随着数据孤岛现象的出现和个人隐私保护的重视,集中学习的应用模式受到制约,而联邦学习作为一个分布式机器学习框架,可以在不泄露用户数据的前提下完成模型训练,从诞生之初就备受关注.伴随着联邦学习应用的推广,其安全性和隐私保护能力也开始受到质疑.本文对近年来国内外学者在联邦学习模型安全与隐私的研究成果进行了系统总结与分析.首先,介绍联邦学习的背景知识,明确其定义和工作流程,并分析存在的脆弱点.其次,分别对联邦学习存在的安全威胁和隐私风险进行系统分析和对比,并归纳总结现有的防护手段.最后,展望未来的研究挑战和方向.
近年来机器学习(machine learning)技术蓬勃发展,在社会工作生活各个领域中得到广泛应用,如人脸识别、 智慧医疗和自动驾驶等,并取得巨大的成功.机器学习的目标是从大量数据中学习到一个模型,训练后的模型可 以对新的未知数据预测结果,因此模型的性能与训练数据的数量和质量密切相关.传统的机器学习应用基本都 采取集中学习[1]的模式,即由服务提供商集中收集用户数据,在服务器或数据中心训练好模型后,将模型开放给 用户使用.但是,目前存在两大要素制约了集中学习的进一步推广:
**(1) 数据孤岛 **
随着信息化、智能化进程的发展,各个企业或同一企业的各个部门都存储了大量的应用数据,但是数据的定义和组织方式都不尽相同,形成一座座相互独立且无法关联的“孤岛”,影响数据的流通和应用.数据集成整合 的难度和成本严重限制了集中学习的推广应用.
**(2) 个人隐私保护的重视 **
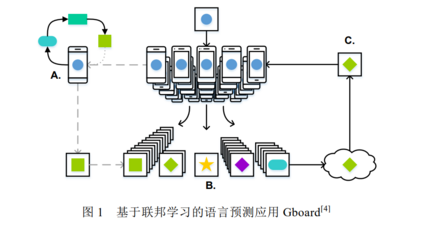
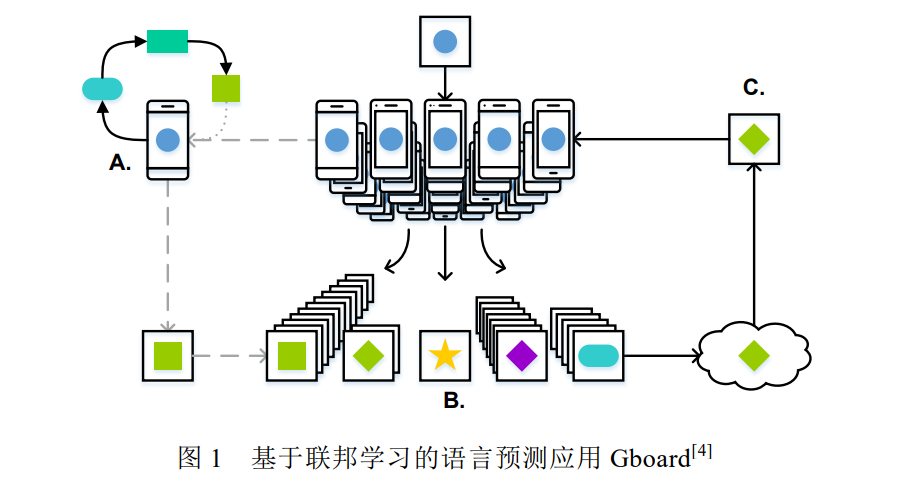
近年来,个人数据泄露的事件层出不层,如 2018 年 Facebook 数据泄露事件等.这些事件引起了国家和公众 对于个人隐私保护的关注.各个国家都开始出台数据隐私保护相关的法律法规,如欧盟 2018 年 5 月 25 日出台 的《通用数据保护条例》(General Data Protection Regulation,简称 GDPR) [2],以及中国 2017 年实施的《中华人 民共和国网络安全法》等.这些法律法规要求公司企业必须在用户同意的前提下才可以收集个人数据,且需要 防止用户数据泄露.此外,个人隐私保护意识的兴起也导致用户不愿轻易共享自己的隐私数据.严格的法律法规 和个人隐私保护意识导致训练数据的收集愈发困难,为集中学习提出了巨大的挑战. 为应对上述两个问题,联邦学习(federated learning)应运而生.联邦学习,又名联盟学习或联合学习,是一种 由多个客户端和一个聚合服务器参与的分布式机器学习架构.客户端既可以是个人的终端设备(如手机等),也 可以代表不同的部门或企业,它负责保存用户的个人数据或组织的私有数据.客户端在本地训练模型,并将训练 后的模型参数发送给聚合服务器.聚合服务器负责聚合部分或所有客户端的模型参数,将聚合后的模型同步到 客户端开始新一轮的训练.这种联合协作训练的方式可以在保证模型性能的前提下,避免个人数据的泄露,并有 效解决数据孤岛的问题. 联邦学习自 2016 年谷歌[3]提出后便引起学术界和工业界的强烈关注,并涌现出许多实际应用,如谷歌最初 将其应用在安卓手机上的 Gboard APP(the Google Keyboard,谷歌键盘输入系统),用于预测用户后续要输入的内 容(如图 1 所示) [4].用户手机从服务器下载预测模型,基于本地用户数据进行训练微调,并上传微调后的模型参 数,不断优化服务器的全局模型.此外,联邦学习也被广泛应用于工业[5,6]、医疗[7–11]和物联网[12]等领域.
