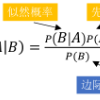
Understanding the sociodemographic composition of online platforms is essential for accurately interpreting digital behavior and its societal implications. Yet, current methods often lack the transparency and reliability required, risking misrepresenting social identities and distorting our understanding of digital society. Here, we introduce a principled framework for sociodemographic inference on Reddit that leverages over 850,000 user self-declarations of age, gender, and partisan affiliation. By training models on sparse user activity signals from this extensive, self-disclosed dataset, we demonstrate that simple probabilistic models, such as Naive Bayes, outperform more complex embedding-based alternatives. Our approach improves classification performance over the state of the art by up to 19% in ROC AUC and maintains quantification error below 15%. The models produce well-calibrated and interpretable outputs, enabling uncertainty estimation and subreddit-level feature importance analysis. More broadly, this work advocates for a shift toward more ethical and transparent computational social science by grounding sociodemographic analysis in user-provided data rather than researcher assumptions.
翻译:理解在线平台的社会人口构成对于准确解读数字行为及其社会影响至关重要。然而,现有方法通常缺乏所需的透明度与可靠性,可能导致社会身份表征失真并扭曲我们对数字社会的认知。本文提出一种基于原则的Reddit社会人口属性推断框架,该框架利用了超过85万条用户自我声明的年龄、性别及党派归属数据。通过在此大规模自披露数据集上训练基于稀疏用户活动信号的模型,我们证明简单概率模型(如朴素贝叶斯分类器)的性能优于更复杂的基于嵌入的方法。我们的方法将分类性能在ROC AUC指标上较现有最佳水平提升达19%,并将量化误差控制在15%以下。模型生成经过良好校准且可解释的输出,支持不确定性估计及子论坛层面的特征重要性分析。更广泛而言,本研究主张通过将社会人口分析建立在用户提供数据而非研究者假设的基础上,推动计算社会科学向更符合伦理且透明的方向演进。