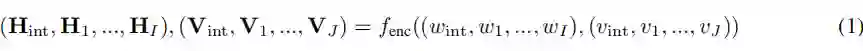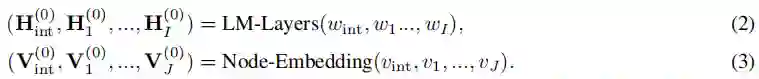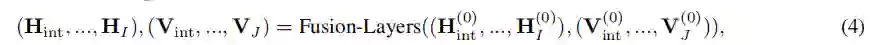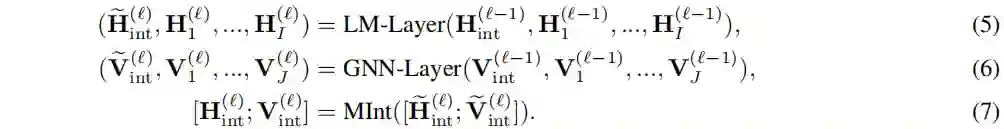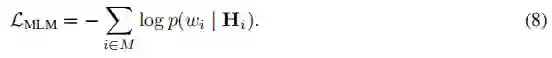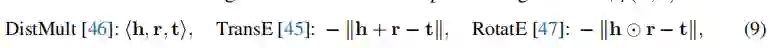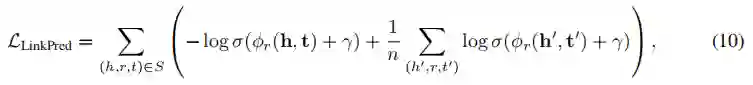编辑:夏忻焱
审稿:沈祥振
今天我们报道的是斯坦福大学Percy Liang&Jure Leskovec实验室发表在NeurIPS 2022上的文章《Deep Bidirectional Language-Knowledge Graph Pretraining》。作者提出了DRAGON (Deep Bidirectional Language-Knowledge Graph Pretraining)方法,它是一种自监督的方法,用于对文本和知识图谱进行大规模深度联合语言-知识基础模型的预训练。 具体来说,模型将文本段和相关KG(Knowledge Graph)子图的对作为输入,并双向融合来自两种模态的信息。作者通过联合两个自监督推理任务,掩码语言建模和KG链接预测,对该模型进行了预训练。DRAGON在多种下游任务(包括通用和生物医学领域的问答)上的表现优于现有的LM和LM+KG模型,绝对精度平均提高了+5%。特别是DRAGON在语言和知识的复杂推理(涉及长上下文或多步骤推理的问题+10% )和低资源QA (OBQA和RiddleSense +8% )方面取得了优异的表现,并在各种BioNLP任务中取得了最好的结果。

介绍