随着联邦学习的发展应用,其安全性与隐私性逐渐引起学术界的关注.与集中学习相比,联邦学习的模型参 数共享和多方通信协作机制引入了新的攻击面.近年来,许多学者对联邦学习的安全威胁进行深入研究,提出一 系列攻击手段和防护方案.除安全性外,学者也发现联邦学习存在诸如成员推断攻击等隐性泄露的风险.这些将 严重影响联邦学习的实际部署应用,因此本文对目前联邦学习模型的安全与隐私研究工作进行系统地整理和 科学地归纳总结,分析联邦学习面临的安全隐私风险及挑战,为后续学者进行相关研究时提供指导.
本文第 1 节主要介绍联邦学习的背景知识,明确其定义和工作流程,并分析其存在的脆弱点.第 2 节对联邦 学习存在的安全威胁进行系统地整理和分析,归纳现有的防护方法,并对集中学习和联邦学习在安全问题上的 共性与差异进行分析.第 3 节总结联邦学习的隐私风险以及隐私保护方面的研究进展,讨论集中学习和联邦学 习在隐私风险的差异.第 4 节展望未来的研究方向,提出联邦学习安全和隐私领域亟待解决的重要问题.第 5 节 总结全文.
1. 联邦学习背景知识
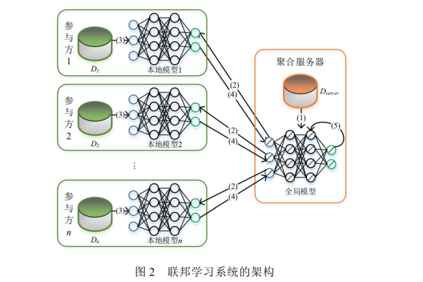
联邦学习是一种分布式的机器学习框架,最早是由谷歌的 McMahan 等人提出并落地应用[3].他们在不泄露 用户个人数据的前提下,利用分布在不同手机的数据集训练统一的机器学习模型.以杨强教授为首的微众银行 团队对谷歌提出的联邦学习概念进行扩展,将其推广成所有隐私保护的协作机器学习技术的一般概念,以涵盖 组织间不同的协作学习场景[13]。图 2 为联邦学习系统的典型架构,架构中包含两类角色:多个参与方(也称客户或用户)和一个聚合服务器. 每个参与方拥有完整数据特征的数据集,且数据样本之间没有交集或交集很小.它们可以联合起来训练一个统一且性能更好的全局模型,具体的训练过程如下:
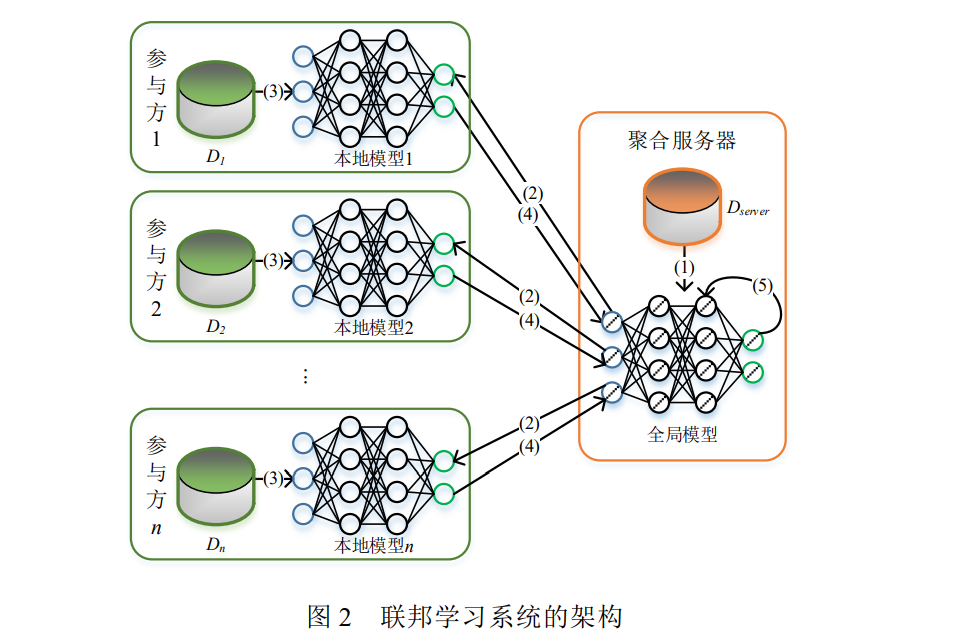
