编译 | 曾全晨
审稿 | 王建民 今天为大家介绍的是来自Tal Golan团队的一篇论文。语言模型似乎越来越符合人类处理语言的方式,但通过对抗性示例来识别它们的弱点十分具有挑战性,因为语言是离散的,并且人类语言感知非常复杂。

神经网络语言模型不仅是自然语言处理(NLP)中的关键工具,还因其潜在成为人类语言处理模型的可能性而引起了越来越多的科学兴趣。从循环神经网络(RNNs)到变换器(transformers)等各种语言模型,每个模型(显式或隐式地)都定义了一个关于单词序列的概率分布,预测哪些序列在自然语言中可能出现。从阅读时间、功能性磁共振成像(fMRI)、头皮脑电图、颅内脑电图(ECoG)等测量结果来看,存在大量证据表明,人类对由语言模型捕获的单词和句子的相对概率敏感。模型推导的句子概率还可以预测人类可接受性。然而,这些成功尚未解决两个关键问题:(1)哪个模型与人类语言处理最为一致,以及(2)最佳对齐模型与完全捕捉人类判断的目标有多接近?评估语言模型的主要方法之一是使用一组标准化基准,例如通用语言理解评估(GLUE)或其继任者SuperGLUE。尽管这些基准在评估语言模型在下游NLP任务中的实用性方面起到了关键作用,但它们在将这些模型作为解释人类语言处理的候选模型进行比较方面显然不够充分。