预训练从大量原始数据中学习自监督表示,以帮助各种下游任务。对大量文本数据(如BERT和GPTs)进行预训练的语言模型(LMs)在许多自然语言处理(NLP)任务中表现出了强大的性能。这些模型的成功来自于通过自监督大规模学习的输入令牌的深度交互(上下文化)表示。同时,Freebase、Wikidata、ConceptNet等大型知识图(KGs)可以为文本数据提供补充信息。KGs通过将实体表示为节点,将实体之间的关系表示为边,提供结构化的背景知识,还为实体的结构化、多步骤推理提供了支架。文本数据和KGs的双重优势促进了对这两种模式的大规模深度交互表示的预训练研究。
如何有效地结合文本和KGs进行预训练是一个开放的问题和挑战。给定文本和KG,需要(i)两个模态相互作用的深度双向模型,以及(ii)学习文本和KG在规模上的联合推理的自监督目标。已有的一些研究提出了自监督预训练的方法,但它们将文本和KG以一种浅显或单向的方式融合在一起。另一些工作提出了文本和KG的双向模型,但这些模型专注于对标记的下游任务进行finetuning,不执行自监督学习。因此,现有的方法可能限制了它们在模拟和学习文本和KG的深度交互方面的潜力。
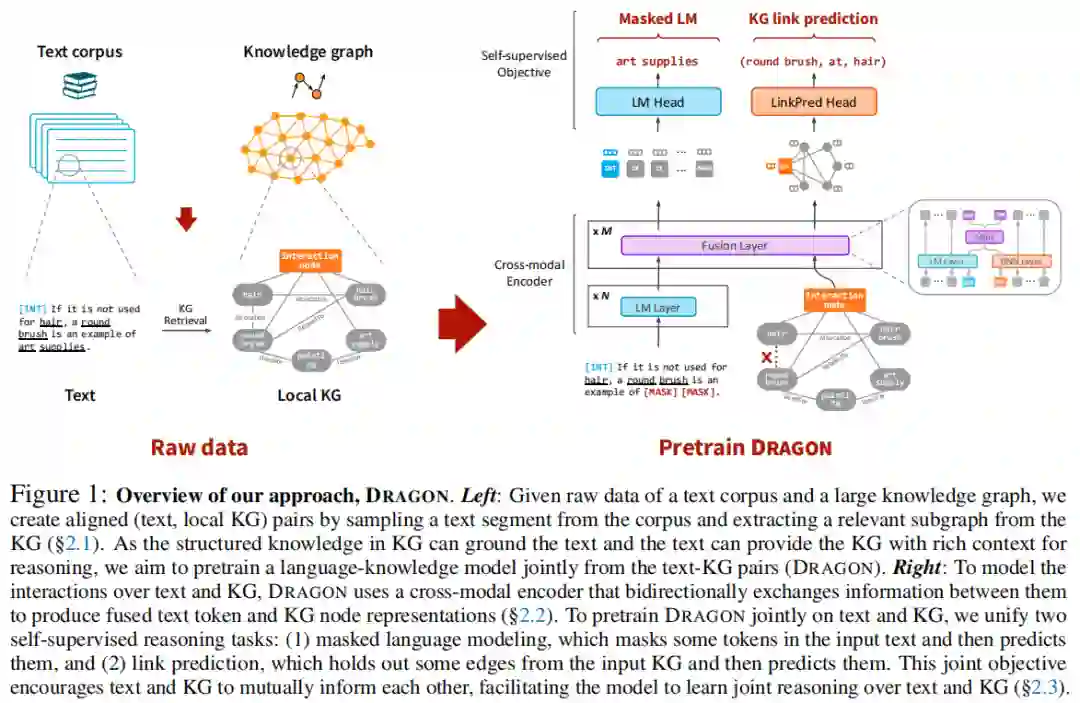
为了解决上述两个挑战,并充分联合文本和KG的优势,作者提出DRAGON(深度双向语言-知识图谱预训练),一种从text-KG对语言-知识模型进行深度双向、自监督的预训练的方法。DRAGON有两个核心组件:一个双向融合文本和KG的跨模态模型,一个双向学习文本和KG联合推理的自监督目标。具体地说,如图1所示,作者将一个文本语料库和一个KG作为原始数据,通过从语料库中采样一个文本段,并通过实体链接从KG中提取相关子图,为模型创建输入,从而获得(text,局部KG)对。作者使用跨模态模型将输入编码到融合表示中,其中模型的每一层使用LM编码文本,使用图神经网络(GNN)编码KG,并使用双向模态交互模块(GreaseLM)将两者融合。通过联合两个自监督推理任务,作者对该模型进行了预训练:(1)屏蔽语言建模(MLM),它屏蔽并预测输入文本中的令牌;(2)链接预测,它删除并预测输入KG中的边。结合两个任务的直觉是,模型利用文本与结构化知识共同来推理文本中屏蔽的令牌,链接预测让模型使用KG结构和文本上下文推断KG里消失链接。因此,这一联合目标使文本能够以KG结构为基础,而KG能够同时被文本语境化,产生一个深度统一的语言知识预训练模型,其中信息在文本和KG之间双向流动以进行推理。
