

论文题目:Have We Designed Generalizable Structural Knowledge Promptings? Systematic Evaluation and Rethinking
本文作者:张溢弛(浙江大学)、陈卓(浙江大学)、郭凌冰(浙江大学)、徐雅静(浙江大学)、陈少凯(浙江大学)、孙梦姝(蚂蚁集团)、胡斌斌(蚂蚁集团)、张志强(蚂蚁集团)、梁磊(蚂蚁集团)、张文(浙江大学)、陈华钧(浙江大学)
发表会议:ACL 2025 Main Conference
论文链接:https://arxiv.org/abs/2501.00244
代码链接:https://github.com/zjukg/SUBARU
欢迎转载,转载请注明出处****
一、引言
本论文关注大型语言模型(LLMs)在知识密集型任务中面临的关键挑战:事实准确性不足。虽然结构化知识提示(Structural Knowledge Prompting, SKP)通过将知识图谱(KGs)的结构化表示整合到LLMs中,显著提升了如问答和知识图谱补全等任务的性能,成为主流范式,如下图所示,已有的SKP通常用一个结构编码器+适配器的形式将从KG中提取到的结构化信息注入LLM,但现有研究大多聚焦于特定任务应用,缺乏对SKP范式本身泛化能力的系统性评估。
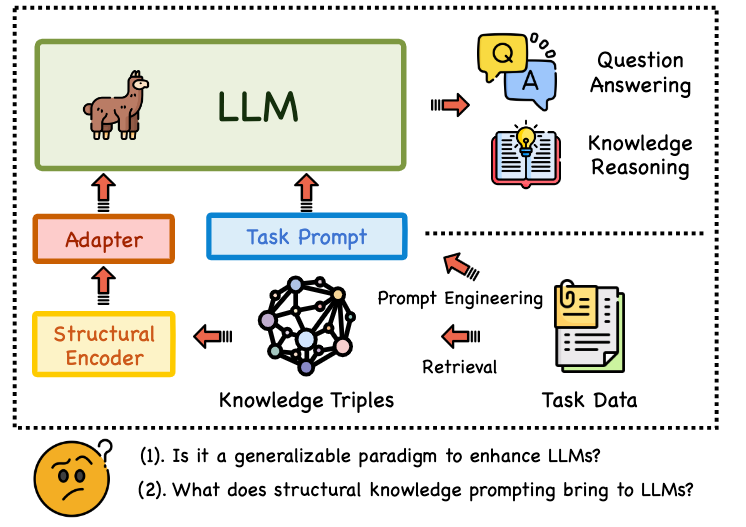
本文旨在填补这一空白,首次对SKP的泛化能力进行全面审视,围绕四个核心维度展开:知识粒度(Granularity)、跨任务与元素的可迁移性(Transferability)、可扩展性(Scalability) 以及对不同LLM的普适性(Universality)。为此,作者构建了一个全新的多粒度、多难度基准测试集 SUBARU 来支撑这项评估。 二、方法
结构化提示的工作流程
SKP的核心目标是将知识图谱(KG)的结构化信息高效注入大型语言模型,以提升其事实准确性。其工作流程分为三步: 知识抽取与编码: 给定用户查询 ,从外部知识图谱 中检索相关元素(实体 、关系 或子图)。通过预训练的结构编码器 如 TransE、R-GCN)将每个元素转化为向量嵌入。 表示空间对齐: 由于 KG 嵌入与 LLM 的文本表示空间存在异构性,需通过适配器(Adapter) 进行映射。适配器将结构嵌入转换为与 LLM 词向量维度对齐的提示 token 对于单个提示token而言,整个过程可以表示为: 论文测试了四类适配器:单层全连接(FC)、多层感知机(MLP)、混合专家(MoE)和 QFormer。 LLM 协同推理: 生成的提示 token 序列与原始查询 拼接,输入冻结的 LLM。LLM 基于联合输入生成答案: 训练时仅优化适配器参数,损失函数为标准的Next-token Prediction损失
