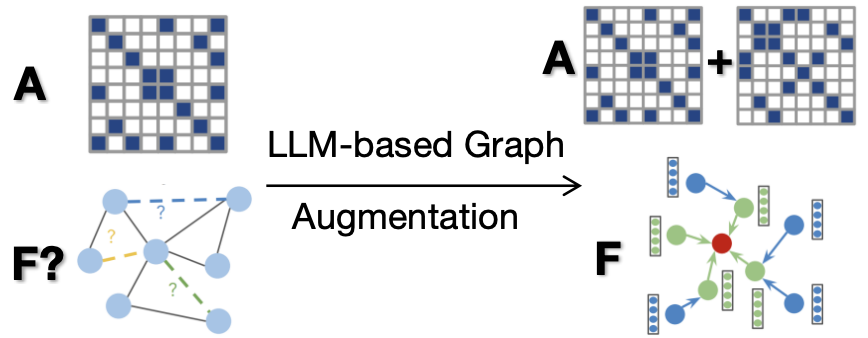
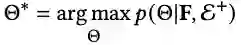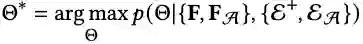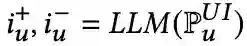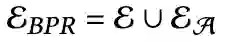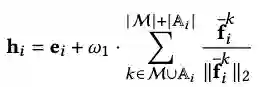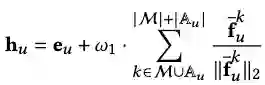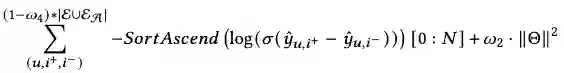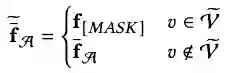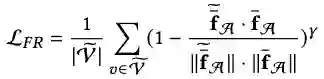(作者投稿)今天给大家分享一篇香港大学Data Intelligence Lab发表在WSDM2024上oral presentation的论文:“LLMRec: Large Language Models with Graph Augmentation for Recommendation”。作者提出了三种基于LLMs的异质图数据增强范式,包括1)交互边的增强;2) 有基础文本信息的节点的增强;3) 无基础文本信息的节点的增强。这三种数据增强转化为推荐系统中的user-item交互图可以被看作是user-item交互的增强,item属性的增强,和user画像的增强。它们分别通过边(i.e.,1)和节点特征(i.e.,2,3)的助力了图学习。同时,关于图增强的去噪机制也被设计以确保增强的有效性和过程的鲁棒性。作者提供了理论分析以支撑基于LLMs的数据增强在解决推荐系统中non-interacted和noisy交互的问题。作者进行了与baseline的结果分析和消融实验以证明结果的有效性。
代码:https://github.com/HKUDS/LLMRec
1背景与概要
以GNNs为encoder的推荐系统可以被看作是一个两阶段的过程,即,先进行graph embedding,然后接下来进行link predition任务。但是,长久以来推荐系统都被数据稀疏性困扰,user-item交互边的稀疏导致了link prediction的监督信号的稀缺,进而导致推荐结果的不准确。以往研究尝试将side information作为节点特征引入,以应对数据稀疏性的问题。然而,节点特征本身却也可能存在着诸多问题,比如side information的可得性,完整性和质量问题。这些问题可能不仅无法增强建模的过程,甚至可能损害最终下游任务的结果。
为应对上述问题,LLMRec提出了用LLMs辅助图学习的过程。LLMs以其出色的自然语言理解能力和丰富的知识背景为我们提供了解决上述问题的新机遇。因此,这篇工作以充分利用LLMs来协助图学习驱动的推荐系统。具体而言,LLMRec采用了三种基于LLMs的数据增强策略以增强依赖附加信息的推荐系统,这三种策略包括:i) 隐式反馈的增强,ii) 商品属性的增强,以及 iii) 用户画像的增强。这些策略不仅充分利用了数据集中的文本信息和LLMs的知识资源,还充分依赖LLMs在以图学习为基础的推荐系统中捕捉用户偏好的自然语言理解能力。此外,为确保增强数据的质量,LLMRec还引入了去噪机制,包括对i)的噪声边缘修剪和对ii)和iii)的基于MAE的特征增强。这一革新性的方法将LLMs与图学习相结合,为推荐系统的性能提供了新的突破口。
2挑战
2.1 如何解决因为LLMs输入受限而导致的无法处理全图问题?