作者在两个领域预训练DRAGON:一个是通用领域,使用Book语料库和ConceptNet KG[7],一个是生物医学领域,使用PubMed语料库和UMLS KG。作者展示了DRAGON在现有的LM和LM+KG模型的基础上改进了跨领域的各种下游任务。对于通用领域,在各种研究各种常识性推理任务如CSQA、OBQA、RiddleSense和HellaSwag等中,DRAGON的性能优于RoBERTa和没有KGs的基础LM,绝对精度平均提高了+8% 。在生物医学领域,DRAGON改进了之前最好的LM,BioLinkBERT。DRAGON还在BioNLP任务如MedQA和PubMedQA获得了最好结果,准确率提高了+3%。特别是,DRAGON在涉及复杂推理的QA任务(在多步骤、否定、对冲或长上下文推理上+10%)和在训练数据有限的下游任务(+8%)上表现出了显著的改进。这些结果表明,与现有模型相比,作者对文本和KG的深度双向自监督产生了显著改进的语言知识表示。
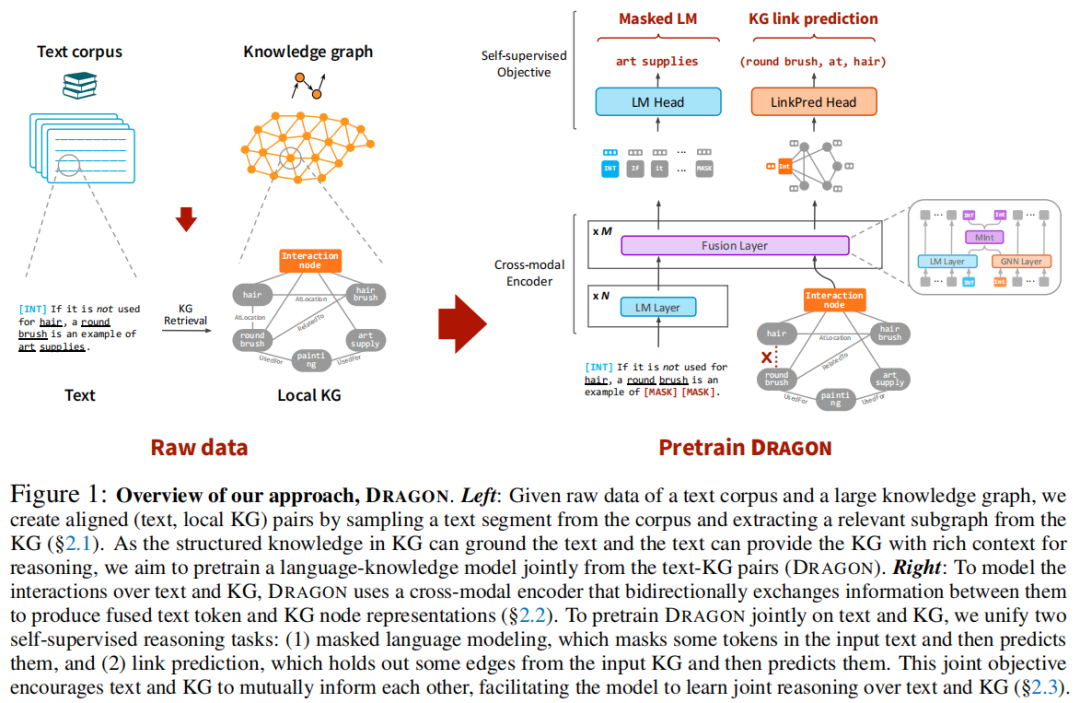
深度双向语言知识图谱预训练(DRAGON)
作者提出DRAGON,一种对文本和KG的语言知识模型进行深度双向、自监督的预训练的方法。具体来说,如图1所示,作者将一个文本语料库和一个大型知识图作为原始数据,并通过抽样粗对齐(文本段,局部KG)对(§2.1)为模型创建输入实例。为了学习文本和KG的相互作用,DRAGON由一个双向融合输入文本-KG对的跨模态编码器(GreaseLM)和一个对文本-KG输入进行双向自监督的预训练目标(§2.3)组成。作者的预训练目标将掩蔽语言建模(MLM)和KG链接预测(LinkPred)相结合,使文本和KG相互通知,并学习联合推理。最后,作者描述了如何为下游任务调整预先训练的DRAGON模型。虽然作者方法的每个单独部分(GreaseLM, MLM, LinkPred)本身并不新鲜,但作者是第一个将它们有效地结合在一起的人,并证明了所得到的模型具有强大的经验结果。