(1) 模型初始化:聚合服务器选定目标模型的结构和超参数,并初始化模型的权重(基于自身拥有的数据 Dserver 进行训练或随机初始化),生成初始的全局模型; (2) 模型广播:通过聚合服务器广播或参与方主动下载的方式,聚合服务器将当前全局模型的权重共享给 所有参与方; (3) 参与方训练:参与方基于共享的全局模型,利用本地保存的私有数据训练微调本地模型,并计算本地模 型的权重更新; (4) 模型聚合:聚合服务器从参与方收集模型的权重更新,根据业务需求采用不同的算法进行聚合.常见的 聚合算法包括 FedAvg[3]、Krum[14]、Trimmed mean[15]和 Median[15]等.在这过程中为了提高效率,聚合服务器可 以选择只收集部分参与方的模型更新进行聚合; (5) 更新全局模型:聚合服务器基于计算的聚合结果更新全局模型的参数. 上述(2)~(5)步骤将会持续迭代进行,直至全局模型收敛或者达到最大迭代次数或超过最长训练时间. **2 安全威胁与防护 **
在集中学习的发展过程中,许多学者对其安全性进行深入研究,发现其中存在的安全威胁,如训练阶段的投 毒攻击(poisoning attack) [19]和推理阶段的对抗样本攻击(adversarial examples attack)等[20].联邦学习的推理阶段 与集中学习一致,因此也会面临对抗样本攻击.而在训练阶段,联邦学习采用分布式计算的方法,为整个系统的 安全性研究引入了新的问题与挑战.本文主要总结面向联邦学习的安全威胁与防护方法,与集中学习相关的安 全研究不在本文的讨论范围内.

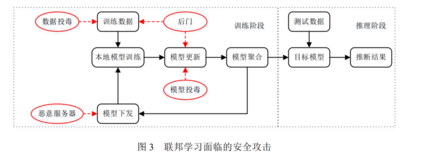
本文以联邦学习面临的安全攻击的发生逻辑和顺序对目前主要研究的攻击手段进行分类(如图 3 所示),具 体可分为数据投毒攻击[21–23]、模型投毒攻击[24–29]、后门攻击[25,30–34]和恶意服务器.注意,图 3 的推理阶段在实 际应用中还存在对抗样本等攻击手段,这部分不在本文的讨论范围内.
