成为VIP会员查看完整内容
VIP会员码认证
首页
主题
会员
服务
注册
·
登录
DeepWalk
关注
3
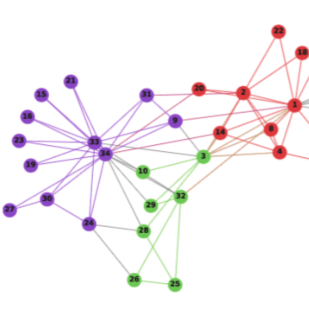
DeepWalk是最早提出的基于 Word2vec 的节点向量化模型。其主要思路,就是利用构造节点在网络上的随机游走路径,来模仿文本生成的过程,提供一个节点序列,然后用Skip-gram和Hierarchical Softmax模型对随机游走序列中每个局部窗口内的节点对进行概率建模,最大化随机游走序列的似然概率,并使用最终随机梯度下降学习参数。
综合
百科
VIP
热门
动态
论文
精华
精品内容
没有数据了, 换个别的吧!
参考链接
提示
微信扫码
咨询专知VIP会员与技术项目合作
(加微信请备注: "专知")
微信扫码咨询专知VIP会员
Top