输入表示
给定一个文本语料库W和一个较大的知识图G,作者通过准备(文本段W,局部知识图谱 G)对来为模型创建输入实例。作者希望每对文本的文本和KG(大致)语义对齐,以便文本和KG可以相互告知,并促进模型学习两种模式之间的交互推理。
跨模态编码器
为了模拟文本和KG上的相互交互,作者使用的双向序列图编码器,它接收文本令牌和KG节点,并在它们之间交换信息,以产生每个令牌和节点的融合表示(图1右):
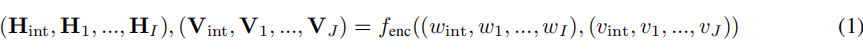
具体来说,GreeseLM首先使用N层变压器语言模型(LM)层将输入文本映射到初始标记表示,并使用KG节点嵌入将输入KG节点映射到初始节点表示
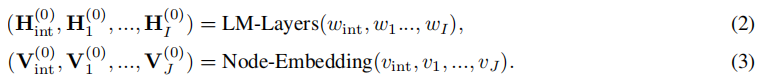
然后用M层的text-KG融合层来编码这些令牌/节点特征一起融入到最终的令牌/节点特征。
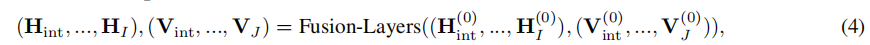
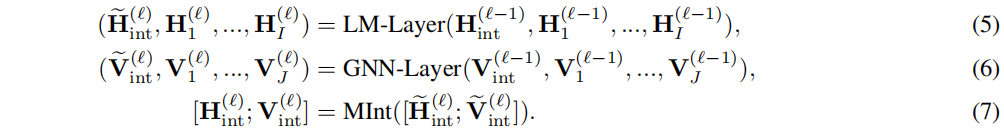
预训练目标
屏蔽语言模型(MLM)。作者用一个特殊的标记[MASK]屏蔽输入文本中的标记子集,并让任务头是一个线性层,从编码器中获取上下文化的标记向量{}来预测原始标记。目标是交叉熵损失:
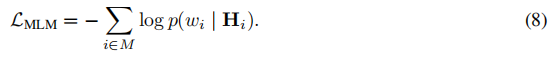
链接预测(LinkPred)。具体地说,为了执行链接预测任务,作者从输入KG中得到一个边三联体的子集。对于任务头部,作者采用KG表示学习框架,它将每个实体节点(h或t)和关系(r)映射到一个向量,,并定义了一个评分函数来建模正/负三联体样本。具体地说,作者让其中{}是来自编码器的上下文化节点向量,而是可学习的关系嵌入。考虑一个KG三重评分函数,如
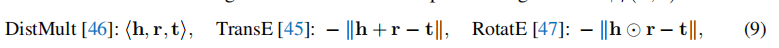
