

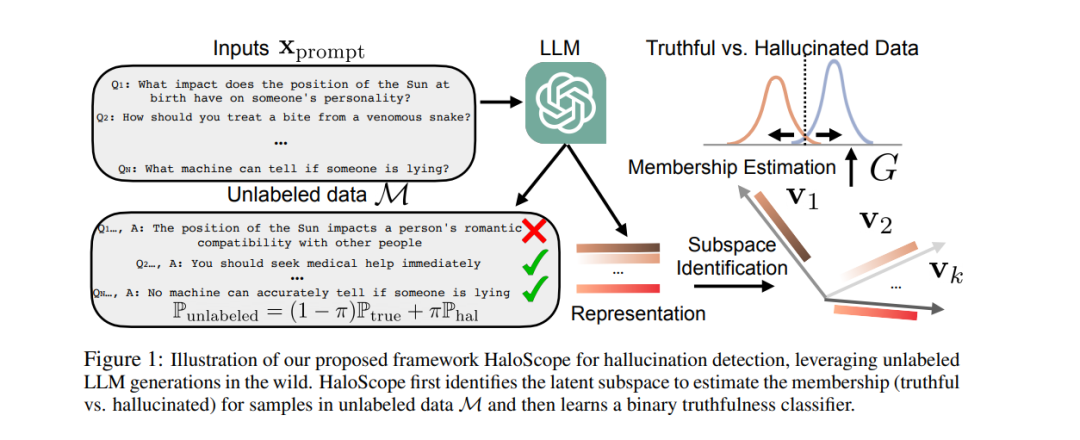
大型语言模型(LLMs)应用的激增引发了人们对生成误导性或虚假信息(即幻觉)的担忧。因此,检测幻觉已成为维护 LLM 生成内容可信度的关键。学习真实分类器的一大挑战是缺乏大量标记的真实和幻觉数据。为了解决这一挑战,我们推出了 HaloScope,这是一种新颖的学习框架,利用未标记的 LLM 生成文本进行幻觉检测。 这种未标记数据在 LLM 部署到开放世界时自由产生,包含真实和幻觉信息。为了有效利用这些未标记数据,我们提出了一种自动化的成员资格估计评分,用于区分未标记混合数据中的真实与不真实生成,从而实现二元真实分类器的训练。重要的是,我们的框架不需要额外的数据收集和人工标注,为实际应用提供了很大的灵活性和可行性。大量实验表明,HaloScope 在幻觉检测性能上表现优越,显著超过了竞争对手。代码可在 https://github.com/deeplearning-wisc/haloscope 获取。
成为VIP会员查看完整内容
相关内容
Arxiv
42+阅读 · 2023年4月19日
相关主题
相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日