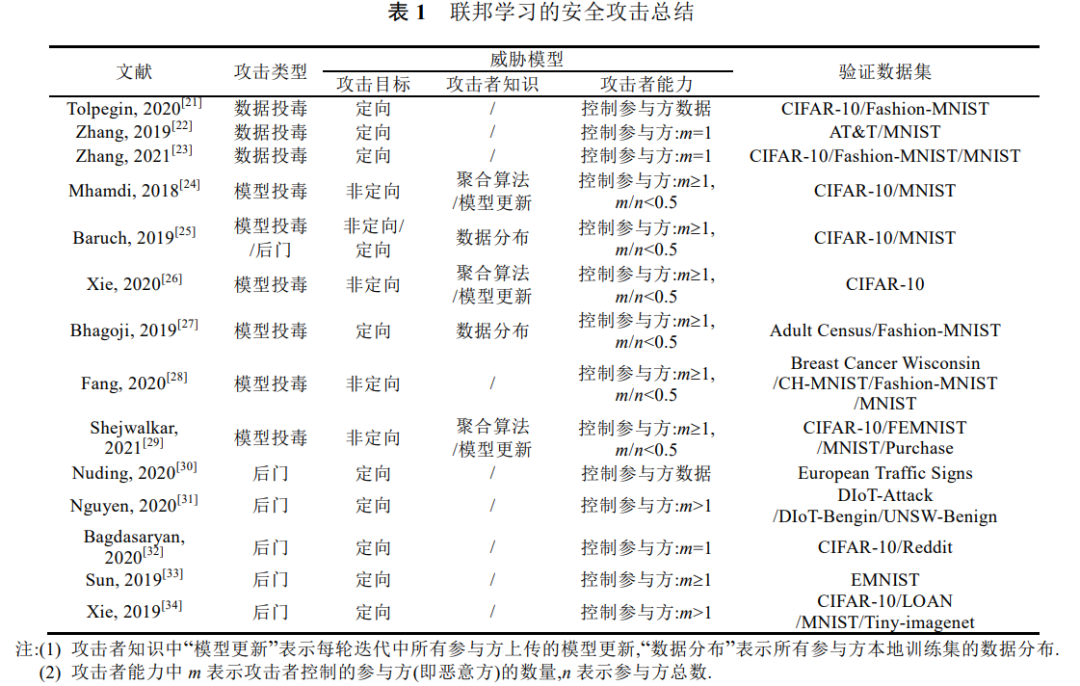
3 隐私风险与保护
根据机器学习隐私保护的内容,可将机器学习隐私分为训练数据隐私、模型隐私与预测结果隐私[108].对于 模型隐私,因为联邦学习需要参与方在本地训练模型,模型算法、神经网络结构和参数等模型信息对参与方都 是可见的,所以联邦学习通常不考虑模型隐私泄露的风险.而对于预测结果隐私,集中学习和联邦学习面临的攻 击手段和防护方法是一致的,不在本文的讨论范围内.因此本文对于隐私风险的总结和分析主要是针对训练数 据隐私,下文如无特殊说明,隐私均指代训练数据隐私.
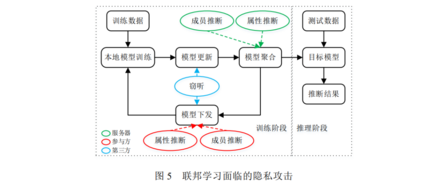
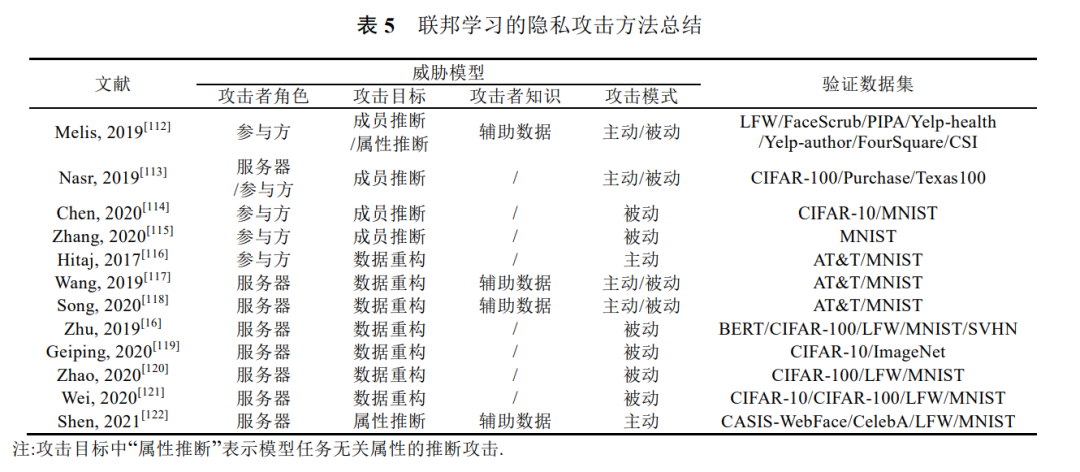
虽然联邦学习通过参与方和服务器交换模型参数的方式保护了参与方的本地数据,但是学者研究发现交 换的模型梯度也可能泄露训练数据的隐私信息[109,110].对于集中学习,模型倒推(model inversion)攻击可以从模 型中反推训练数据的属性值[111],这同样也适用于联邦学习的全局模型.而联邦学习的训练机制也为隐私引入了 新的风险: (1) 联邦学习的模型信息对攻击者是可见的,攻击者可以实施白盒隐私攻击. (2) 联邦学习的训练包含多轮迭代,攻击者可以利用模型在迭代过程的变化挖掘更多的数据信息. (3) 攻击者可以通过参与方或服务器干扰模型训练过程,修改模型参数,使正常参与方在后续迭代中暴露 更多本地数据信息. 