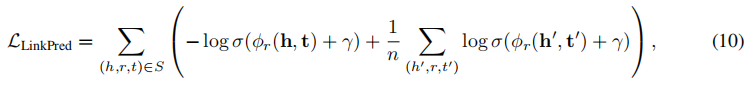
实验:一般领域
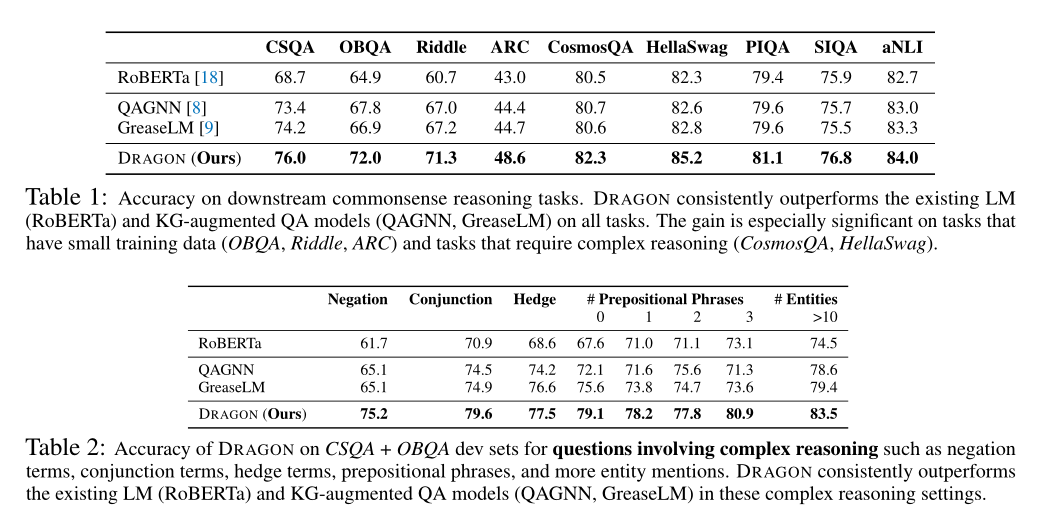
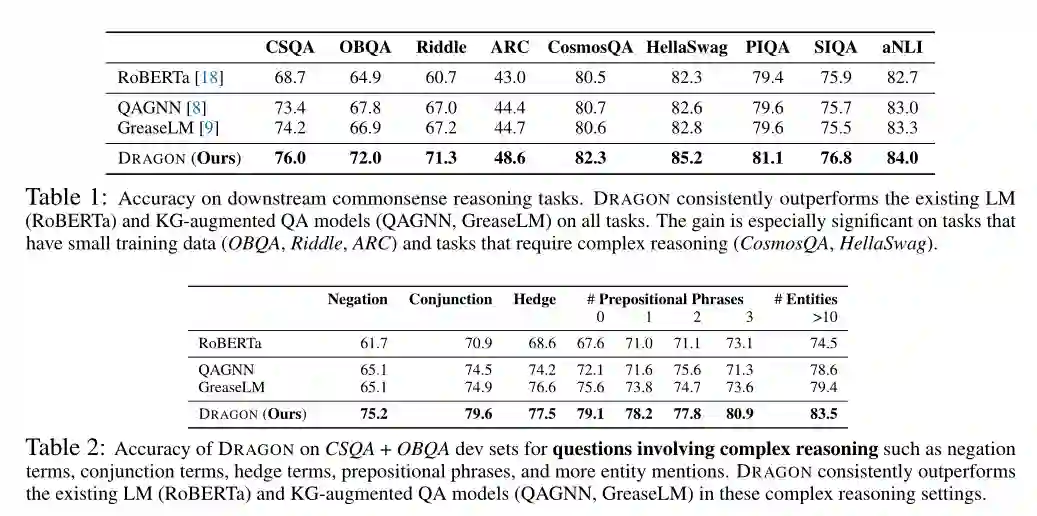
表1显示了9个下游常识推理任务的性能。在所有任务中,DRAGON始终优于现有的LM (RoBERTa)和KG-augmented QA模型(QAGNN, GreaseLM),例如,在RoBERTa上,绝对精度提高了7%,在OBQA上,比GreaseLM提高了5%。这些准确性的提高表明DRAGON相对于RoBERTa (KG推理)和GreaseLM(预训练)的优势。对于具有少量训练数据的数据集(如ARC、Riddle和OBQA),以及需要复杂推理的数据集(如CosmosQA和HellaSwag),这种增益尤其显著,作者将在以下部分详细分析这些数据集。
分析:知识图谱的作用
DRAGON 的第一个关键贡献是利用了KG,作者发现这显著提高了模型在鲁棒和复杂推理方面的性能。
定量分析。在表2中,作者研究了DRAGON在涉及复杂推理的问题上的下游任务表现。作者考虑了几个代理来对复杂问题进行分类:(i)是否存在否定(例如no, never), (ii)是否存在连词(例如and, but), (iii)是否存在套语(例如sometimes, maybe), (iv)介词短语的数量,以及(v)实体提到的数量。有否定或连接表示逻辑上的多步骤推理,有更多的介词短语或实体提及表示涉及更多的推理步骤或约束,有套语表示涉及复杂的文本细微差别。DRAGON在所有这些类别上的表现都明显优于基线LM (RoBERTa)(例如,否定的准确率为+14%),这证实了作者的联合语言知识预训练提高了推理能力。DRAGON也始终优于现有的KG-augmented QA模型(QAGNN, GreaseLM)。作者发现QAGNN和GreaseLM只在某些类别如连词或许多介词短语(= 2,3)上在RoBERTa上有适度的提高,但DRAGON提供了实质性的提高。这表明,通过使用更大、更多样化的数据进行自监督的预训练,DRAGON比只进行微调的模型(如GreaseLM)学习了更多通用推理能力。
