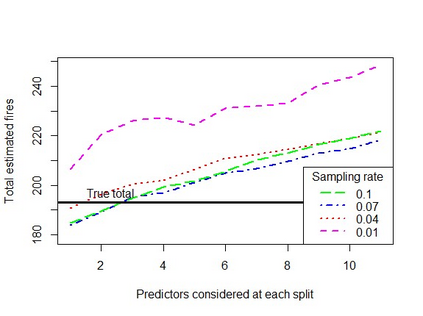
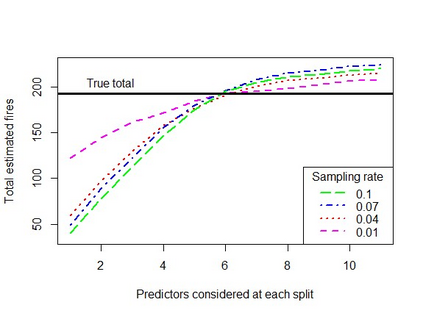
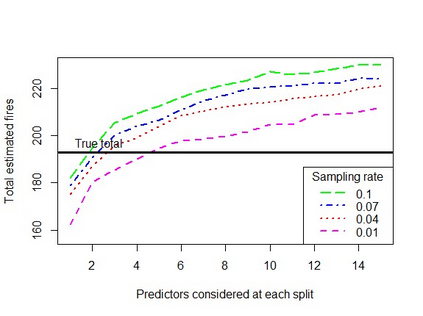
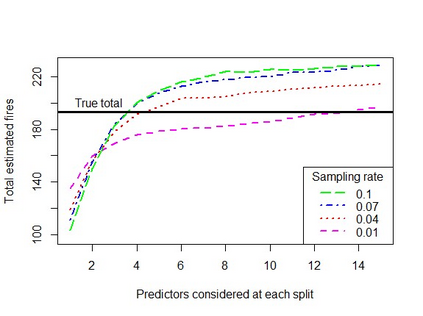
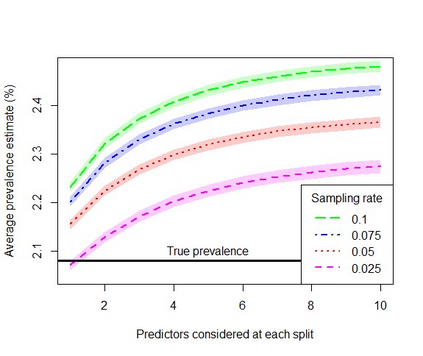
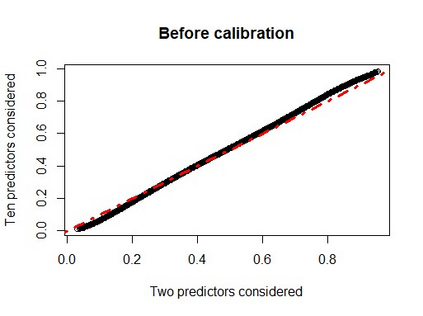
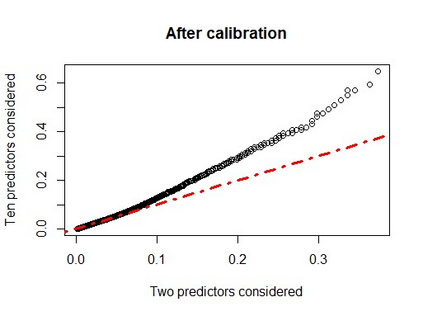
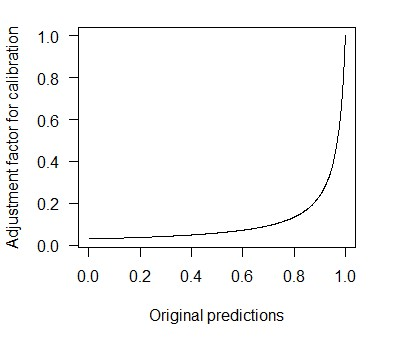
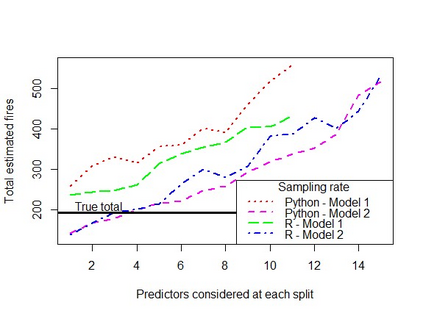
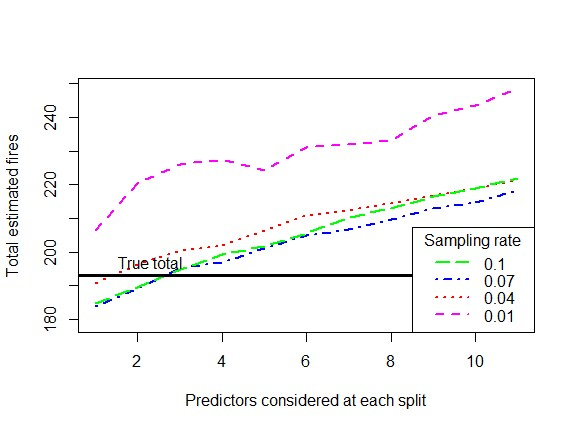
When using machine learning for imbalanced binary classification problems, it is common to subsample the majority class to create a (more) balanced training dataset. This biases the model's predictions because the model learns from data whose data generating process differs from new data. One way of accounting for this bias is analytically mapping the resulting predictions to new values based on the sampling rate for the majority class. We show that calibrating a random forest this way has negative consequences, including prevalence estimates that depend on both the number of predictors considered at each split in the random forest and the sampling rate used. We explain the former using known properties of random forests and analytical calibration. Through investigating the latter issue, we made a surprising discovery - contrary to the widespread belief that decision trees are biased towards the majority class, they actually can be biased towards the minority class.
翻译:在机器学习处理不平衡二分类问题时,通常会对多数类进行子采样以创建(更为)平衡的训练数据集。这种做法会引入模型预测偏差,因为模型学习的数据生成过程与新数据存在差异。校正此偏差的一种方法是通过基于多数类采样率的解析映射,将所得预测值转换为新值。本文证明,以此方式校准随机森林会产生负面后果,包括流行率估计同时依赖于随机森林中每次分裂时考虑的预测变量数量和所使用的采样率。我们利用随机森林的已知特性与解析校准解释了前者。通过探究后者问题,我们得出了一个令人惊讶的发现——与普遍认为决策树偏向多数类的观点相反,它们实际上可能偏向少数类。