

扩散模型在生成过程中,早期阶段侧重于构建图像的基础结构,而细节部分(包括局部特征与纹理)则主要在后期阶段生成。因此,扩散模型中的同一网络层被迫同时学习结构性与纹理性信息,这与传统深度学习架构(如 ResNet 或 GAN)在不同层次捕捉/生成图像语义信息的方式存在显著差异。正是这种结构上的差异,激发我们对“时间维度上的扩散模型”展开探索。
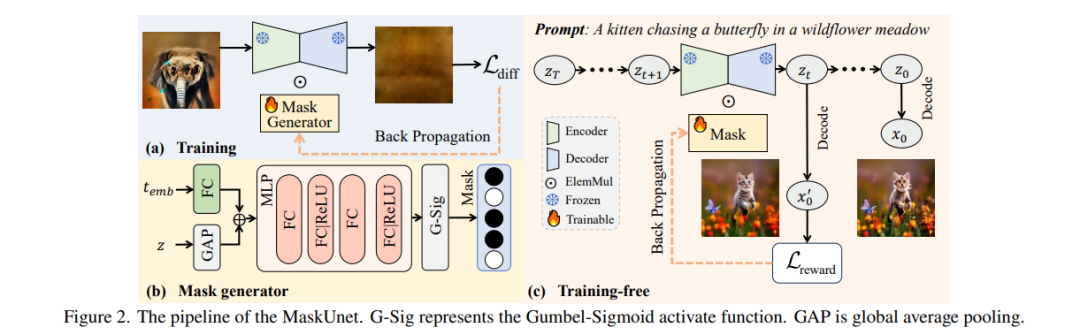
我们首先研究了 U-Net 各参数对去噪过程的关键贡献,并发现:合理地将某些参数置零(即使是数值较大的参数)反而有助于去噪,可即时提升生成质量。基于这一发现,我们提出了一种简单但高效的方法——“MaskUNet”,在不显著增加参数数量的情况下有效增强图像生成质量。 该方法充分利用了依赖于时间步与样本的有效 U-Net 参数子集。为进一步优化 MaskUNet,我们设计了两种微调策略:一种基于训练,另一种为免训练方式,均包括专门设计的网络结构与优化函数。 在 COCO 数据集上的零样本生成任务中,MaskUNet 取得了最优的 FID 分数,并在多项下游任务评估中表现出显著优势。 项目主页: 🔗 https://gudaochangsheng.github.io/MaskUnet-Page/
成为VIP会员查看完整内容
相关内容
Arxiv
38+阅读 · 2023年4月19日
Arxiv
207+阅读 · 2023年4月7日
Arxiv
20+阅读 · 2023年3月21日

相关VIP内容
相关资讯
相关论文
Arxiv
38+阅读 · 2023年4月19日
Arxiv
207+阅读 · 2023年4月7日
Arxiv
20+阅读 · 2023年3月21日