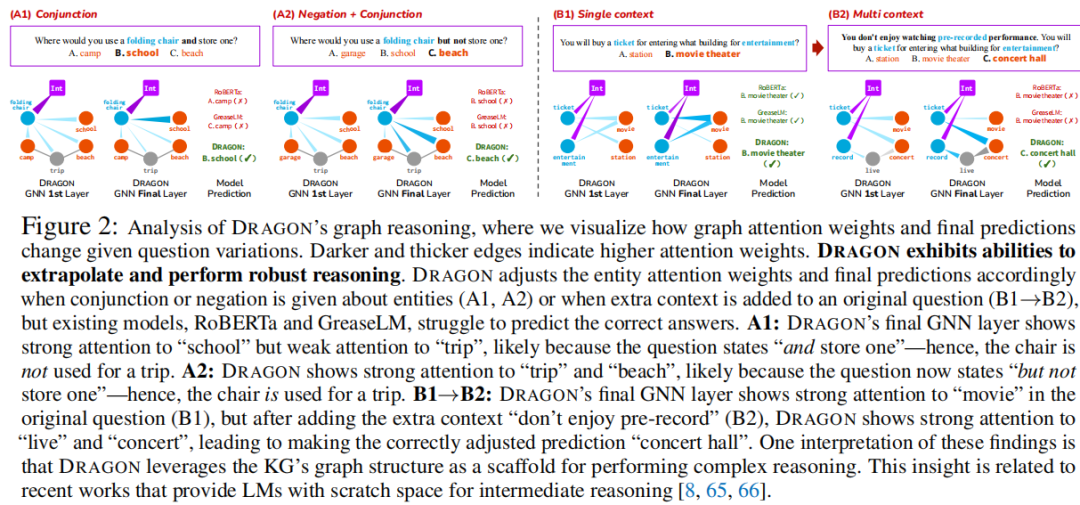
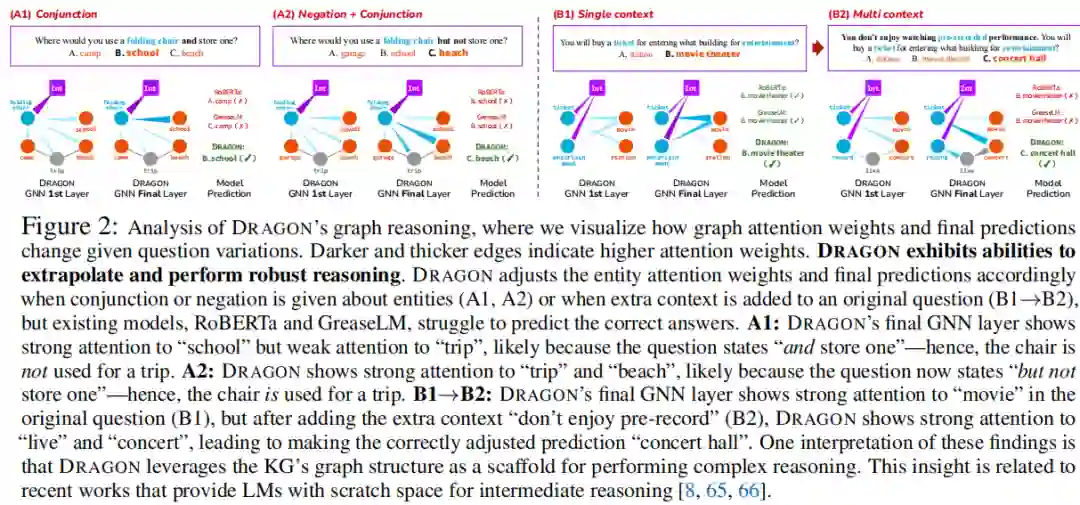
定性分析。使用CSQA数据集,作者进一步对DRAGON的KG推理组件的行为进行了案例研究,其中作者可视化了在不同问题变化下图注意权重的变化(图2)。发现DRAGON展示了推断和执行鲁棒推理的能力。由于这些问题比通常在CSQA训练集中看到的问题更复杂,作者的见解是,当普通LM(RoBERTa)和微调(GreaseLM) 在学习复杂推理方面有局限性时,kg增强的预训练(DRAGON)有助于获得可推广的推理能力,从而推断到更难的测试示例。
分析:预训练的作用
DRAGON的另一个关键贡献是预训练(与GreaseLM等现有QA模型相比)。在这里,作者讨论一下什么时候以及为什么预训练是有用的。考虑到机器学习中的三个核心因素(数据、任务复杂度和模型容量),当可用的下游任务数据小于下游任务复杂度或模型容量时,预训练是有帮助的。具体地说,作者发现DRAGON对于以下三个场景特别有帮助。
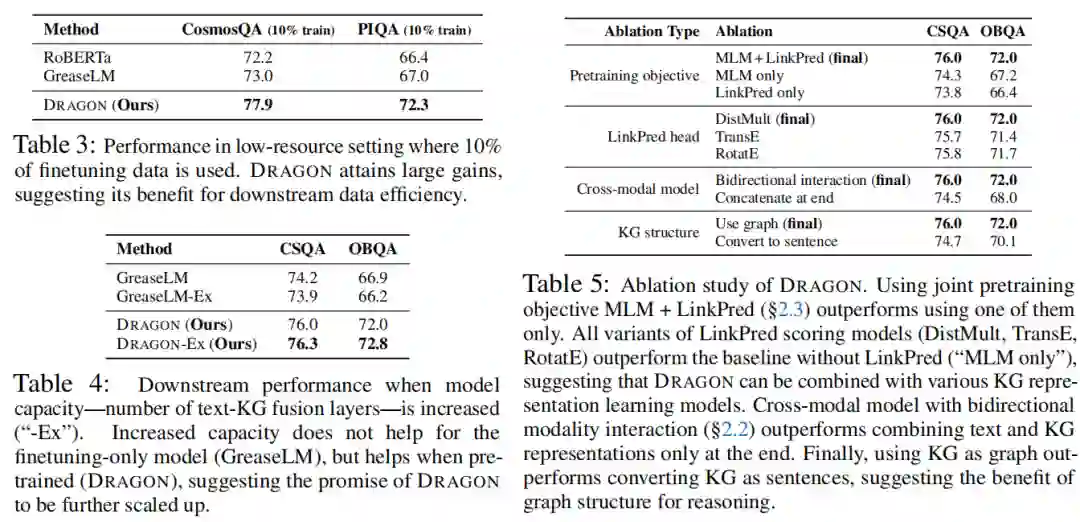
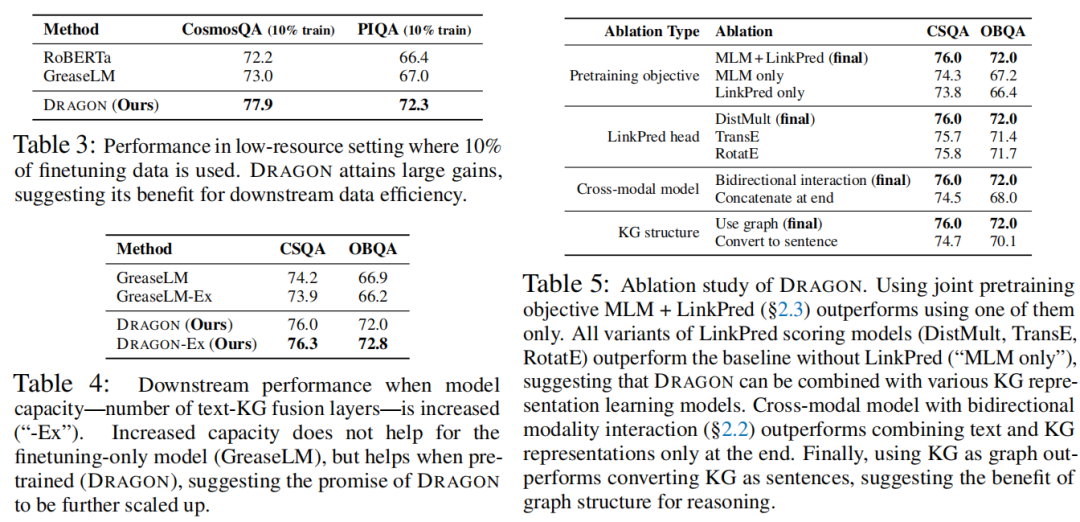
数据有限的下游任务。在表1中,作者发现DRAGON在下游任务中比GreaseLM提供了显著的提升,但可用的微调数据有限,例如ARC (3K训练实例;+4%的精度增益),谜语(3K实例;+4%精度)和OBQA (5K实例;+ 5%的准确率)。对于其他任务,作者也在低资源设置下进行了实验,其中使用了10%的微调数据(表3)。在这里,可以看到DRAGON比GreaseLM获得了显著的增益(PIQA上+5%的精度),这表明DRAGON提高了数据效率。