一些基准通过比较语言模型分配给合乎语法和不合乎语法句子的概率(例如BLiMP)来评测语言模型。然而,由于这些基准受到理论语言学考虑的驱动,它们可能无法检测到语言模型可能从人类语言中学习到的新颖的表达方式。最后,另一个实际的问题是NLP研究的快速发展导致这些类型的静态基准迅速饱和,使得难以区分不同模型之间的性能。
针对这些问题的一个解决方案是使用动态的人机协同基准测试,其中人们积极地对模型进行一系列不断演化的测试以进行强化测试。然而,这种方法面临一个重大障碍,随着测试案例的增加,人们会发现越来越难找到新颖和有趣的测试案例,以便真正挑战语言模型的性能。。作者提议将人工策划的基准测试与模型驱动的评估相结合。在模型的预测指导下,而不是实验者的直觉,我们希望识别特别信息丰富的测试句子,其中不同的模型会做出不同的预测。我们可以在大量自然语言的语料库中找到这些关键句子,或合成新的测试句子,以揭示不同模型在其训练分布之外的泛化方式。
在文中,作者提出了一种系统的、以模型为驱动的方法,用于比较语言模型在与人类判断一致性方面的性能。作者生成了有争议的句子对,这些句子经过设计,使得两个语言模型在哪个句子更可能出现方面存在强烈分歧。然后,作者收集人类的判断,以确定每对句子中哪个更有可能,以解决这两个模型之间的争议。
实验概述