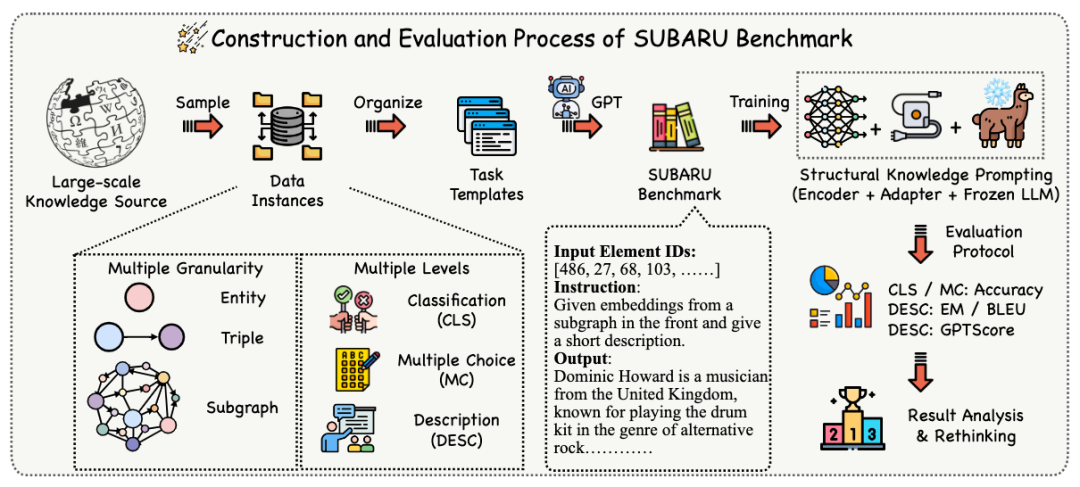
SUBARU数据集的构建逻辑
为系统性评估 SKP 的泛化能力,作者设计了 SUBARU 基准,其构建遵循两个核心原则:多粒度知识覆盖与任务难度分层。SUBARU设计了三种不同的任务粒度和三种不同的任务难度。 三种粒度:
-
实体级(EG)
-
三元组级(TG)
-
子图级(SG)
三种难度:
-
分类(CLS)
-
选择(MC)
-
描述(DESC)
**实例采样。**首先,我们从KG中按不同粒度采样实体/三元组/子图实例,以准备不同的任务。对于EG任务,我们采样大约2万个具有充分描述的实体,比例为8:1:1。对于TG任务,我们使用CoDeX-M三元组的拆分来构建数据集。对于SG任务,我们从EG任务中选择实体,然后随机采样它们的一跳和二跳邻域以构建子图。同时,每个任务都有特定设置。对于CLS任务,我们将一个实体ID与其真实的简短名称视为正例。对于TG和SG,我们将从现有KG中采样的每个三元组和子图视为正例。 我们进一步通过随机扰动生成负样本,保持1:1的比例。在MC任务中,我们为每个实例采样四个选择:对于EG,我们预测实体名称;对于TG和SG,我们预测缺失的实体。TG-MC中的缺失实体预测类似于传统的KGC任务,预测给定查询(h, r, ?)中的缺失尾实体。对于SG,查询提供一个子图,其中缺少一个核心实体,要求预测子图中缺失的实体。对于DESC任务,实体、三元组和子图的描述作为生成的目标。实体和三元组的描述直接来自CoDeX数据集,而子图描述是使用{GPT-3.5-turbo}生成的。任务训练集验证集****测试集Entity CLS3212240164016Entity MC1609620122013Entity DESC1606120082008Triple CLS3711682062020622Triple MC1855841031010311Triple DESC1855841031010311Subgraph CLS2945439985142Subgraph MC1472719992571Subgraph DESC7453931939 **提示生成。