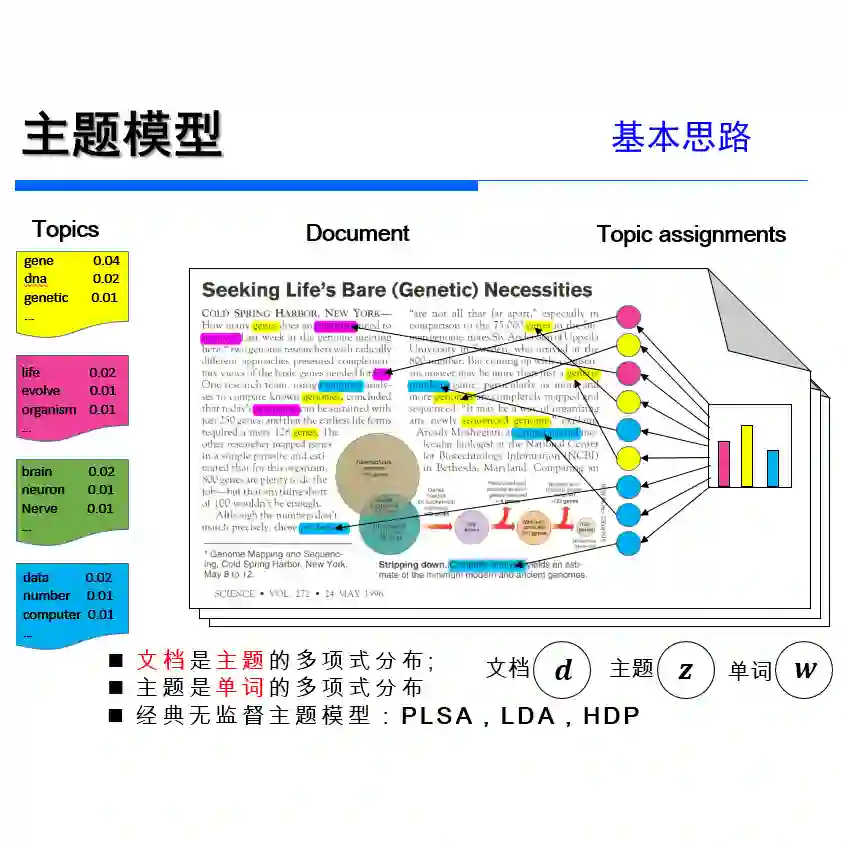
Social scientists employ latent Dirichlet allocation (LDA) to find highly specific topics in large corpora, but they often struggle in this task because (1) LDA, in general, takes a significant amount of time to fit on large corpora; (2) unsupervised LDA fragments topics into sub-topics in short documents; (3) semi-supervised LDA fails to identify specific topics defined using seed words. To solve these problems, I have developed a new topic model called distributed asymmetric allocation (DAA) that integrates multiple algorithms for efficiently identifying sentences about important topics in large corpora. I evaluate the ability of DAA to identify politically important topics by fitting it to the transcripts of speeches at the United Nations General Assembly between 1991 and 2017. The results show that DAA can classify sentences significantly more accurately and quickly than LDA thanks to the new algorithms. More generally, the results demonstrate that it is important for social scientists to optimize Dirichlet priors of LDA to perform content analysis accurately.
翻译:社会科学家常采用潜在狄利克雷分配(LDA)从大型语料库中识别高度特定的主题,但这一任务往往面临以下挑战:(1) LDA 在处理大规模语料时通常需要极长的拟合时间;(2) 无监督 LDA 在短文本中会将主题碎片化为子主题;(3) 半监督 LDA 难以通过种子词准确定义特定主题。为解决这些问题,本文提出一种名为分布式非对称分配(DAA)的新型主题模型,该模型融合了多种算法,可高效识别大型语料库中涉及重要主题的句子。通过将 DAA 应用于 1991 年至 2017 年联合国大会演讲转录文本,评估其识别政治重要主题的能力。实验结果表明,得益于新算法的设计,DAA 在句子分类的准确性与速度上均显著优于 LDA。更广泛而言,本研究证明社会科学家需要优化 LDA 的狄利克雷先验参数才能实现精确的内容分析。