解耦合的类脑计算系统栈设计
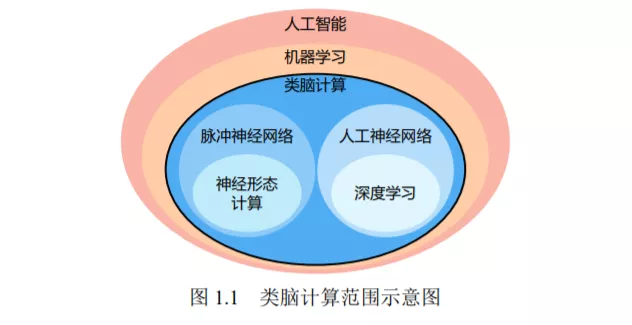
类脑计算是一种借鉴生物大脑计算原理的信息处理范式,涉及算法、硬件和 工艺等诸多领域。在算法层面,深度神经网络在各类智能问题的解决上表现出了 一定的通用性;在硬件层面,大量涌现的深度学习专用芯片和神经形态芯片为类 脑计算的相关研究领域提供强大算力;在工艺层面,以忆阻器为代表的各种新型 器件也为类脑计算芯片架构突破“冯诺依曼瓶颈”带来了新的可能。但现有的类 脑计算研究尚缺乏能将算法、芯片和工艺等不同领域技术需求有机结合起来的软 硬件系统栈设计。例如,专用芯片在带来更高计算性能的同时也降低了灵活性,使 得算法的适配变得困难;忆阻器等新型器件在为芯片提供更高能效的同时,也带 来了器件不稳定引起的噪音等问题。针对上述问题,本文提出一套新型类脑计算 系统栈设计,在理论层面引入类脑计算完备性,使得类脑系统实现软硬件解耦合 成为可能;在基础软件层面设计了相应的编译器,实现软件编程模型到硬件执行 模型的等价转换;在硬件层面设计了基于忆阻器件的类脑芯片架构,充分利用本 文提出的编译器设计和解耦合系统栈带来的优势。本文的创新点主要有:
• 提出软硬件解耦合的类脑系统栈设计。在系统栈中引入软件编程模型和硬件 执行模型来解耦合——软件编程模型灵活度高,适应各类编程需求,而硬件 执行模型足够简洁,适合硬件高效实现;引入类似于图灵完备性的类脑完备 性概念来建立软件和硬件两类模型的等价性,并给出相应的构造性证明,使 得类脑计算系统软硬件解耦合成为可能。
• 设计针对硬件约束的类脑编译器,将神经网络软件编程模型转换为等价的硬 件执行模型。编译器通过数据重编码方式,使目标网络在极端硬件约束条件 下仍然能够保持精度损失可控(包括无损);此外,提出适用于硬件执行模 型的粗粒度剪枝压缩方法,充分利用神经网络模型本身的冗余,在 ImageNet 数据集的 VGG16 模型上,即使剪枝粒度达到 256 × 256 压缩率也能达到 60% 以上,且精度损失可以忽略。
• 设计与上述类脑计算完备性和编译技术适配的新型类脑芯片架构 FPSA (Field Programmable Synapse Array)。利用编译器转换后硬件执行模型的简洁 性,简化基于忆阻器的芯片结构设计,提高计算密度与计算性能,并引入可 重构路由架构以优化片内通信。与同样基于忆阻器的类脑芯片架构 PRIME 相比,性能提升可达三个数量级。