首先,LLMs没有在图任务和图相关的数据集上训练过;其次,LLMs的'max_token_length'受限,这使得LLMs无法像正常的模型一样进行特定的下游任务。比如,对于链路预测,正常的GNNs是需要知道全图节点才能进行推理的,LLMs明显无法接受全图的信息。 为了解决这个问题,我们提出利用基础模型(比如:LightGCN)为每个需要进行链路预测的节点准备数量一定的candidates, 以解决LLMs的输入受限问题。这些candidates可能是一跳邻居,也有可能是多跳之外的节点。他们的选择由具体的任务的指标选择。然后,我们通过让LLMs基于图数据和已有的文本数据从candidates中选出positive edge和negative edge来辩证地建模单个节点的关系。同时,这种选择正负样本的方式可以自然而然地作为数据增强的协同过滤BPR训练数据,以让LLMs能够参与下游链路预测任务。
2.2 如何保证由LLM增强的图数据的可靠性?
从外部引入的知识不可避免地存在着噪声,即,不能保证增强得到的数据是对最终任务有效的。为应对这个问题,我们专门针对上述提到的边的增强i)和节点特征的增强ii)iii)进行去噪。具体地,对于i)我们直接刨除了可能存在影响的部分,对于ii)iii)我们引入MAE使得模型不敏感于特征, 并拥有较强的鲁棒性。
3方法
3.1 基于LLMs的图数据增强策略
3.1.0 普通特征图学习 & 数据增强的特征图学习
- 普通带有特征的GNNs编码器学习
普通特征图的输入包括特征和交互边信息,旨在充分利用这两个关于图中节点和它们之间关系的输入来建模节点的表征以及它们之间的相互影响。
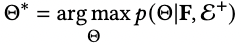
- 数据增强的带有特征的GNNs编码器学习
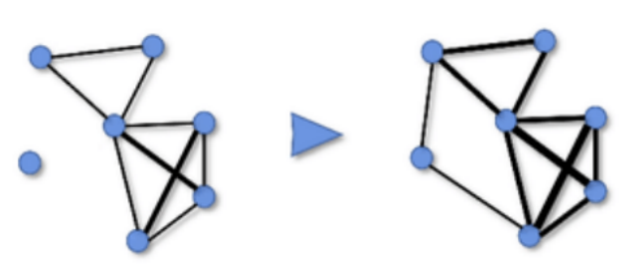