作者从进行在线测试的100名以英语为母语的参与者那里获得了评判。在每个实验试验中,参与者被要求判断两个句子中哪一个他们“更有可能在现实世界中遇到,无论是口语还是书面文本”,并在一个三级别的信心评级上提供他们答案的信心值。该实验旨在比较九种不同的语言模型:基于两个词组和三个词组序列的的词频概率模型以及一系列神经网络模型,包括RNN、长短时记忆网络(LSTM)和五个transformer模型(BERT、RoBERTa、XLM、ELECTRA和GPT-2)。
使用有争议的自然数据对,进行高效的模型比较
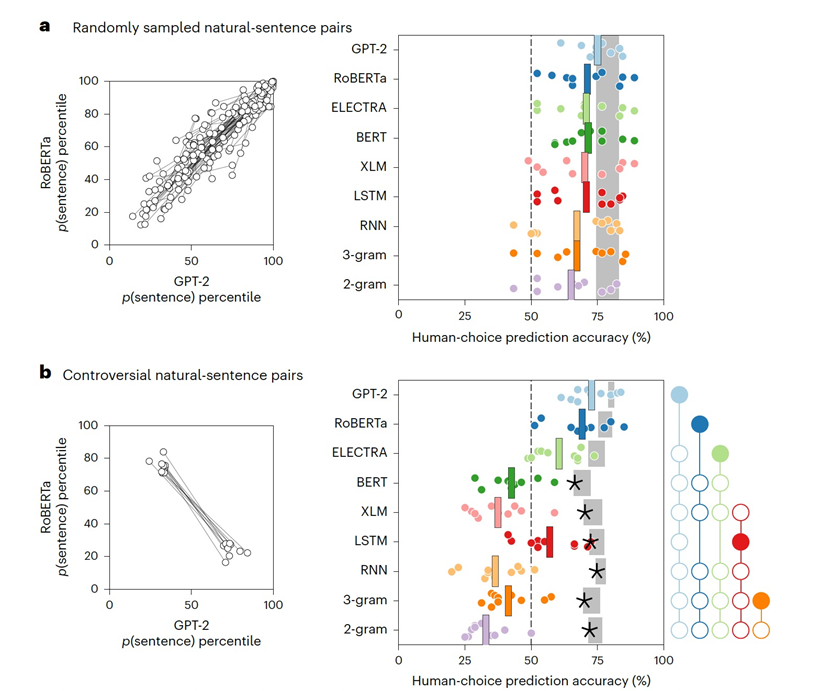
图1
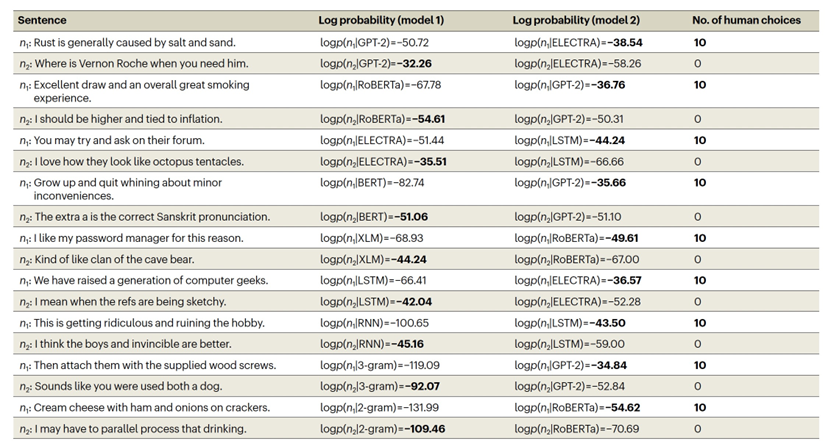
表 1
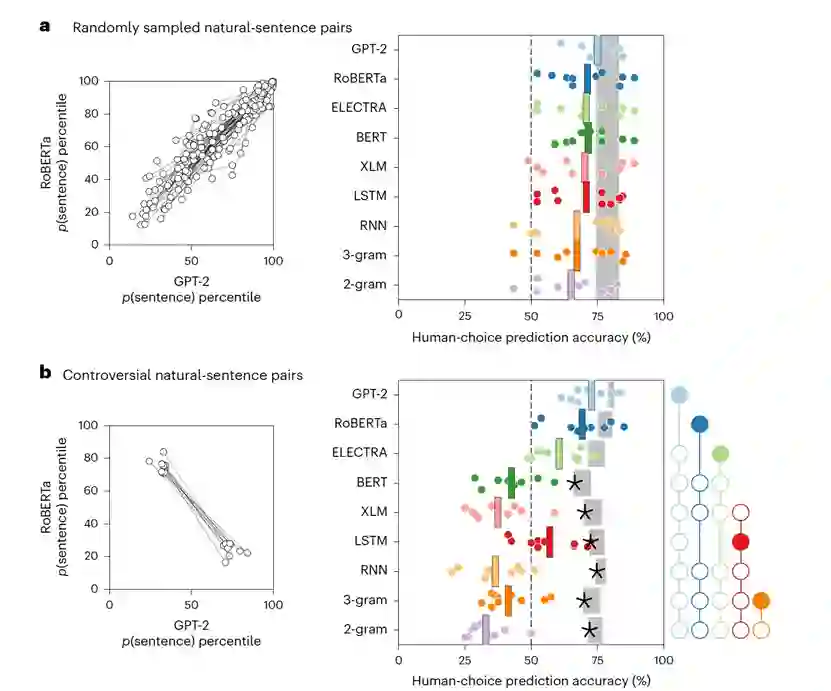
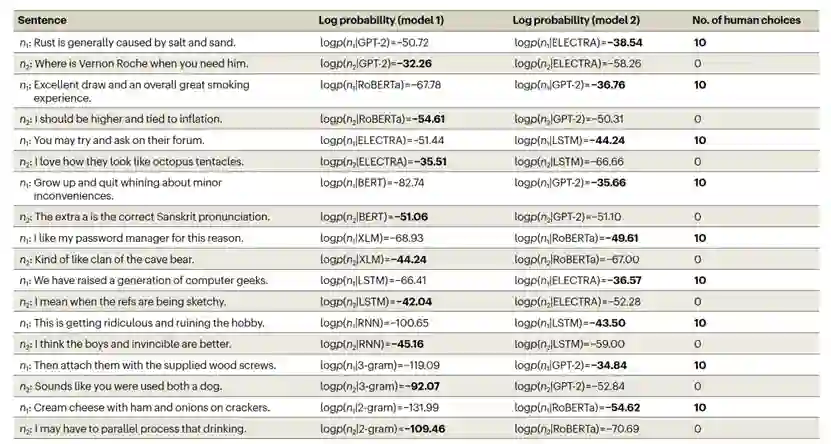
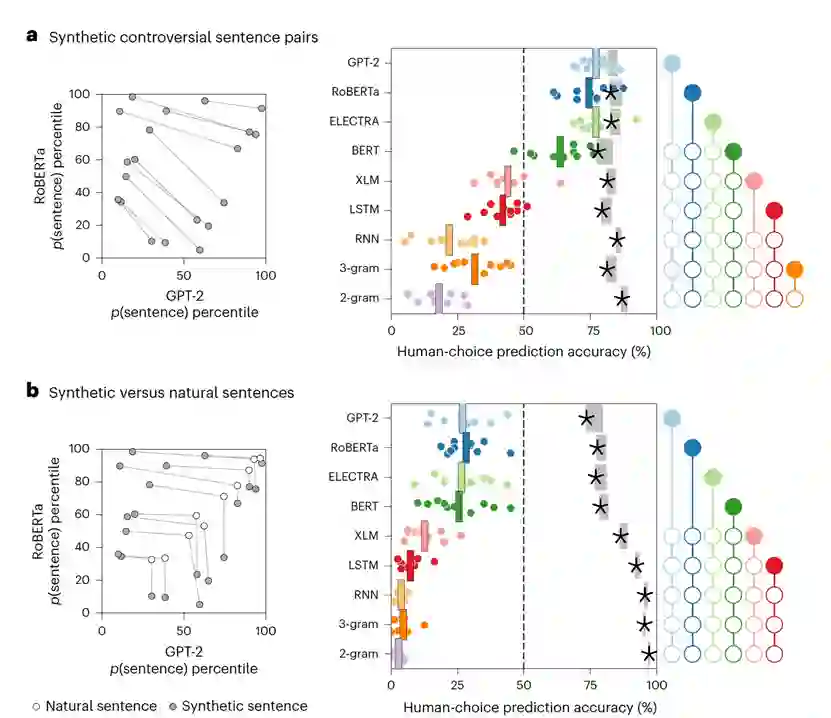
作为基准线,作者从Reddit评论语料库中随机抽样并配对了八个词的句子。然而,如图1a所示,这些句子未能揭示模型之间的有意义的差异。对于每一对句子,所有模型都倾向于偏好相同的句子,因此在预测人类偏好评分方面表现相似。