**从CoDeX KG中采样后,我们通过为每个任务应用手工编写的指令提示I来创建特定任务的实例,将这些实例转换为文本格式以便进一步评估。遵循现有的范式,我们将SKP放置在输入序列的前面,向LLM提供来自KG的结构化信息。为了客观评估模型利用这些SKP的能力,我们去除了指令模板中相关元素的重要文本信息,使模型主要依靠SKP而不是文本来完成任务,以评估SKP的利用效果。 三、实验分析
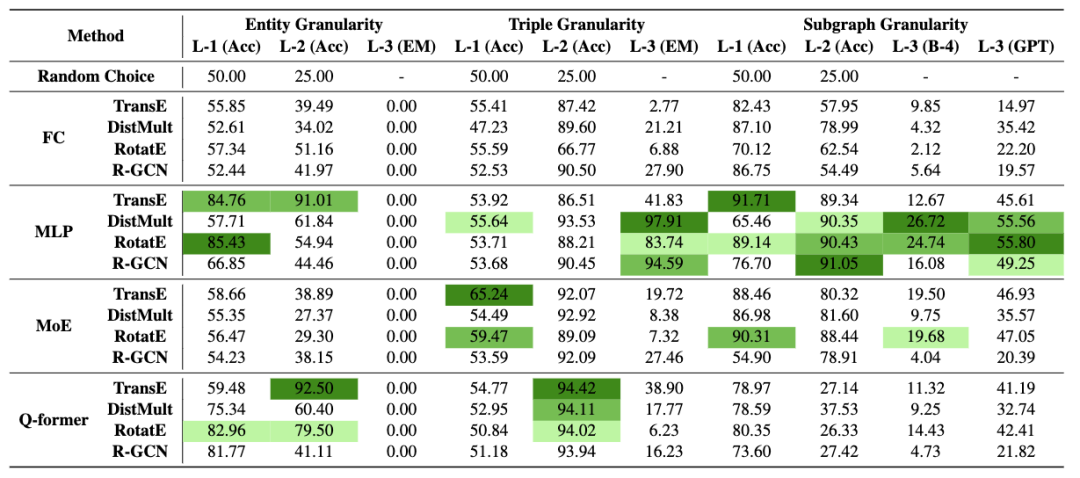
作者在SUBARU上进行了广泛的实验,测试了多种结构编码器和适配器组合,主要使用Llama3-8B作为基础LLM,并扩展到其他LLM验证普适性。核心发现如下: 知识粒度(RQ1):实验表明,MLP适配器在绝大多数任务中表现最佳,甚至优于更复杂的QFormer或MoE。SKP在粗粒度推理(三元组级/TG和子图级/SG的多选问答/MC任务)上表现出色,说明它能有效整合子图或三元组级别的结构化信息辅助LLM决策。然而,SKP在细粒度理解上存在明显局限:它几乎完全无法完成实体级描述生成(EG-DESC)任务,表明LLM无法仅凭SKP准确识别和理解新的、未见过的实体细节。案例研究进一步证实,SKP模型生成的子图描述能捕捉大致语义关联(如职业、领域),但无法精确复现关键实体名称。
可迁移性(RQ2):评估跨任务迁移性时发现,混合训练来自不同粒度或难度的任务数据,对提升目标任务性能帮助有限,表明当前SKP架构的跨任务泛化能力不强。但在处理新元素(如新实体) 方面,三元组级任务(TG-MC)展现了令人鼓舞的结果:模型在预测涉及未见实体的三元组时,性能接近其在已知实体上的表现,且训练数据中涵盖更多实体有助于提升这种归纳能力。
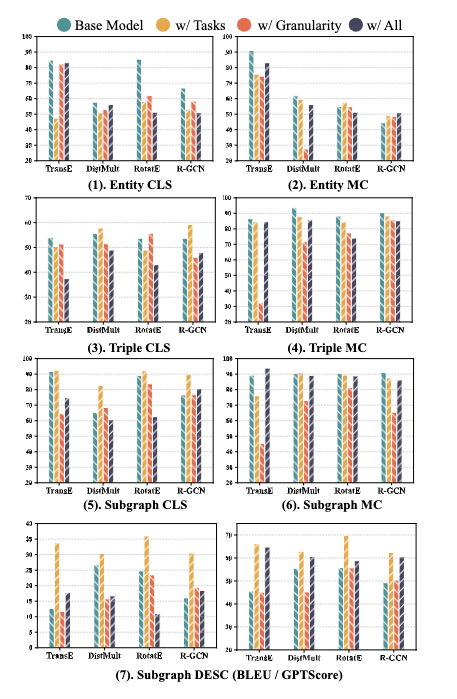
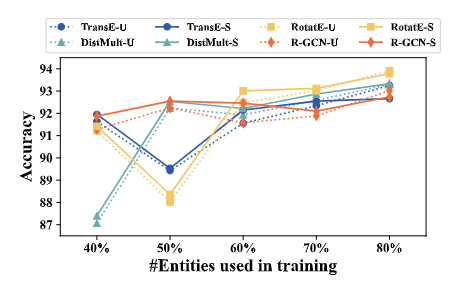
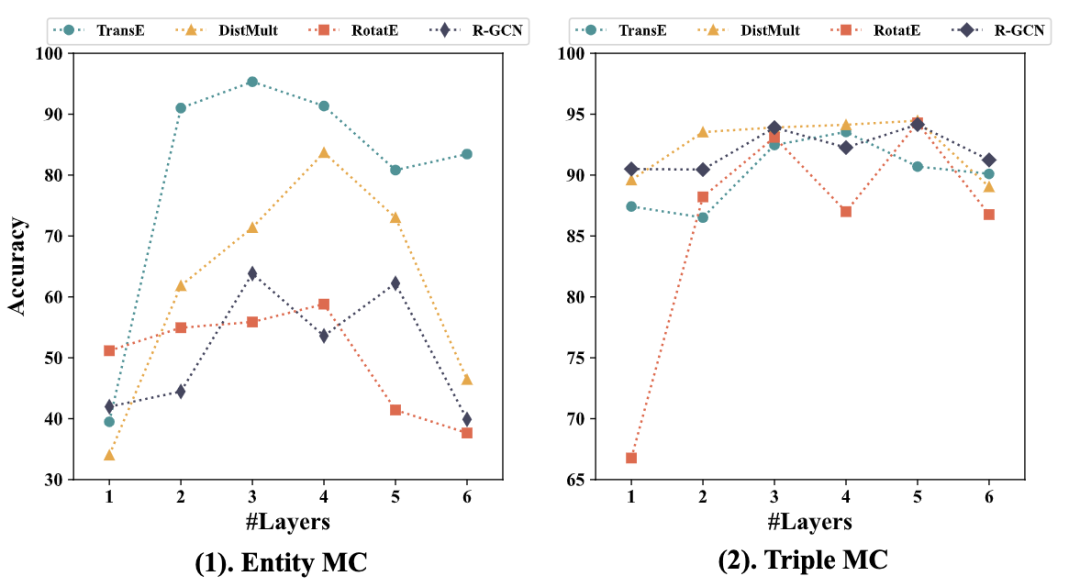
可扩展性(RQ3):研究适配器深度(MLP层数)的影响发现,性能并非随深度单调增长。3-4层的MLP通常能达到最佳效果,更深层可能导致性能下降。这表明适配器存在一个舒适区,过深的网络在当前数据规模下可能引入不必要的复杂性或训练难度。
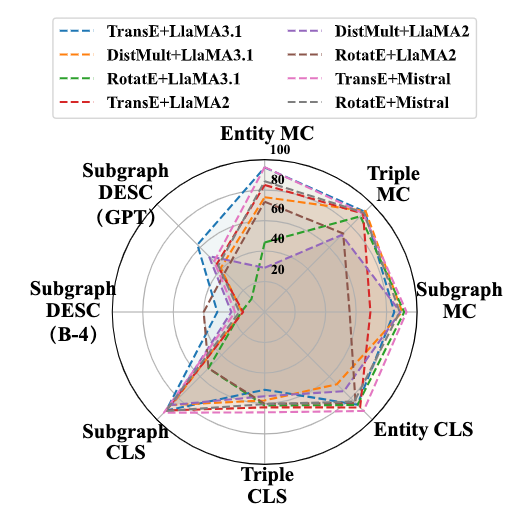