带有数据增强的图学习范式可以同时进行“边”和“节点”的增强。
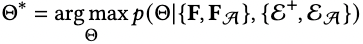
- 构造u-i语义边生成的prompt
利用和user节点相连的item节点的信息构造能够预测其他可能与user节点相连的item节点的prompt。这种方式不是在向量空间的消息传递,而是基于自然语言空间的建模。这种方式有两个优势:(1) 它使GNNs能够充分利用数据集中的内容。(2) 它直观地通过自然语言反映连边的关系。

- 将prompt输入LLM以生成潜在的user-item语义边
将用于生成user-item的prompt输入LLMs以得到潜在的语义边。为了整合被推荐的数据进推荐系统的学习框架,LLMRec促使LLMs选出一条可能的边和一条完全不可能的边以将他们作为正样本和负样本用于BPR算法中。
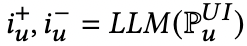
- 将LLMs生成的数据整合进下游任务的训练数据中
最后,下游任务的监督信号是原始的信号和增强的信号的并集。
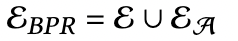
- 构造基于现有信息生成增强信息的prompt
已经拥有side information的节点可以通过这些辅助信息增强该节点表征的建模。但是,原本的信息可能存在着不足,缺失和低质量等问题。所以,基于LLMs的数据增强旨在为节点生成新的属性以弥补原始辅助信息的不足。

- 将prompt输入LLM以生成增强的node side information, 然后,将生成的side information转化节点特征