复杂的下游任务。在表1中,作者发现DRAGON在涉及更复杂推理的下游任务(如CosmosQA和HellaSwag)上比GreaseLM取得了实质性的进步,这些任务的输入具有更长的上下文和更多的实体(因此更大的局部KG)。对于这些任务,GreaesLM相对于RoBERTa的改进很小(CosmosQA +0.1%),但DRAGON提供了实质性的提升(+1.8%)。作者的见解是,通过使用8个更大、更多样化的数据进行自监督预训练,DRAGON已经学会了比GreaseLM更丰富的text-KG交互,能够解决更复杂的下游任务。类似地,DRAGON在包含否定、连词和介词短语的复杂问题上也比GreaseLM取得了较大的进步(表2),并推断出比训练集更复杂的问题(图2)。
增加了模型容量。在表4中,作者研究了当模型容量增加时(text-KG融合层数从5层增加到7层),GreaseLM和DRAGON的下游性能。作者发现,正如在最初的GreaseLM论文中所报告的那样,增加的容量对仅微调模型(GreaseLM)没有帮助,但在预训练时(DRAGON)有帮助。这一结果表明,当与预训练相结合时,增加的模型容量实际上是有益的,并表明DRAGON的前景将进一步扩大。
分析:DRAGON的设计选择
预训练目标(表5顶部)。DRAGON的第一个重要设计选择是联合预训练目标:MLM + LinkPred。使用联合目标的效果要优于单独使用MLM或LinkPred (OBQA +5%的精度)。这表明,文本和KG的双向自监督任务有助于模型融合两种推理模式。
链接预测头选择(表5中间1)。KG表示学习是一个活跃的研究领域,提出了各种KG三元组评分模型(公式9)。因此,作者对DRAGON的链接预测头使用不同的评分模型进行了实验。发现,虽然DistMult有轻微的优势,但作者尝试的所有变体(DistMult, TransE, RotatE)都是有效的,优于没有LinkPred的基线(“仅MLM”)。这一结果表明DRAGON的普遍性以及它与各种KG表示学习技术相结合的前景。
跨模态编码器(表5中间2).DRAGON的另一个核心组件是具有双向text-KG融合层的跨模态编码器。作者发现,如果消除它们,并在最后简单地连接文本和KG表示,性能将大幅下降。这一结果表明,深度双向融合对于模拟文本和KG之间的交互是至关重要的。
