成为VIP会员查看完整内容
VIP会员码认证
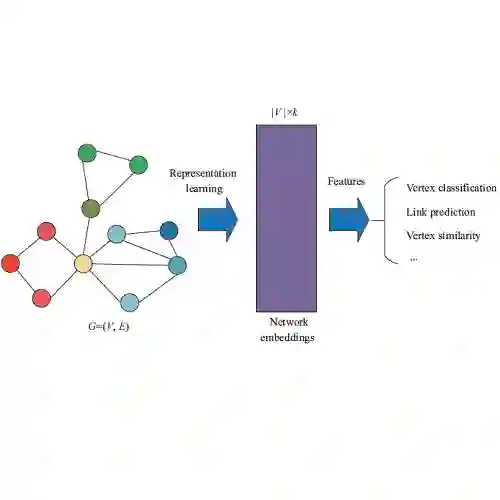
Network Embedding
基础入门
- DeepWalk:社会表征的在线学习 —Shintaku
s Blog[https://www.shintaku.cc/posts/deepwalk/] - 网络表示学习综述 - 涂存超, 杨成, 刘知远 孙茂松 [http://nlp.csai.tsinghua.edu.cn/~lzy/publications/sc2017_nrl.pdf]
中英文综述
- A Comprehensive Survey of Graph Embedding: Problems, Techniques and Applications. Hongyun Cai, Vincent W. Zheng, Kevin Chen-Chuan Chang 2017 [https://arxiv.org/abs/1709.07604]
- Representation Learning on Graphs: Methods and Applications. William L. Hamilton, Rex Ying, Jure Leskovec2017. [https://arxiv.org/abs/1709.05584]
- Graph Embedding Techniques, Applications, and Performance: A Survey. Palash Goyal, Emilio Ferrara 2017 [https://arxiv.org/abs/1705.02801]
- 网络表示学习综述 - 涂存超, 杨成, 刘知远 孙茂松 [http://nlp.csai.tsinghua.edu.cn/~lzy/publications/sc2017_nrl.pdf]
进阶论文
- DeepWalk: Online Learning of Social Representations. Bryan Perozzi, Rami Al-Rfou, Steven Skiena. DeepWalk是KDD 2014的一篇文章,彼时word2vec在文本上的成功应用掀起来一波向量化的浪潮,word2vec是根据词的共现关系,将词映射到低维向量,并保留了语料中丰富的信息。DeepWalk算法思路其实很简单,对图从一个节点开始使用random walk来生成类似文本的序列数据,然后将节点id作为一个个「词」使用skip gram训练得到「词向量」。思路虽然简单,背后是有一定道理的,后面一些工作有证明这样做其实等价于特殊矩阵分解(Matrix Factorization)。而DeepWalk本身也启发了后续的一系列工作。 [https://arxiv.org/pdf/1403.6652.pdf]
- Jian Tang, Meng Qu, Mingzhe Wang, Ming Zhang, Jun Yan and Qiaozhu Mei. LINE: Large-scale Information Network Embedding. In WWW'15. (Most cited paper of WWW'15) LINE分析了1st order proximity和2nd order proximity,其中一度相似性就是两个点直接相连,且边权重越大说明两个点越相似;而二度相似性则是两个点之间共享了很多邻居,则它们的相似性就很高。文章中非常简单的方式构造了一个目标函数,能同时保留二者的信息。以一度相似性为例,节点i和j相连的经验概率就是和归一化后的权重,即,而通过向量计算这个概率值是目标函数就是让这两个分布距离最小,选择KL散度作为距离衡量函数就得到了最后的损失函数。 [https://arxiv.org/pdf/1503.03578.pdf]
- Aditya Grover, Jure Leskovec. node2vec: Scalable Feature Learning for Networks. KDD 2016 node2vec在DeepWalk的基础上,定义了一个bias random walk的策略生成序列,仍然用skip gram去训练。论文分析了BFS和DFS两种游走方式,保留的网络结构信息是不一样的。 DeepWalk中根据边的权重进行随机游走,而node2vec加了一个权重调整参数α:t是上一个节点,v是最新节点,x是候选下一个节点。d(t,x)是t到候选节点的最小跳数。 通过不同的p和q参数设置,来达到保留不同信息的目的。当p和q都是1.0的时候,它等价于DeepWalk。 [http://www.kdd.org/kdd2016/papers/files/rfp0218-groverA.pdf]
- Cunchao Tu, Weicheng Zhang, Zhiyuan Liu, Maosong Sun, Max-Margin DeepWalk: Discriminative Learning of Network Representation. IJCAI 2016 DeepWalk本身是无监督的,如果能够引入label数据,生成的向量对于分类任务会有更好的作用。 DeepWalk实际上是对于一个特殊矩阵M的分解, 这篇文章将DeepWalk和Max-Margin(SVM)结合起来,从损失函数看是这两部分组成:(1)训练的时候是分开优化,固定x,y优化w和,其实就是multi class 的 SVM。(2)固定w和优化x,y的时候稍微特殊一点,算了一个biased Gradient,因为损失函数里有x和w的组合。 这样在训练中同时优化discrimination和representation两部分, 达到一个好的效果。 [http://thunlp.org/~tcc/publications/ijcai2016_mmdw.pdf]
- Shaosheng Cao, Wei Lu, Qiongkai Xu GraRep: Learning Graph Representations with Global Structural Information. CIKM 2015 沿用矩阵分解的思路,分析了不同k-step(random walk中的步数)所刻画的信息是不一样的. 所以可以对每一个step的矩阵作分解,最后将每个步骤得到的向量表示拼接起来最为最后的结果。 [https://www.researchgate.net/publication/301417811_GraRep]