相反,可以使用一个优化过程来搜索有争议的句子对,其中一个语言模型仅为句子1分配高概率,而第二个语言模型仅为句子2分配高概率(示例见表1)。不同的语言模型在预测人类在特定句子对上的选择时,显示出在与人类的一致性方面存在许多显著差异(如图1b所示),其中GPT-2和RoBERTa显示出最好的人类一致性。 使用合成句子对,实现更大程度的模型分离
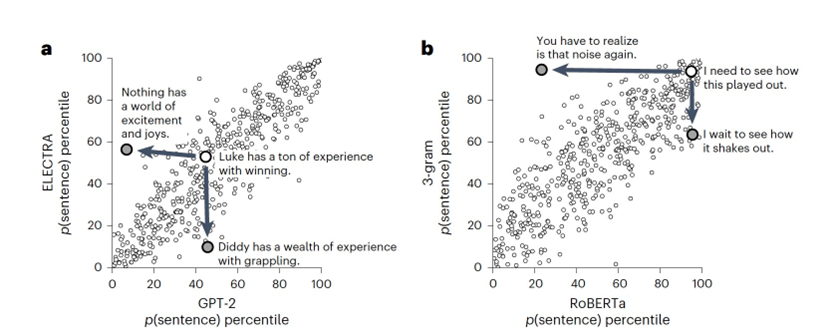
图 2
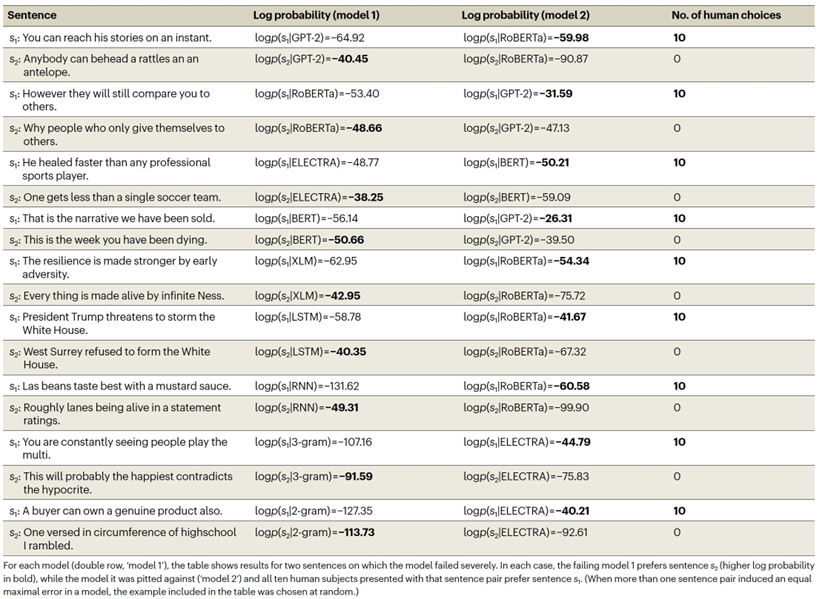
表 2
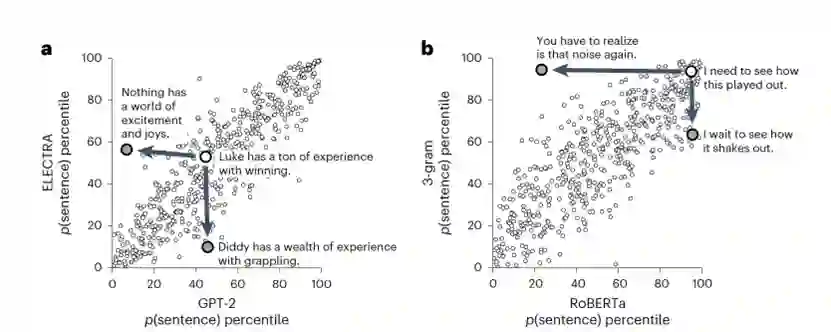
选择有争议的自然句子对可能比随机抽样自然句子对提供更大的能力,但这个搜索过程只考虑了可能的句子对空间的非常有限的部分。相反,我们可以迭代地替换自然句子中的单词,以驱使不同的模型产生相反的预测,形成合成的有争议句子,这些句子可能位于任何自然语言语料库之外,如图2所示。作者展示了合成的有争议句子对,如表2所示。
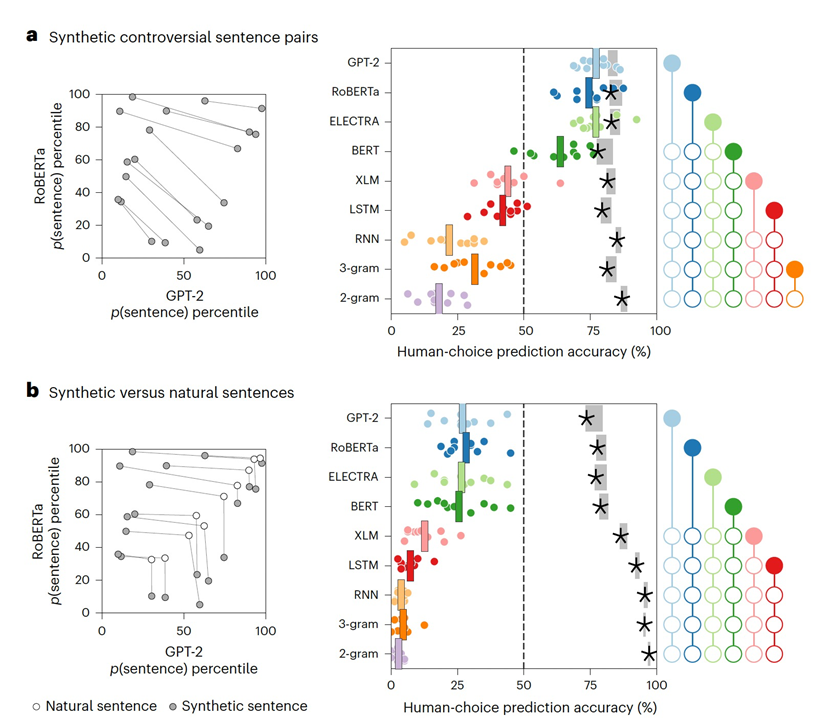
图 3
作者评估了每个模型在所有有争议的合成句子对中对人类句子选择的预测准确度(图3a)。这种模型与人类的一致性评估方式,导致了模型的预测准确度之间的差距更大,使较弱的模型(RNN、3-gram和2-gram)远低于50%的随机准确度水平。