普适性(RQ4):SKP范式被证明具有较好的模型无关性。在Llama2-7B、Llama3-8B和Mistral-7B等不同架构的LLM上应用SKP,整体性能趋势保持一致,尽管不同LLM间存在微小差异。这证实了SKP作为一种增强LLM知识能力的通用方法是可行的。
案例分析: 在我们在SUBARU基准测试中设计的三个难度级别中,分类(CLS) 和多选问答(MC) 任务能提供明确的答案和量化指标,便于精确比较模型性能。然而,对于子图描述生成(DESC) 任务而言,评估生成文本的质量更具主观性。因此,本节通过案例研究分析SKP模型在描述子图结构时的能力。本案例研究的目的并非比较不同SKP模型的性能差异,而是揭示其在描述中存在的共性特征。
如图5所示,我们展示了一个简单案例:提供标准答案(Golden Answer)与多个不同SKP模型的预测结果(均以人工描述形式呈现)。通过观察可得出以下两点关键结论:
- 所有SKP模型均无法准确识别中心实体,这突显了SKP在传递高度精确和个性化信息上的能力缺失。这也解释了为何表2中所有SKP模型均在实体级描述任务(EG DESC)中失败——该任务要求精确识别实体。
- SKP模型展现出对粗粒度知识的理解能力:模型能捕捉输入SKP中实体与关系的语义关联,并在生成文本中体现理解。优秀的预测结果可解码出SKP中隐含的信息(如职业、专业领域、国籍、技能等)。
综上可知,SKP能为LLMs提供粗粒度信息以大致理解子图结构,却难以处理细节信息(如具体名称、地点或专业术语)。尽管SKP擅长识别实体属性等宏观知识,但其缺乏对细粒度细节的认知能力。考虑到文本生成与深层理解是LLMs的核心能力,我们认为未来SKP的改进应聚焦于通过额外的提示token激活更精确、细粒度的信息。

四、结论
本研究首次对结构化知识提示(SKP)范式进行了系统性的泛化能力评估。核心结论是:当前的SKP方法(尤其是结合MLP适配器)能有效地为LLMs注入粗粒度的结构化知识,显著提升其在子图和三元组级别推理任务(如知识图谱补全、多选问答)上的表现。然而,研究也揭示了其关键局限性:无法实现细粒度的、精确的事实感知,特别是在理解和描述新实体方面能力欠缺;跨任务迁移性较弱;适配器的可扩展性也存在边界(3-4层最佳)。 这些发现对领域发展具有重要意义:它们解释了现有SKP方法在特定任务(如QA, KGC)上成功的原因(擅长粗粒度推理),同时也为未来研究指明了方向——需要设计更先进的SKP方法,以突破其细粒度理解和新元素泛化的瓶颈,从而更全面地提升LLM的事实准确性。