- Cheng Yang, Zhiyuan Liu, Deli Zhao, Maosong Sun, Edward Y. Chang. Network Representation Learning with Rich Text Information. IJCAI 2015 TADW在对节点embedding时考虑文本信息。文章里有DeepWark等同于M的矩阵分解的简单证明,而在实际中,一些节点上旺旺会有文本信息,所以在矩阵分解这个框架中,将文本直接以一个子矩阵的方式加入,会使学到的向量包含更丰富的信息。 [http://thunlp.org/~yangcheng/publications/ijcai15.pdf]
- Cunchao Tu, Han Liu, Zhiyuan Liu, Maosong Sun. CANE: Context-Aware Network Embedding for Relation Modeling ACL 2017 CANE也是加文本信息也就是Context-Aware,利用节点的在边上共现信息构建了一个Siamese网络。在这个网络引入了Attention机制,之后通过计算该节点与相邻节点的 mutual attention(就是在 pooling 层引入一个相关程度矩阵),得到顶点针对该相邻节点的 context-aware embedding。 [http://thunlp.org/~tcc/publications/acl2017_cane.pdf]
- Xiaofei Sun, Jiang Guo, Xiao Ding, Ting Liu A General Framework for Content-enhanced Network Representation Learning 加文本信息。这篇文章在学习网络节点的表示时,不仅考虑节点之间的关系,而且还 考虑到节点所附带的一些文本信息,比如twiter用户所发布的推文。 作 者将这些文本信息也当做成网络中的一个节点,同时每个文本节点并不 只与一个用户节点相连,比如同一条推文可能被多人转发,这样可以缓 解网络稀疏的问题。 把文本也当成一个特殊节点后,网络中就会存在两种边,一种是node- node link,另一种是node-content link. 对于这两种边,作者都采用 了LINE中的一阶相似度来表示, 然后加权相加。 [https://arxiv.org/pdf/1610.02906.pdf]
- Jiwei Li, Alan Ritter, Dan Jurafsky,Learning Multi-faceted Representations of Individuals from Heterogeneous Evidence using Neural Networks [https://arxiv.org/abs/1510.05198] 这篇文章同样是对网络结构和文本内容同时建模。跟上一篇所不同的 是,它不是将整个文本表示成一个节点,而是将文本中的每一个关键词 当成一个节点,这样可以进一步的丰富node-content link:一个用户节 点可以对应文本中的额多个关键词,而一个关键词又可以和多个用户节 点相连接。作者对连接边任然使用的事LINE中的一阶相似度。 [https://arxiv.org/abs/1510.05198]
- Yunfei Long ; Qin Lu ; Yue Xiao ; MingLei Li ; Chu-Ren Huang Domain-specific user preference prediction based on multiple user activities 这篇文章采用了几乎相同的文本处理方法,不同在于它使用LINE中的二阶 相似度来刻画连接信息。 [http://ieeexplore.ieee.org/document/7841066/metrics]
- Jian Tang, Meng Qu and Qiaozhu Mei, Identity-sensitive Word Embedding through Heterogeneous Networks arxiv 2016
这篇论文出自LINE的第一作者Jian Tang, 目的是学习出带有不同语 义标识identity的词向量。通常词向量学习把一个词的所有意思表示成 一个固定的向量,并没有考虑的他的不同语义。语义标识identity可以 是主题分类,情感分类,标识分类。比如一个词的含义包含不同的主题 分类,也就是在不同的主题下下有着各种分布,这种分布就代表了词与 不同主题的的不同连接权重。这样在就可以构建一个包含word-context link 和word-indentity link的网络。同时对这两种边学习使用的LINE中的二阶相似度。
[https://arxiv.org/abs/1611.09878] - Jian Tang, Meng Qu and Qiaozhu Mei. PTE: Predictive Text Embedding through Large-scale Heterogeneous Text Networks. To appear in KDD'15. 异构网络Embedding,其中包含三种二部图网络,word-word,word-document, word-label。每种网络用LINE中的2阶临近度作损失函数加一块。和引文中8,9,10,11思想一样。 [https://arxiv.org/abs/1508.00200]
- Zhipeng Huang, Nikos Mamoulis ,Heterogeneous Information Network Embedding for Meta Path based Proximity 异构网络Embedding,图中有不同类型的点,不同类型的连边。引入了meta path的概念,就是不同点之间的连边是按照一定的元信息连起来的,比如A1(Author)-P1(Paper)-A2(Author)这样一个meta path表示的信息可能就是A1和A2之间合作了一篇paper,这个概念可以很好地推广到很多场景。一般在计算proximity的时候都是按照1st order这样的思路来的,但引入了meta path概念的时候,如果A和B在一条meta path的两端,那么它们的proximity应该更大,当然这也取决于这条元路径本身的信息量。 文章中选择了所有长度小于l的元路径,因为一般来说路径越长其信息量越少。 最后的损失函数同样是刻画分布的距离。 [https://arxiv.org/abs/1701.05291]