Side information的最终使用方式是作为节点特征用于GNNs编码器中。所以,在得到prompt之后,LLMs会根据prompt生成对GNNs编码器有潜在帮助的side information。在得到,side information之后,可以选用text-embedding-ada-002或者Sentence-BERT之类的模型作为文本信息的编码器为GNNs生成特征。

- 将增强的特征用于GNNs encoder
将增强的特征引入GNNs的方式可以有两种,作为初始化特征,作为额外的特征加到GNNs原有的表征上。本文选用作为额外的特征加入。
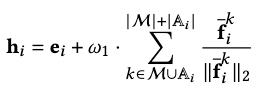
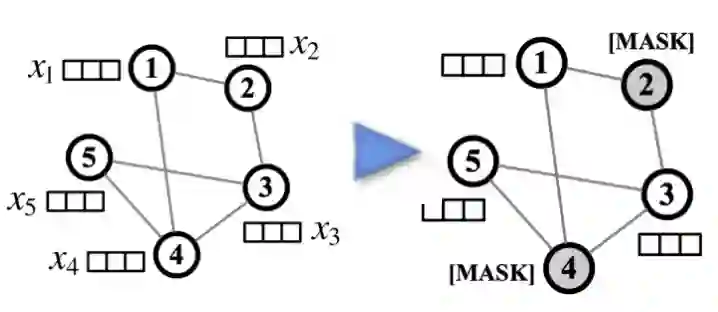
3.3 基于LLMs的无side information节点的增强
对于没有初始side information的节点,本篇工作利用拥有side information的一跳邻居来增强本来没有的文本信息。比如,在推荐系统中因为隐私问题,user原本是没有side information的,但是本篇工作的数据增强方式使得user能够拥有简单的用户画像以帮助推荐,即用额外的信息增强GNNs消息传递的过程。
- 通过有side information的一阶邻居节点构造使锚点信息增强的prompt
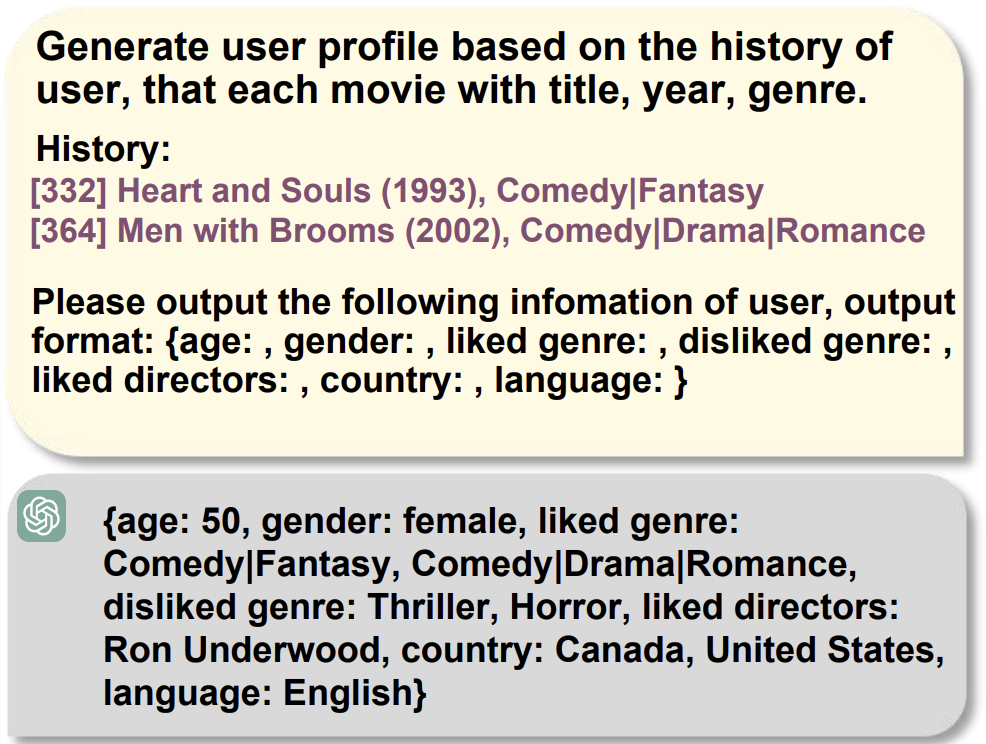
- 将prompt输入锚点以通过LLMs从无到有生成节点side information, 然后,将生成的side information转化节点特征

- 将生成的特征用于GNNs encoder
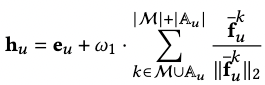
3.4 增强的图数据去噪
- 对增强的边去噪
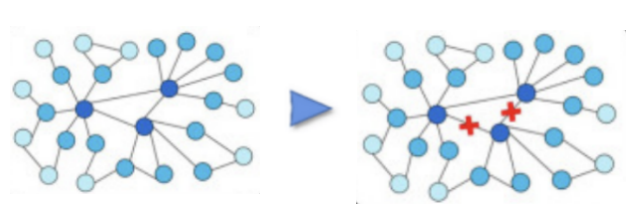
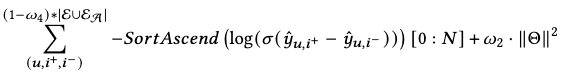