在这些试验中,GPT-2、RoBERTa和ELECTRA在预测人类的响应方面明显比其他模型(BERT、XLM、LSTM、RNN、3-gram和2-gram)更准确。
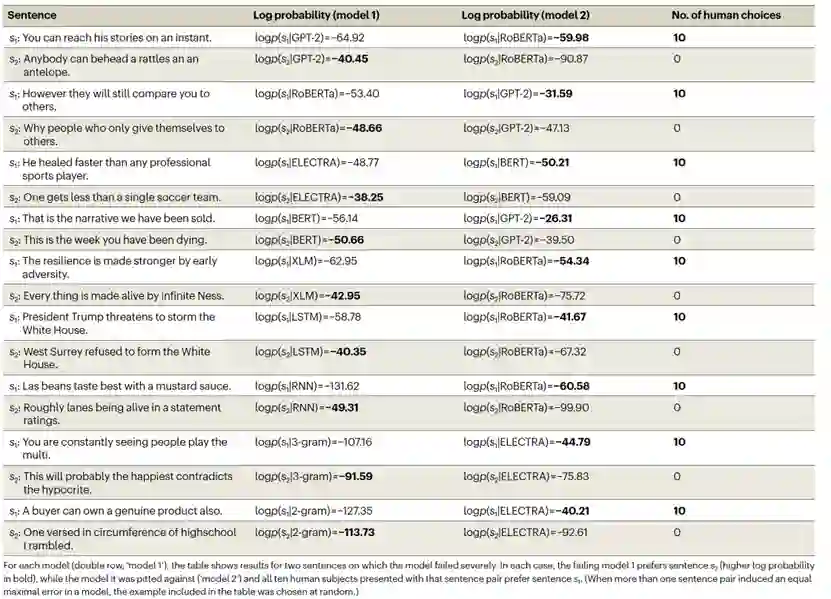
自然句子和合成句子的组合揭示了盲点 最后,作者考虑了那些要求参与者在自然句子和合成句子之间选择的试验。如果语言模型与人类判断完全一致,作者期望人类会同意模型,并至少与自然句子一样多地选择合成句子。然而,在现实中,人类参与者明显更偏好自然句子而不是它们的合成对应物(图3b),即使合成句子是针对更强大的模型(即GPT-2、RoBERTA或ELECTRA)而生成。针对每个模型对分别评估自然句子的偏好,作者发现即使将一个强模型与一个相对较弱的模型配对(以至于强模型接受合成句子而弱模型拒绝它),也可以揭示这些缺点。
评估整个数据集揭示了模型的层次结构
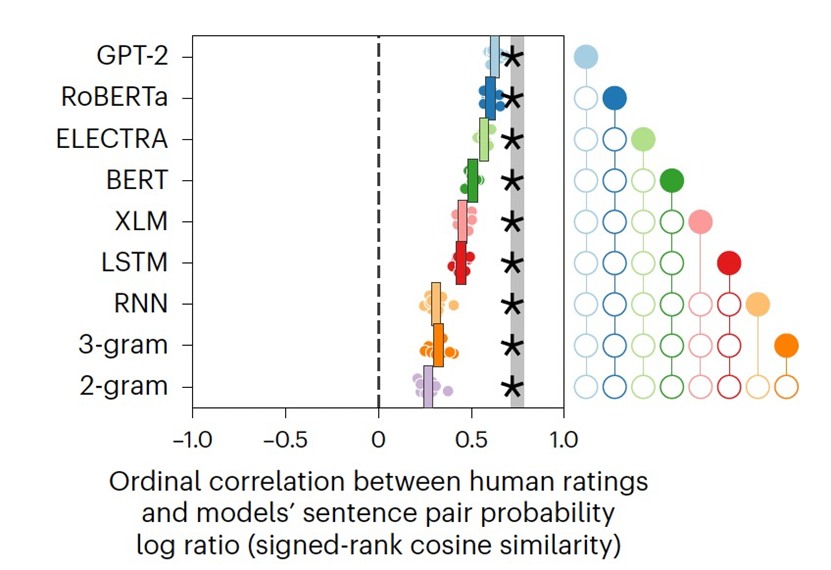
图 4
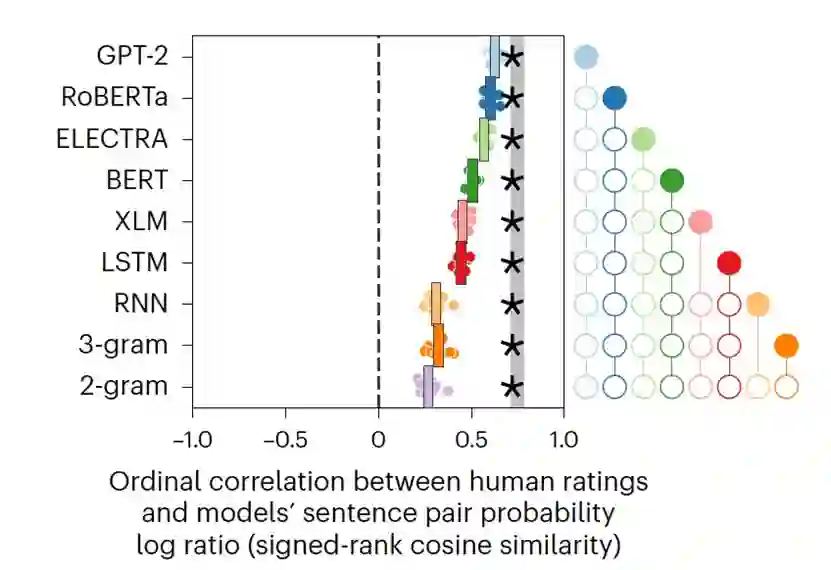
与评估每个模型的预测准确性相比,针对用于比较这个模型与替代模型的特定句子对,作者通过计算每个模型对所有收集到的实验的平均预测准确性来最大化对于模型的评测能力。此外,作者在这里测量了分级人类选择(考虑信心)与每个候选模型分配的句子概率的对数比率之间的序数对应关系。使用这个更敏感的基准(图4),作者发现GPT-2与人类最一致,其次是RoBERTa,然后是ELECTRA、BERT、XLM和LSTM,以及RNN、3-gram和2-gram模型。造成双向transformer(RoBERTa、ELECTRA、BERT和XLM)性能较差的一个可能原因是,与单向transformer(GPT-2)相比,这些模型中的句子概率计算较为复杂。作者开发的概率估计器也可能不是最优的;事实上,伪对数似然(PLL)方法在随机抽样的自然句子对上提供了稍高的准确性。然而,当作者通过生成新的合成的有争议的句子来直接比较当前采用的估计器与PLL时,发现作者的估计器更好地与人类判断一致。 参考资料 Golan, T., Siegelman, M., Kriegeskorte, N. et al. Testing the limits of natural language models for predicting human language judgements. Nat Mach Intell (2023). https://doi.org/10.1038/s42256-023-00718-1