因此许多学者专门针对联邦学习存在的隐私风险与保护方法进行研究.本文以联邦学习面临的隐私攻击 的发生逻辑和顺序对目前主要研究的攻击手段进行分类(如图 5 所示),具体分为成员推断攻击[112–115]、属性推 断攻击[16,112,116–122]和窃听.根据攻击者角色的不同,隐私攻击发生在联邦学习的不同阶段,如服务器是在模型聚 合阶段发动隐私攻击.注意,在图 5 的推理阶段可以实施集中学习的隐私攻击手段,这部分不在本文讨论范围内.
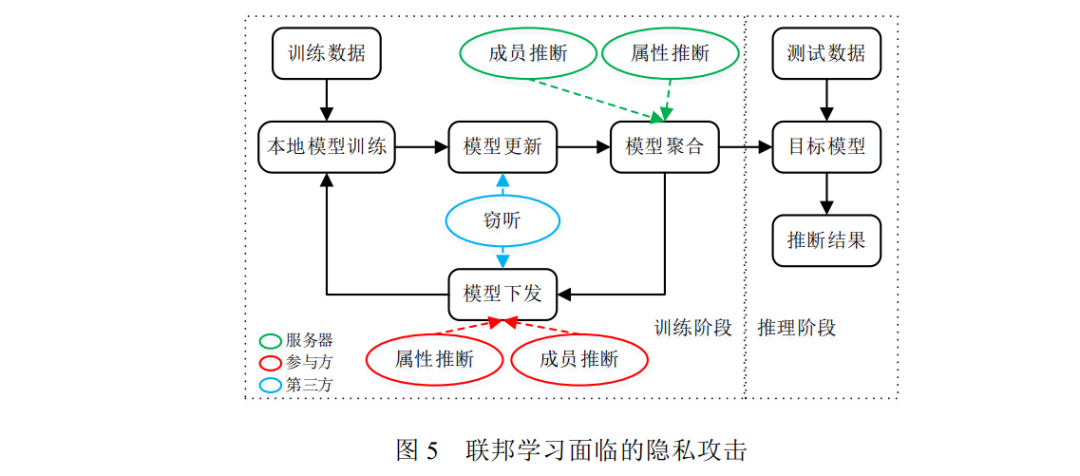
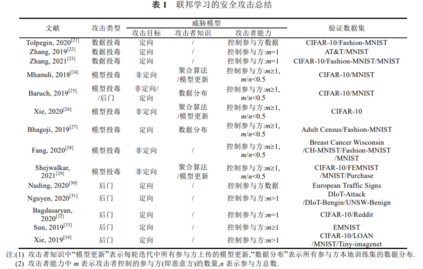
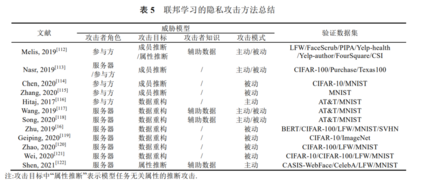
目前针对联邦学习的隐私攻击方法及其威胁模型如表 5 所示.另外,表 5 还总结每种攻击验证时 使用的数据集,包括图像领域的 CIFAR-100[40]、CIFAR-10[40]、MNIST[41]、AT&T[43]、LFW[125]、FaceScrub[126]、 PIPA[127]、BERT[128]、SVHN[129]、ImageNet[130]、CASIS-WebFace[131]和 CelebA[132],文本领域的 Yelp-health[133] 和 Yelp-author[133],以及其它领域的 Purchase[52]、FourSquare[134]、Texas100[135]和 CSI[136].