- 对增强节点特征去噪
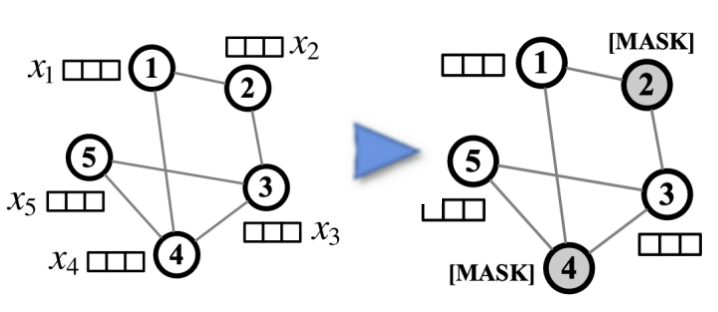
对增强了的feature进行MAE(masked auto-encoder)能让编码器对feature不那么敏感以增强模型对feature中噪声的鲁棒性。具体过程分为mask掉一定数量的节点特征和用mask token替代和用回归loss约束还原被mask掉的节点特征。

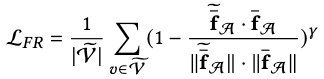
4结果
4.1 主实验
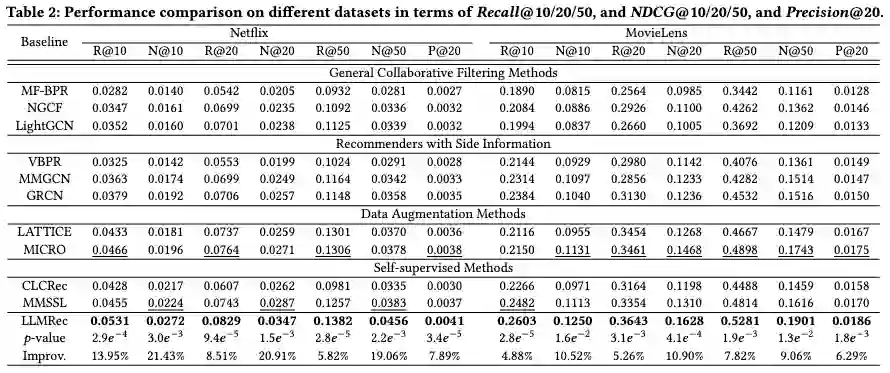
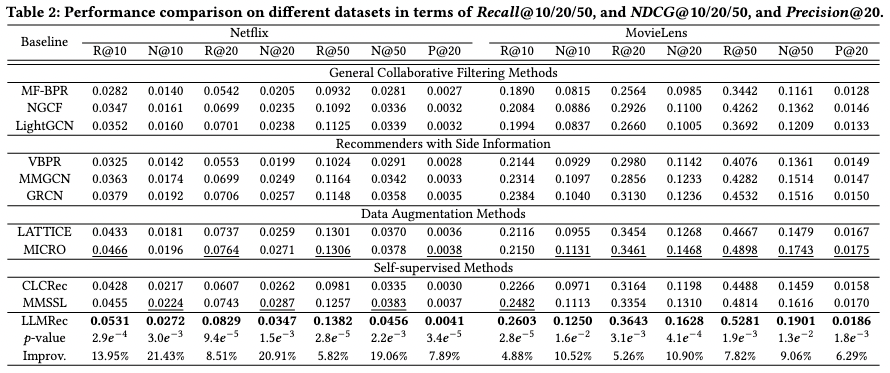
该工作预处理并公开了多模态的数据集Netflix,包括交互边和节点特征和文本模态内容。其在目前content-based的方法中取得了SOTA的结果。
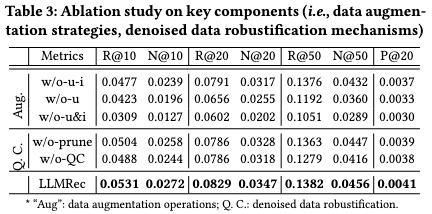
4.2 消融实验
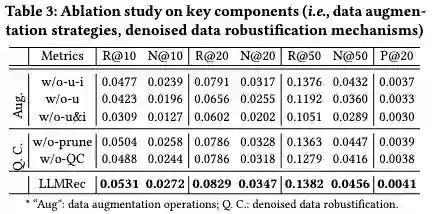
消融实验主要针对数据增强和去噪两个部分。w/o-u-i在消去LLM增强的u-i边的情况下,结果显著下降。这表明LLMRec通过包含上下文知识增加了潜在的监督信号,从而更好地把握用户的偏好。由w/o-u则可观察出移除被增强的节点特征会导致性能下降,这表明去除嘈杂的隐式反馈信号的过程有帮助。消融实验说明了该工作所设计的基于LLMs的数据增强方法。
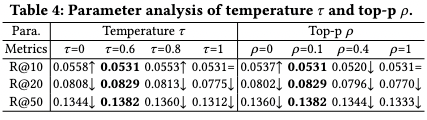
4.3 参数实验
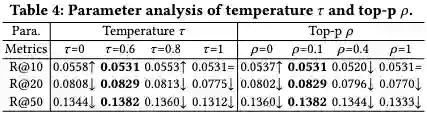
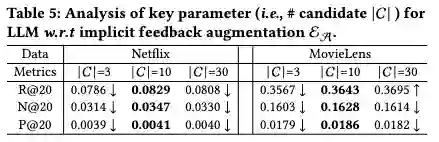
