生成的PackedSequence传递到网络的循环层。
这很简单,我的猜测是步骤3中不支持的原因是它不常用。但我更喜欢这个解决方案,因为它更简单,避免了使用padding作为中间的格式。这适用于当前稳定版本的PyTorch(0.4.0)。
import torch
import torch.nn as nn
# A list of sentences, each being a list of tokens.
sents = [[4, 545, 23, 1], [34, 84], [23, 6, 774]]
# Embedding for 10k words with d=128
emb = nn.Embedding(1000, 128)
# When packing a sequence it has to be sorted on length.
sents.sort(key=len, reverse=True)
packed = nn.utils.rnn.pack_sequence(
[torch.tensor(s) for s in sents])
embedded = nn.utils.rnn.PackedSequence(
emb(packed.data), packed.batch_sizes)
# An LSTM
lstm_layer = nn.LSTM(128, 128)
output = lstm_layer(embedded)
# Output is a PackedSequence too
定制神经元,分批和打包
在基于RNN的研究中,以某种方式修改循环单元的行为是相当常见的。 它可以是修改内部状态工作方式(它产生了LSTM,GRU等),也可以是用于增加注意力等。在PyTorch中,这些都很容易实现,就像RNN教程汇总写到的那样。但是,没有涉及batching。 在自定义循环单元时,我们是否可以轻松进行批处理,也可以使用文字嵌入?
RNN教程汇总:
https://pytorch.org/tutorials/intermediate/charrnnclassification_tutorial.html
看看PyTorch中的RNN层,我们可以看到有RNN,LSTM和GRU类,还有RNNCell,LSTMCell和GRUCell类。 这可能意味着有一个RNNbase的基类,其他变体都是继承并且做一些改变得到。
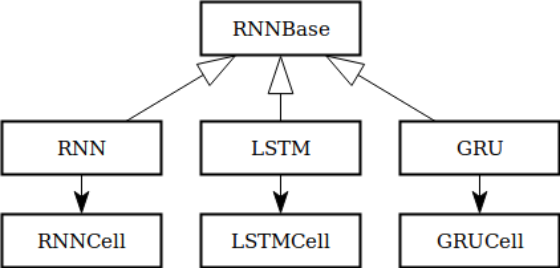
通过查看源代码,可以发现事实和我们猜的差不多。 这反过来意味着我们可以轻松地定制循环单元并继承RNNBase,例如批处理和打包序列处理功能,这将非常棒。
不幸的是,它似乎并不是这样工作的。 RNN,LSTM和GRU子类不是包含单元成员和/或将它传递给RNNBase的构造函数,而是传递一个字符串作为模式参数。 基于模式,RNNBase分配参数空间(来自下面粘贴的RNNBase的PyTorch码)并执行其他初始化。
源代码链接:
https://pytorch.org/docs/stable/_modules/torch/nn/modules/rnn.html#RNN
if mode == 'LSTM':
gate_size = 4 * hidden_size
elif mode == 'GRU':
gate_size = 3 * hidden_size
else:
gate_size = hidden_size
这不仅会阻止我们重用RNNBase类,而且看起来很糟糕。 这可能是有道理的,我对PyTorch的代码库没有足够的知识来来批评,我只是说它看起来不对。
因此,目前看起来似乎没有一种简单的方法将自定义循环单元插入PyTorch的RNN。
结论
总结如何使用PyTorch的循环神经网络功能感觉如下:
优点:
• 使用基本的RNN很简单。
• 文字嵌入很容易。
• 创建定制RNN并且一次一个一个地进行训练很容易。
• RNN层支持批处理。
• 支持打包(Packing),并且有很酷的实用程序。
不太好的:
• 分批处理(batching)和打包(packing)在教程中没有解释。
• 如果使用不受支持的API,将包装与词嵌入结合起来很容易。
• RNN代码的可扩展性不是很好。
总体而言,尽管存在缺陷,但我仍然很喜欢PyTorch的RNN部分。 PyTorch提供了一些开箱即用的强大功能,并且易于使用。文档似乎略微偏向于神经网络技术,而不是表达API的功能,但这并不总是一件坏事。扩展性通常很好(PyTorch的动态backprop的灵活性非常好),但也有缺点。稳定的API仍然在0.4版本中是有道理的。
Pytorch的官方教程:
https://pytorch.org/tutorials/intermediate/charrnnclassification_tutorial.html
代码链接:
https://github.com/florijanstamenkovic/PytorchRnnLM
原文链接:
https://medium.com/@florijan.stamenkovic_99541/rnn-language-modelling-with-pytorch-packed-batching-and-tied-weights-9d8952db35a9
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取。欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知
展开全文