4 未来展望
虽然联邦学习模型的安全与隐私研究已经取得许多研究成果,但是目前还处于初期探索阶段,尚有诸多问 题亟待解决,其中有以下三个重要问题值得深入研究:
**(1) 成本低和隐蔽性强的联邦学习投毒攻击与防护 **
目前联邦学习安全攻击的研究主要集中在模型投毒攻击,攻击者通过构造恶意的模型更新破坏全局模型, 许多学者在此之上进行攻防博弈.然而,模型投毒要求攻击者完全控制单个或多个参与方,随着联邦学习部署应 用的延伸,逐渐减少的脆弱参与方将限制模型投毒的应用.与之相比,数据投毒对攻击者能力要求低,具有更广 泛的实施场景,且在大规模训练数据集中更不易被发现.然而,目前对数据投毒的研究还比较浅显,只停留在简 单验证攻击可行性的阶段.数据投毒需要经过模型本地训练阶段,其产生的恶意更新与正常更新有一定的相似 性,是否可以生成恶意训练数据模糊恶意更新与正常更新,以绕过现有异常检测聚合算法的防御?是否可以通过 构造恶意数据生成目标模型更新,从而利用现有模型投毒的研究成果实施更加隐蔽的攻击?如何防止数据投毒 的攻击效果被模型聚合削弱?这些问题都亟待后续深入研究.加强对联邦学习数据投毒的研究,可以对联邦学习 的安全性有更加深刻的认识,进而推动联邦学习安全防护方法的探索,为联邦学习的推广应用保驾护航.
**(2) 参与方退出联邦学习时的隐私保护 **
在 GDPR 等隐私保护的法律法规中明确规定个人对其隐私数据享有删除权和被遗忘权,即个人有权要求 数据控制者删除其个人信息,且数据控制者需采取必要的措施,负责消除已经扩散出去的个人数据[2].在联邦学 习应用中,当个体参与方退出联邦学习系统时,服务器需要按照法律规定删除参与方的个人信息.从隐私攻击方 法的总结可以发现参与方的本地数据会在模型参数留下痕迹 , 因此服务器需要从模型参数中 “ 忘 却”(unlearning)参与方的本地数据.集中学习也面临着相同的隐私保护问题,Bourtoule 等人[178]提出通过排除目 标数据重新训练模型解决,但在联邦学习中模型参数已经通过多轮迭代扩散到其它参与方,清除其它参与方本 地模型的隐私痕迹变得非常困难.因此,需要研究改进联邦学习的机制,确保可以删除和遗忘退出参与方的隐私 信息.另外还需要考虑可证明性,即服务器可以向参与方证明其个人信息及扩散的数据都已经清除.
**(3) 安全和隐私并重的联邦学习系统 **
目前对于联邦学习安全和隐私的研究都是侧重单个方面,但在实际应用中安全威胁和隐私风险是同时存 在的,且无法通过简单叠加现有的安全防护手段和隐私保护方法进行防御,例如差分隐私添加的噪声可能干扰 安全聚合算法的检测,同态加密的密文可能屏蔽模型更新的差异使安全聚合算法失效.因此需要综合考虑联邦 学习的安全和隐私问题,研究安全与隐私并重的联邦学习系统.文献[60,99,179]对此进行了初步的探索,但是只 涵盖部分安全威胁和隐私风险,还有待更加全面的研究.
**5 结束语 **
随着联邦学习的快速发展和广泛应用,联邦学习模型的安全和隐私问题吸引了许多学者的兴趣和关注,产 生了不少瞩目的研究成果,但目前相关的研究还处于初级阶段,尚有许多关键问题亟待解决.本文在充分调研和深入分析的基础上,对联邦学习在安全和隐私领域最新的研究成果进行综述,系统总结了联邦学习存在的安全 和隐私攻击,并对现有的防护方法进行科学地分类和分析.同时,本文也指出了当前联邦学习在安全和隐私领域 尚未解决的问题,并探讨未来的研究方向.