

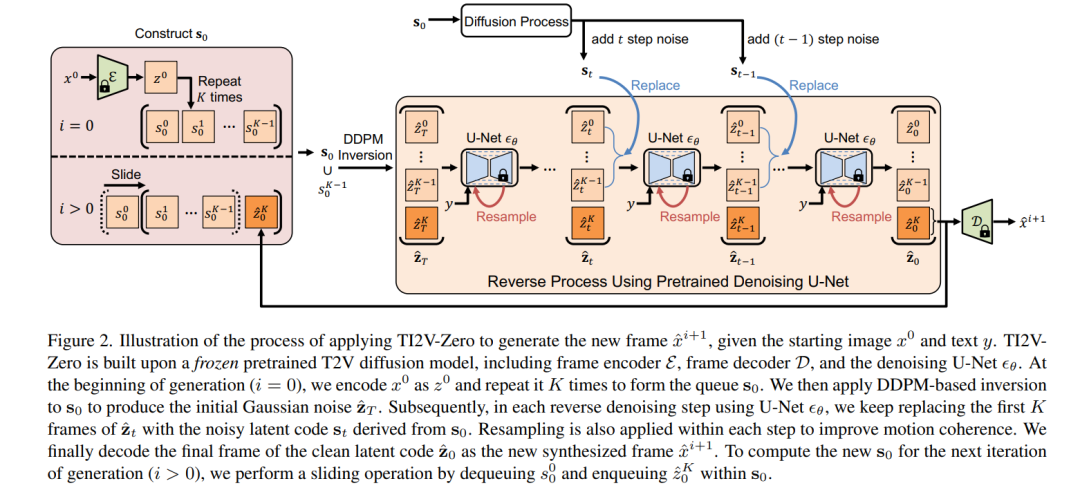
文本条件化的图像到视频生成(TI2V)旨在从给定图像(例如,一张女性的照片)和文本描述(例如,“一个女人正在喝水”)开始,合成一个逼真的视频。现有的TI2V框架通常需要在视频-文本数据集上进行昂贵的训练,并且需要针对文本和图像条件化的特定模型设计。在本文中,我们提出了TI2V-Zero,一种零样本、无需调整的方法,它使预训练的文本到视频(T2V)扩散模型能够基于提供的图像进行条件化,实现TI2V生成而无需任何优化、微调或引入外部模块。我们的方法利用预训练的T2V扩散基础模型作为生成先验。为了在附加图像输入的指导下生成视频,我们提出了一种“重复和滑动”策略,调节逆去噪过程,允许冻结的扩散模型从提供的图像开始逐帧合成视频。为了确保时间连续性,我们采用DDPM反转策略初始化每个新合成帧的高斯噪声,并使用重采样技术帮助保持视觉细节。我们在特定领域和开放领域的数据集上进行了全面的实验,其中TI2V-Zero始终优于最近的开放领域TI2V模型。此外,我们展示了TI2V-Zero可以在提供更多图像的情况下无缝扩展到其他任务,如视频填充和预测。其自回归设计还支持长视频生成。
成为VIP会员查看完整内容
相关内容
Arxiv
30+阅读 · 2023年4月19日
Arxiv
135+阅读 · 2023年4月7日

相关VIP内容
相关资讯
相关论文
Arxiv
30+阅读 · 2023年4月19日
Arxiv
135+阅读 · 2023年4月7日