- Leonardo F. R. Ribeiro, Pedro H. P. Saverese, Daniel R. Figueiredo. struc2vec: Learning Node Representations from Structural Identity. KDD 2017 对于图中的的两个sub 非常相似,但是由于两者之间离得非常远,没有任何share的node,之前的embedding方式并不能捕捉到他们之间结构上的相似性。这篇文章提出了一个较为灵活的框架struc2vec,对图中的节点进行embedding,以期能够捕捉node在结构上的相似度。 [https://arxiv.org/pdf/1704.03165.pdf]
- Kewei Cheng, Jundong Li, Huan Liu. Unsupervised Feature Selection in Signed Social Networks. KDD 2017. [http://www.public.asu.edu/~jundongl/paper/KDD17_SignedFS.pdf]
- Xiao Wang, Peng Cui, Jing Wang, Jian Pei, Wenwu Zhu, Shiqiang Yang Community Preserving Network Embedding . AAAI 2017 Embedding中保存社区结构信息。 [http://media.cs.tsinghua.edu.cn/~multimedia/cuipeng/papers/NE-Community.pdf]
- Peng Cui, Wenwu Zhu. Structural Deep Network Embedding. Daixin Wang, KDD 2016. SDNE本文提出模型由无监督部分与监督部分两部分组成。无监督部分用于提取与二阶估计相关的特征;同时由于部分节点是直接相连的,因而可以得到其的一阶估计,从而引入模型的有监督部分。这两部分的损失函数线性组合,联合优化。 [http://www.kdd.org/kdd2016/subtopic/view/structural-deep-network-embedding/672]
- Shaosheng Cao, Wei Lu, Xiongkai Xu. Deep Neural Networks for Learning Graph Representations. AAAI 2016 这篇论文和SDNE算法有异曲同工之妙,都应用了auto-encoder,但在如何学习节点间连接信息的方法上却另辟蹊径。SDNE为了学习到邻接节点的相似信息,在目标函数中加入中间结果的loss函数(具体见上文),而本文则根据邻接信息改变每个节点的原始表达,作为自编码模型的输入。由于输入向量本身就含有网络连接信息,因此经过“压缩”后的向量也能表达节点关系。具体我们一步步来介绍。 [http://www.aaai.org/ocs/index.php/AAAI/AAAI16/paper/download/12423/11715]
- Thomas N. Kipf, Max Welling Semi-Supervised Classification with Graph Convolutional Networks. ICLR 2017. 图(Graph)或者网络(Network)是一种非常不同于图像的数据。尽管图的邻接矩阵显然可以看做一张图片,但是由于图中节点之间的可互换性,这就使得我们不能简单将CNN用在图上。图卷积神经网络就是把CNN扩充到图这种结构上的一种重要技术。它通过结合基于图的信号处理技术,扩展了卷积操作,从而使得人们可以对图进行深度学习处理。图分类(Graph classification)是一类新的机器学习问题,它旨在区分不同的大型网络拓扑结构。这一问题是图像分类的延伸,可以广泛应用于网络社区的发展预测、网络特征提取、网络发展预测等复杂系统问题之中。 [https://arxiv.org/abs/1609.02907]
- Meng Qu, Jian Tang, Jingbo Shang, Xiang Ren, Ming Zhang, Jiawei Han. An Attention-based Collaboration Framework for Multi-View Network Representation Learning, in Proc. of 2017 ACM Int. Conf. on Information and Knowledge Management (CIKM'17), Singapore, Nov. 2017 多视角学习节点Embedding,比如在作者关系网中,一个作者和和另一个作者可能既有共同作者的关系,又有相互引用的关系。 [https://arxiv.org/abs/1709.06636]
Tutorial
- Learning Representations of Large-scale Networks Jian Tang 唐建老师在KDD 2017 上做的Tutorial PPT(131页):[https://docs.google.com/viewer?a=v&pid=sites&srcid=ZGVmYXVsdGRvbWFpbnxwa3VqaWFudGFuZ3xneDo1YjZlNmU0MDkxZjBlNmM0]
- Network Embedding: Enabling Network Analytics and Inference in Vector Space 崔鹏 裴健 朱文武 KDD 2017 [http://media.cs.tsinghua.edu.cn/~multimedia/cuipeng/KDD%202017%20Tutorial.html] [https://pan.baidu.com/s/1geJrnYb]
