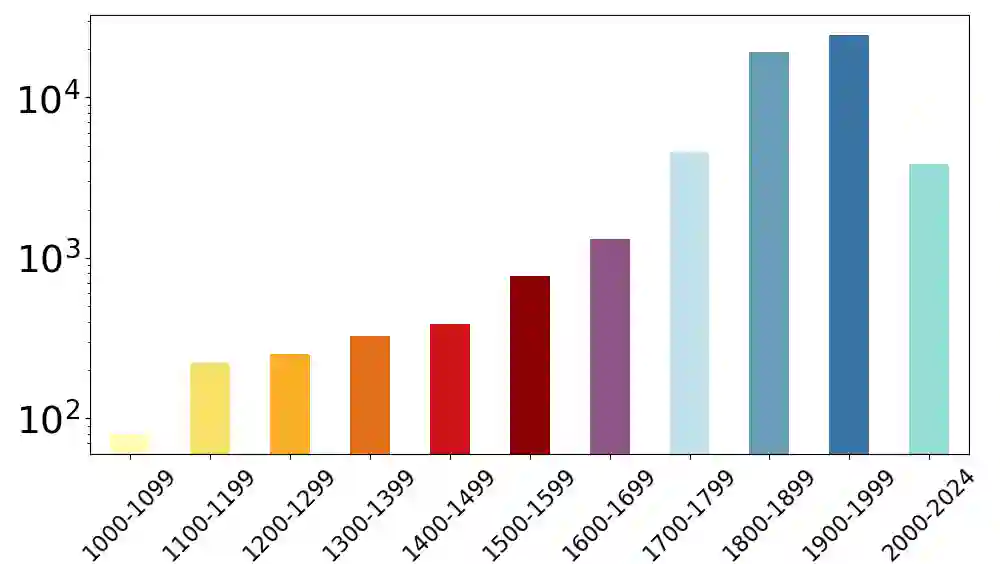
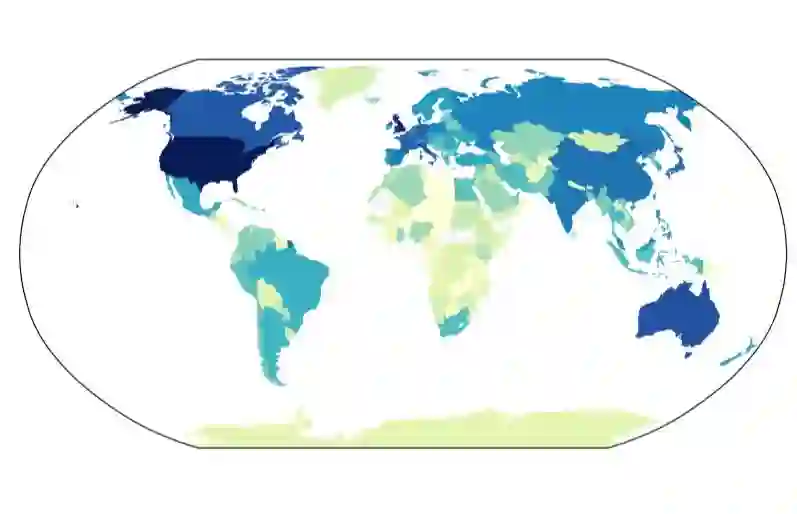
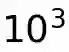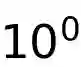We expose a significant popularity bias in state-of-the-art vision-language models (VLMs), which achieve up to 34% higher accuracy on famous buildings compared to ordinary ones, indicating a reliance on memorization over generalizable understanding. To systematically investigate this, we introduce the largest open benchmark for this task: the YearGuessr dataset, a collection of 55,546 building images with multi-modal attributes from 157 countries, annotated with continuous ordinal labels of their construction year (1001-2024), GPS data, and page-view counts as a proxy for popularity. Using this dataset, we frame the construction year prediction task as ordinal regression and introduce popularity-aware interval accuracy metrics to quantify this bias. Our resulting benchmark of 30+ models, including our YearCLIP model, confirms that VLMs excel on popular, memorized items but struggle significantly with unrecognized subjects, exposing a critical flaw in their reasoning capabilities. Project page: https://sytwu.github.io/BeyondMemo/
翻译:我们揭示了当前最先进的视觉-语言模型存在显著的流行度偏差:与普通建筑相比,模型在著名建筑上的准确率最高可高出34%,这表明其依赖于记忆而非可泛化的理解。为系统研究此问题,我们为此任务引入了最大的开放基准:YearGuessr数据集。该数据集包含来自157个国家的55,546张建筑图像,具备多模态属性,并标注了其建造年份的连续序数标签(1001-2024年)、GPS数据以及作为流行度代理的页面浏览量。利用此数据集,我们将建造年份预测任务构建为序数回归问题,并引入了考虑流行度的区间准确率指标以量化此偏差。我们对30多个模型(包括我们提出的YearCLIP模型)的基准测试结果证实,视觉-语言模型在流行、被记忆的项目上表现出色,但在未被识别的主题上表现显著不佳,这暴露了其推理能力中的一个关键缺陷。项目页面:https://sytwu.github.io/BeyondMemo/