

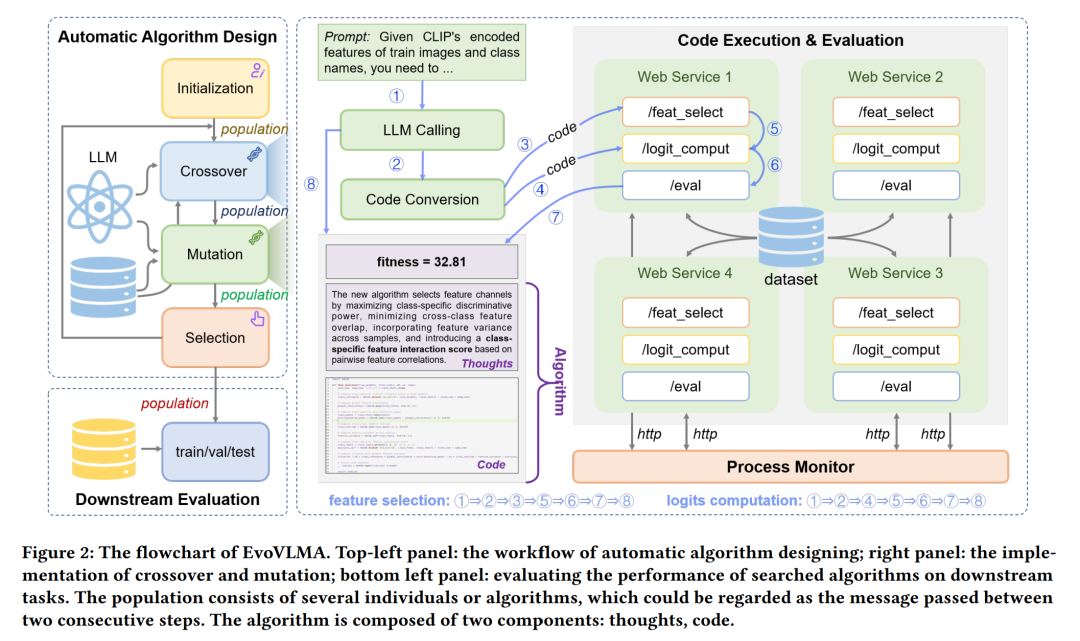
预训练的视觉-语言模型(Vision-Language Models, VLMs)已被广泛应用于各类计算机视觉任务(如小样本识别),通常通过模型自适应技术(如 prompt tuning 和 adapter)来实现。然而,现有的自适应方法大多由人类专家设计,既耗时又依赖经验。受近期大语言模型(Large Language Models, LLMs)在代码生成方面进展的启发,我们提出了一种进化式视觉-语言模型自适应方法(Evolutionary Vision-Language Model Adaptation, EvoVLMA),用于自动搜索免训练的高效 VLM 自适应算法。 我们将特征选择与logits 计算识别为免训练 VLM 自适应中的关键功能模块,并提出了一种基于大语言模型辅助的两阶段进化算法,按序优化这两个部分。该方法通过“分而治之”的策略,有效应对了庞大搜索空间带来的挑战。 此外,为了提高搜索过程的稳定性与效率,我们引入了低精度代码转换、基于 Web 的代码执行机制和过程监控机制,共同构建出一个高效的自动算法设计系统。大量实验表明,EvoVLMA 所发现的算法在性能上优于以往的手工设计方法。例如,在 8-shot 图像分类设置下,经典的 APE 算法在识别准确率上可提升 1.91 个百分点。 本研究为预训练多模态模型的自适应算法优化自动化开辟了新的可能性。项目代码已开源,地址为: https://github.com/kding1225/EvoVLMA
成为VIP会员查看完整内容
相关内容

ACM 国际多媒体大会(英文名称:ACM Multimedia,简称:ACM MM)是多媒体领域的顶级国际会议,每年举办一次。
Arxiv
41+阅读 · 2023年4月19日
Arxiv
215+阅读 · 2023年4月7日
Arxiv
88+阅读 · 2021年10月21日
相关主题
相关VIP内容
相关资讯
相关论文
Arxiv
41+阅读 · 2023年4月19日
Arxiv
215+阅读 · 2023年4月7日
Arxiv
88+阅读 · 2021年10月21日