- Network Representation Learning 崔鹏 在ICDM 2016上的Tutorial [http://media.cs.tsinghua.edu.cn/~multimedia/cuipeng/papers/Network%20Representation-Tutorial.pdf]
视频教程
- Network Representation: A Revisit in the Big Data Era 崔鹏老师在KDD2016S上的报告视频 [http://videolectures.net/kdd2016_cui_network_representation/] [https://pan.baidu.com/s/1dFvoYC5]
代码
- OpenNE: An open source toolkit for Network Embedding [https://github.com/thunlp/OpenNE]
- DeepWalk [https://github.com/phanein/deepwalk]
- LINE: Large-scale information network embedding [https://github.com/tangjianpku/LINE]
- PTE: Predictive Text Embedding through Large-scale Heterogeneous Text Networks [https://github.com/mnqu/PTE]
- Visualizing Large-scale and High-dimensional Data [https://github.com/lferry007/LargeVis]
- Max-Margin DeepWalk: Discriminative Learning of Network Representation[https://github.com/thunlp/mmdw]
- node2vec: Scalable Feature Learning for Networks. Aditya Grover, Jure Leskovec [https://github.com/aditya-grover/node2vec]
- GraRep: Learning Graph Representations with Global Structural Information [https://github.com/ShelsonCao/GraRep]
- Network Representation Learning with Rich Text Information [https://github.com/thunlp/tadw]
- CANE: Context-Aware Network Embedding for Relation Modeling [https://github.com/thunlp/cane]
- struc2vec: Learning Node Representations from Structural Identity. [https://github.com/leoribeiro/struc2vec]
- Structural Deep Network Embedding [https://github.com/suanrong/SDNE]
- Deep Neural Networks for Learning Graph Representations [https://github.com/ShelsonCao/DNGR]
- Max Welling Semi-Supervised Classification with Graph Convolutional Networks PyTorch实现:[https://github.com/tkipf/pygcn] TensorFlow实现:[https://github.com/tkipf/gcn]
领域专家
- Jian Tang (唐建) 唐建博士2017年秋季加入蒙特利尔大学商学院担任助理教授,同时也是深度学习奠基人之一Yoshua Bengio教授领导的深度学习小组MILA的教师成员。 他的研究兴趣包括深度学习、强化学习、统计主题模型以及这些方法在不同领域的应用。他于2014年北京大学信息科学技术学院获得博士学位。曾经是密歇根大学和卡内基梅隆大学的联合培养博士后以及微软亚洲研究院副研究员。他于2014年获得机器学习顶级会议ICML的最佳论文以及2016年获得数据挖掘顶级会议WWW最佳论文提名。他是人工智能和数据挖掘领域多个顶级会议的程序委员如IJCAI, AAAI, ACL, EMNLP, WWW, WSDM, and KDD. 合作者:Meng Qu [https://sites.google.com/site/pkujiantang/]
- Zhiyuan Liu 刘知远 刘知远博士,清华大学计算机系助理教授。主要研究方向为表示学习、知识图谱和社会计算。2011年获得清华大学博士学位,已在自然语言处理等领域的著名国际期刊和会议发表相关论文50余篇。曾获清华大学优秀博士学位论文、中国人工智能学会优秀博士学位论文、清华大学优秀博士后等称号。 刘老师组里的Cunchao Tu, Yang Liu, Cheng Yang,Yankai Lin都有NE的相关工作。 个人主页:http://nlp.csai.tsinghua.edu.cn/~lzy ~ , [http://weibo.com/zibuyu9] [http://nlp.csai.tsinghua.edu.cn/~tcc/] [http://nlp.csai.tsinghua.edu.cn/~lyk/]
- Peng Cui 崔鹏 清华大学计算机系副教授研究方向:机器学习、数据挖掘、社会媒体等。 [http://media.cs.tsinghua.edu.cn/~multimedia/cuipeng/]
成为VIP会员查看完整内容
参考链接
荟萃目录
提示
微信扫码咨询专知VIP会员与技术项目合作 (加微信请备注: "专知") ![]()