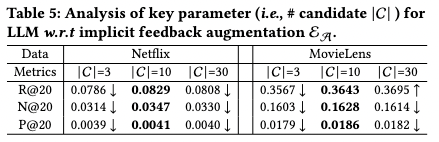
温度参数 影响文本的随机性。较高的值(>1.0)增加多样性和创造性,而较低的值(<0.1)导致更加聚焦。LLMRec使用 从集合 中选取。如表所示,增加 起初提高了大多数指标,随后出现下降。Top-p抽样根据由顶部参数 确定的阈值选择标记。较低的 值优先选择可能的标记,而较高的值则鼓励多样性。LLMRec使用来自集合 的 值,较小的 值往往产生更好的结果。LLMRec使用 来限制基于LLM的推荐系统中的物品候选项。由于成本限制,这篇工作探索了 ,而表显示 产生了最佳结果。较小的值限制了选择,而较大的值增加了推荐的难度。LLMRec使用 来限制基于LLM的推荐系统中的物品候选项。由于成本限制,LLMRec尝试了 ,而表显示 产生了最佳结果。较小的值限制了选择,而较大的值增加了推荐的难度。
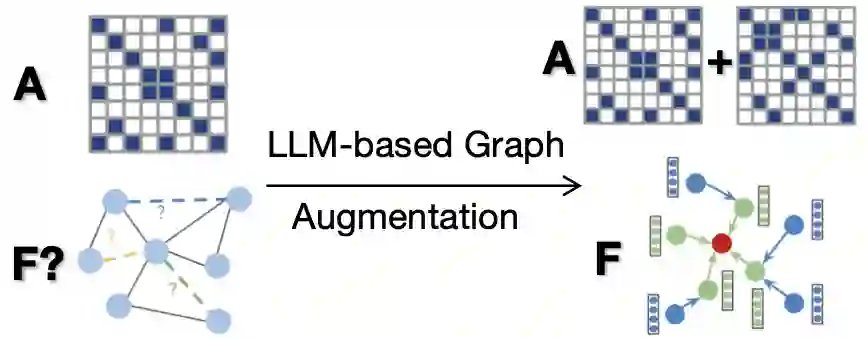
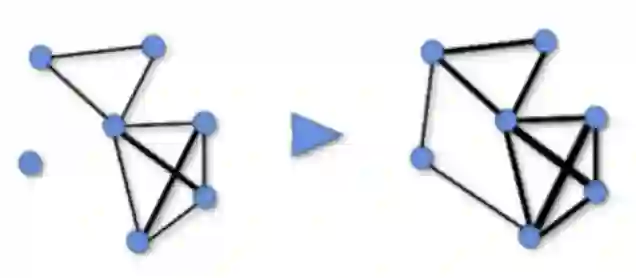
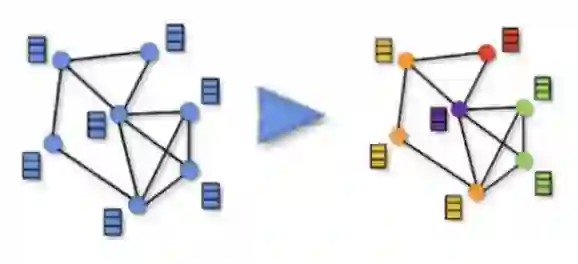
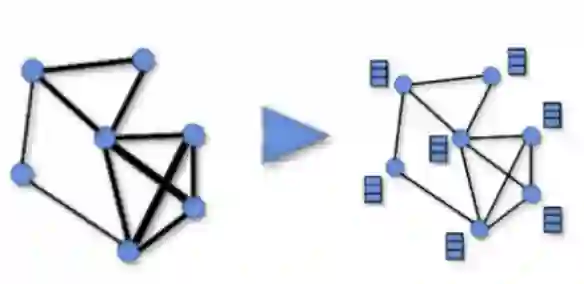
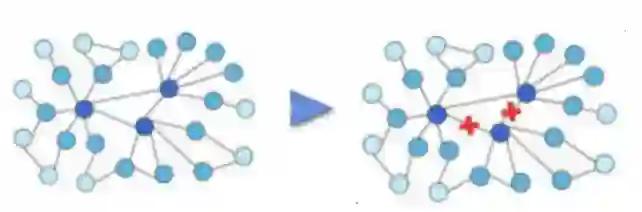
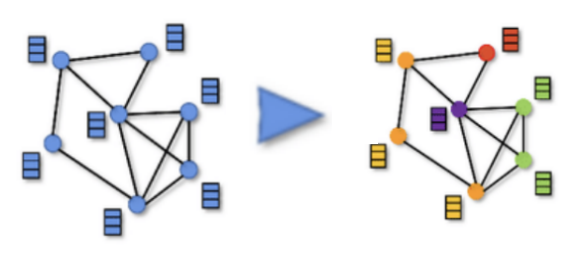
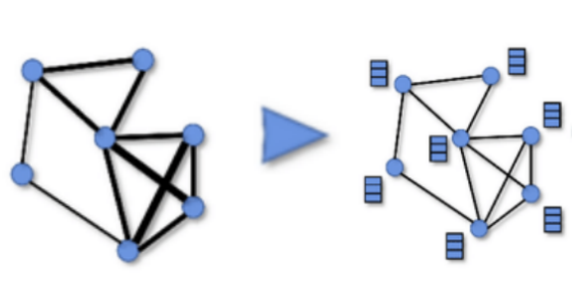
4.4 增强的边与节点的展示
本研究通过增强用户-物品交互图的边和节点,进一步强化了GNNs的作用。下面三张图片分别代表了增强的用户与物品之间的交互边,和user节点和item节点分别被增强的节点属性。这些节点属性在GNNs的消息传递和嵌入过程中被转化为特征,从而提升了推荐算法的性能。