KG结构(表5底部)。DRAGON的最终关键设计是通过序列图编码器和链接预测目标利用KGs的图结构。在这里,作者尝试了一种替代的预训练方法,它去掉了图结构:我们使用模板将本地KG中的三连词转换为句子,将它们附加到主要文本输入中,并执行普通的MLM预训练。作者发现DRAGON的表现远远优于这个变体(OBQA上+2%的准确性),这表明KG的图结构有助于模型进行推理。 实验:生物医学领域
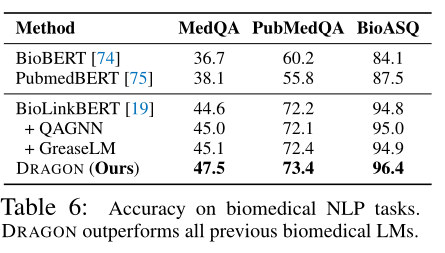
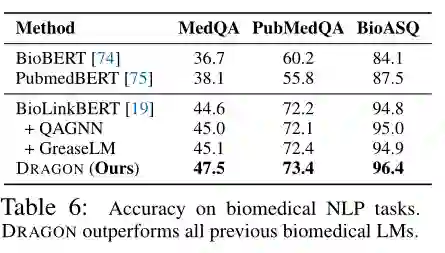
表6总结了下游任务上的模型性能。在任务中,DRAGON优于所有现有的生物医学LM和KG-augmented QA模型,例如,在BioLinkBERT上的绝对精度提高了3%,在MedQA上的绝对精度提高了2%,在这些任务中实现了新的最先进的性能。这一结果表明,KG增强预训练对提高生物医学推理任务有显著的效果。结合一般常识域的结果,作者的实验还表明DRAGON具有域的通用性,可以作为一种有效的预训练方法,跨越具有不同文本、KGs和seed LM组合的域。 结论
作者提出了DRAGON,一种自监督的预训练方法,从文本和知识图(KGs)中学习深度双向的语言知识模型。在通用和生物医学领域,DRAGON在各种NLP任务上都优于现有的语言模型和KG-augmented模型,并在回答涉及长上下文或多步骤推理的问题等复杂推理方面表现强劲。
DRAGON的一个限制是它目前是一个编码器模型(类似于BERT),不执行语言生成。未来的一个重要研究将是将DRAGON扩展到生成,并推进KG增强的语言生成。 参考资料 Yasunaga M, Bosselut A, Ren H, et al. Deep Bidirectional Language-Knowledge Graph Pretraining[J]. NeurIPS 2022.
代码链接: