
军事决策过程(MDMP)是一种系统化、迭代式的方法,旨在分析复杂情况并制定有效的作战计划。尽管在高级参谋层级存在AI工具,但在营级层级仍存在显著空白,此类自动化系统几乎不存在,这为提升效率提供了机会。本文介绍了我们通过开发基于文本的AI工具来解决这一缺陷的研究,该工具旨在自动化MDMP过程中的行动方案(CoA)制定步骤,专门用于营级规划。采用的方法包括理解作战需求、构建定制AI模型,并针对真实战术场景检验模型能力。我们的研究结果显示出细微差别。虽然我们的解决方案在简化特定场景的计划生成方面展现出潜力,但也暴露了当前大语言模型(LLMs)固有的局限性,包括数据解释、集成和生成一致输出方面的问题。面临的挑战包括缺乏稳健的视觉图形集成或输出。这些发现警示了在当前状态下使用AI规划工具的风险,并为未来研究提出了建议,主张在领域特定数据集上增强模型训练和视觉数据集成,这可以提升AI在军事规划背景下的有效性。从我们的探索中得出的见解有助于奠定对AI在军事行动中作用的基础理解,并为自动化战术决策框架的进一步发展铺平道路。
本文结构如下:第2节详细介绍了我们的AI辅助工具开发方法和测试案例。第3节展示了测试案例结果和关键经验教训。第4节在更广泛背景下检视我们的发现,并识别军事AI规划工具的更广泛局限性。第5节以对未来工作的建议作为结论。
一、研究背景与意义
本论文针对美国国防部在营级战术规划中存在的自动化工具缺失问题,开展了一项创新性研究。军事决策过程(MDMP)作为美军系统性作战规划方法,在高级参谋层面已存在AI辅助工具,但在营级作战单位却几乎没有任何自动化系统支持。这一空白为提升作战效率提供了重要机会。
研究团队通过美国小企业创新研究计划(SBIR)提出的挑战,开发了基于文本的AI工具,专门用于自动化MDMP过程中的行动方案(CoA)制定步骤。该研究不仅展示了AI在特定场景下简化计划生成的潜力,同时揭示了当前大语言模型在军事规划应用中存在的根本性局限。
二、研究方法论
2.1 技术架构设计
研究团队采用三阶段策略:探索性研究、原型开发、测试与持续开发。在技术选型上,基于以下需求考量:
- 处理军事条令和战术文档的能力
- 可搜索的数据库存储
- 按需相关信息检索
- 依据军事条令生成战术计划
团队选择检索增强生成(RAG) 技术路线,该方案允许模型从外部知识源(如向量数据库)检索相关信息来增强文本生成过程。具体实施采用Palantir Technologies的AI平台(AIP),该平台提供云托管、文档导入简化等优势,且美军已在安全网络中使用Palantir工具,增强了部署的现实性。
2.2 测试框架设计
研究团队设计了五个测试套件,系统评估模型性能:
测试套件Alpha:聚焦于提示设计和模型设置对生成营级作战命令(OPORD)的影响,评估系统提示、任务提示和温度设置三个关键变量。
测试套件Bravo:测试模型在生成火力计划产品方面的条令推理能力,包括火力概念(CoF)和资产同步矩阵等需要结构化推理的规划产品。
测试套件Charline:评估连级战术规划中的推理能力,使用最详细的场景描述来检验模型的实际战术规划能力。
测试套件Delta:评估生成符合条令的营级行动方案的能力,重点关注与上级指令的一致性、连贯的分阶段机动规划等五个关键要求。
测试套件Echo:比较不同模型和配置在战术规划任务中的性能表现,寻找最优设置。
三、核心研究发现
3.1 提示工程的关键作用
测试套件Alpha的结果表明,系统提示B与更具指导性的任务提示B组合,配合温度设置0.7,能够产生最详细和战术有用的输出。评估采用五类评分标准:结构遵循性、单位任务特异性、条令合理性、灵活性和执行准备度。
表1展示了详细的评估标准,其中5分代表符合标准的即用型OPORD,1分代表不可用或严重错误的OPORD。结果显示,优化提示设计结合适度可变性模型配置,能显著提升生成可用营级OPORD的能力。
3.2 结构化输出的可靠性
测试套件Bravo发现,当通过系统提示或用户提示提供定义好的模板时,模型展现出生成结构化规划产品的一致能力。虽然输出保真度在迭代间略有变化,但模型总体上能够遵循条令结构和格式期望。
生成的资产同步矩阵同样显示了连贯的任务分配,将飞机分配到适当的时间块和任务角色中。这表明LLM在良好结构的提示和条令模板指导下,能够可靠生成详细、战术准确的规划产品。
3.3 连级规划的能力与风险
测试套件Charline揭示了模型在连级作战命令生成中的双重表现:一方面,模型在没有格式化模板或结构化指导的情况下,成功将书面战术场景转化为协调三个机动排的连贯CoA叙事;另一方面,发现了一个关键安全缺陷——模型指示Alpha排的火力支援元素向攻击部队的进入点转移火力,这一基本战术错误违背了标准条令,会造成高误伤风险。
这一疏忽表明模型缺乏内部安全验证机制,即使是新手指挥官通常也会应用这种验证。此外,模型将地形处理为文本而非三维空间,导致分配了可能缺乏实际视线的火力位置。
3.4 多模型性能比较
测试套件Echo发现,基于GPT-4o的架构始终优于其他替代方案,在大多数类别中获得了完美的结构分数(10分)和近乎完美的连贯性评级。而GPT-3.5表现出混合的连贯能力,经常省略整个必需部分。Claude 3.7在生成连贯的指挥官意图和作战概念方面优于Gemini 1.5。
温度测试(0.7对比0)证实了早期测试套件的发现:较高设置会略微降低输出结构,同时保持相似的连贯性水平,允许增加新颖性而不牺牲操作可用性。
四、技术局限性分析
4.1 视觉能力缺失
有效的任务规划不仅需要理解书面命令和条令指导,还需要解析视觉输入的能力,特别是卫星图像、战术地图和规划幻灯片。然而,当前模型缺乏空间推理和视觉解析能力,无法深入分析地形或从图像输入中应用军事符号系统。
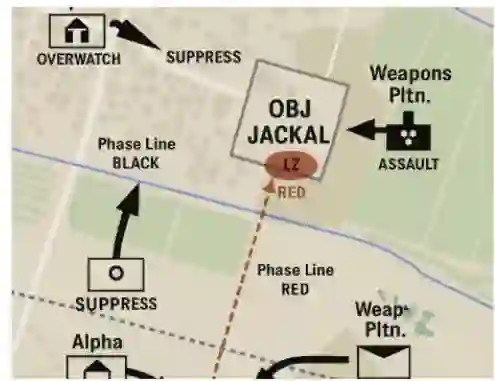
4.2 信任与可解释性问题
使用当前可用的AI规划工具需要对其成功性抱有盲目信任。LLM规划器无法一致地列出或解释其考虑或忽略了哪些因素,这本质上是一个可解释性问题:模型无法解释其如何基于输入和权重达成决策,人类操作员也无法验证给定输出。
4.3 数据访问限制
军事作战命令、行动方案示例以及真实作战中成败分析等数据几乎都是机密信息,无法用于训练非密模型。本研究项目必须在非密级别创建特定的模板和示例,这些模板和示例经过简化但随时间推移越来越详细。
4.4 单次执行限制
Palantir AIP平台设计为连续管道,不适用于反馈用户修正。对于可能希望向AI代理输入新细节或修正的任务规划人员来说,这种工作流程并非最优。
五、未来研究方向
5.1 空间智能集成
前沿多模态深度学习模型有望克服许多现有限制。这一发展轨迹与AI研究的更广泛发展相一致,领先学者将空间智能视为生成式AI的下一个关键前沿。世界实验室的Fei-Fei Li等行业领袖正在推广“空间智能AI”,通过大世界模型(LWM)来“感知、生成和与3D世界交互”。
5.2 基于代理的模拟环境
添加基于代理的模拟环境和反馈循环将显著增强系统评估和改进自身计划的能力。通过在动态交互环境中模拟AI生成的CoA,系统可以识别弱点,如暴露的路线、不良时机或有缺陷的任务组织。反馈循环将允许系统基于模拟结果修订其计划,随时间提高战术真实性和适应性。
5.3 人机协作优化
需要从将AI视为武器平台转向将其视为非直接战斗问题的解决方案提供者,这些问题仍然受到有意义的人类控制。AI工具可以协助减少认知偏见和时间强度,但不应完全取代军事背景下的人类决策者。
六、结论与启示
本研究通过系统性的测试框架,揭示了LLM在战术任务规划中的实际能力与局限。研究表明,虽然现有技术能够生成结构良好的战术规划文档,但在实战可靠性、安全性和空间推理方面仍存在重大挑战。
最重要的是,研究发现即使模型能够生成条令对齐的计划,人类验证对于作战可靠性仍然至关重要。当前LLM可以支持最小指导下的连级规划,但基本战术错误的风险要求保持严格的人类监督机制。
未来的研究应当聚焦于开发集成空间推理、视觉理解和动态模拟的下一代规划系统,同时建立相应的人机协作框架,确保AI在军事规划中的应用既高效又安全。这一研究为理解AI在军事行动中的作用奠定了基础,为自动化战术决策框架的进一步发展铺平了道路。
本研究的实际意义在于为国防部门提供了明确的技术路线图:在追求自动化效率的同时,必须投资于安全验证机制和人类监督系统,确保AI辅助规划既提升效率又不牺牲战术可靠性和人员安全。

