首篇《面向软件工程的大型语言模型》综述,值得关注!

大型语言模型(LLMs)已经对包括软件工程(SE)在内的众多领域产生了重大影响。近期的很多出版物都探讨了将LLMs应用到各种SE任务和应用程序中。然而,对LLMs在SE上的应用、影响和可能的局限性的全面理解还处于初级阶段。 为了弥补这个缺口,我们对LLMs和SE的交叉点进行了系统的文献回顾,特别关注了如何利用LLMs优化SE的流程和结果。我们共收集并分析了从2017年到2023年的229篇研究论文,以回答四个关键的研究问题(RQs)。 在RQ1中,我们分类并提供了不同LLMs的比较分析,这些LLMs已经被用于SE任务中,表征了它们的独特特性和用途。 在RQ2中,我们分析了数据收集、预处理和应用中使用的方法,强调了健壮、精心策划的数据集对于成功实施SE中的LLMs的重要性。 RQ3研究了用于优化和评估SE中LLMs性能的策略,以及与提示优化相关的常见技术。 最后,RQ4检查了迄今为止LLMs已经取得成功的具体SE任务,说明了它们对该领域的实际贡献。 从这些RQs的答案中,我们讨论了当前的最新技术和趋势,识别了现有研究中的空白,并指出了未来研究的有前景的领域。
1. 概述
在语言处理领域,传统的语言模型(LMs)历史上一直是基础元素,为文本生成和理解奠定了基础[192]。增加的计算能力、先进的机器学习技术和对大规模数据的访问,导致了大型语言模型(LLMs)的出现的显著转变[323, 338]。配备了广泛和多样的训练数据,这些模型展示了令人印象深刻的模拟人类语言能力的能力,从而引发了多个领域的变革。凭借其从大量语料库中学习和生成似是而非的文本的能力,LLMs正在模糊人类和机器生成语言之间的界线。它们为研究人员和工程师提供了一个强大的工具,可以探索人类交流的复杂性和丰富性,从而引发了语言处理领域及其之外的变革时期。 软件工程(SE)- 一个专注于软件系统的开发、实施和维护的学科 - 是受益于LLM革命的领域之一[177]。将LLMs应用于SE主要源于一种创新的视角,其中许多SE挑战可以有效地重新构建为数据、代码或文本分析任务[279]。使用LLMs来解决这些SE任务已经显示出大量的潜在突破[26, 30, 137, 253, 264, 300, 301, 329]。LLMs的适用性在诸如代码摘要[274]等任务中尤为明显,该任务涉及生成代码功能的抽象自然语言描述,以及生成结构良好的代码[316]和代码工件,如注释[162]。Codex,一个拥有120亿参数的LLM,已经展示了解决人类提出的72.31%的复杂Python编程挑战的能力[36]。来自OpenAI的GPT-4[212]是一个LLM,已经在几个SE任务中表现出了强大的性能,包括代码编写、理解、执行和推理。它不仅处理实际应用程序和多样化的编码挑战,而且还显示出用自然语言解释结果和执行伪代码的能力[24]。 同时,研究人员已经开始了一系列关于LLM相关工作的研究活动,其中产生了一些文献综述或调查论文[29, 58, 59, 338]。表1总结了其中的一些。然而,这些相关研究有局限性。它们要么狭窄地关注一个单一的SE范围,例如LLMs在软件测试[277]和自然语言到代码(NL2Code)任务[323]中的应用,要么主要集中在机器学习(ML)或深度学习(DL)模型[279, 309]上,忽视了更先进和最近出现的LLM应用,如ChatGPT[209],这些应用越来越多地在SE领域中找到应用[174, 254, 264, 295]。或者,他们仅通过实证实验初步探索了LLMs在各种SE任务中的性能,而没有进行系统的文献调查[53, 177, 254, 303, 338]。将LLMs集成到SE中无疑是一个复杂的努力,需要考虑的关键因素包括选择正确的模型、理解不同LLMs的独特特性、设计预训练和微调策略、处理数据、评估结果和克服实施挑战[323]。尽管该领域对LLMs的应用兴趣浓厚,并且正在进行持续的探索,但目前的文献中还明显缺乏对SE中LLMs应用的详细和系统的审查。这个空白意味着需要理解LLMs和SE之间的关系。为了回应这个问题,我们的研究旨在弥补这个空白,为社区提供宝贵的见解。
本文对LLMs在SE中的利用(LLMs4SE)进行了系统性的文献综述。通过绘制当前的最新技术状态,明确现有LLMs4SE文献中的关键优势、弱点和差距,并本文对LLMs在SE中的利用(LLMs4SE)进行了系统性的文献综述。通过绘制当前的最新技术状态,明确现有LLMs4SE文献中的关键优势、弱点和差距,并提出未来研究的潜在途径,我们的综述旨在为研究人员和实践者提供一个全面的LLMs4SE收敛指南。我们预计,我们的发现将有助于指导这一快速发展的领域未来的调查和进步。这项工作做出了以下主要贡献:
我们是第一个提出全面系统性文献综述的团队,基于2017年至2023年间发表的229篇论文,重点关注使用基于LLM的解决方案来解决SE挑战。我们根据出版趋势、出版地点分布等对选定的论文进行了详细分析。
我们对报告的SE任务中使用的LLM进行了分类,并提供了SE领域中不同LLM类别的使用和趋势的摘要。
我们描述了报告的数据处理阶段,包括数据收集、分类、预处理和表示。
我们讨论了用于LLMs4SE任务的优化器,包括参数和学习率优化、流行的提示优化技术和常用的评估指标。
我们描述了LLMs4SE的关键应用,包括55个具体的SE任务,分为六个核心SE活动-软件需求、软件设计、软件开发、软件测试、软件维护和软件管理。
我们总结了在SE领域使用LLMs遇到的关键挑战,并为LLMs4SE提出了几个潜在的研究方向。
第2节提出了我们的研究问题(RQs)并详细阐述了我们的系统性文献综述(SLR)方法。接下来的第3~6节致力于分别回答这些RQ。第7节披露了我们研究的局限性。第8节讨论了在使用LLM解决SE任务时需要克服的挑战,并强调了未来研究的有前途的机会和方向。第9节总结了整篇论文。
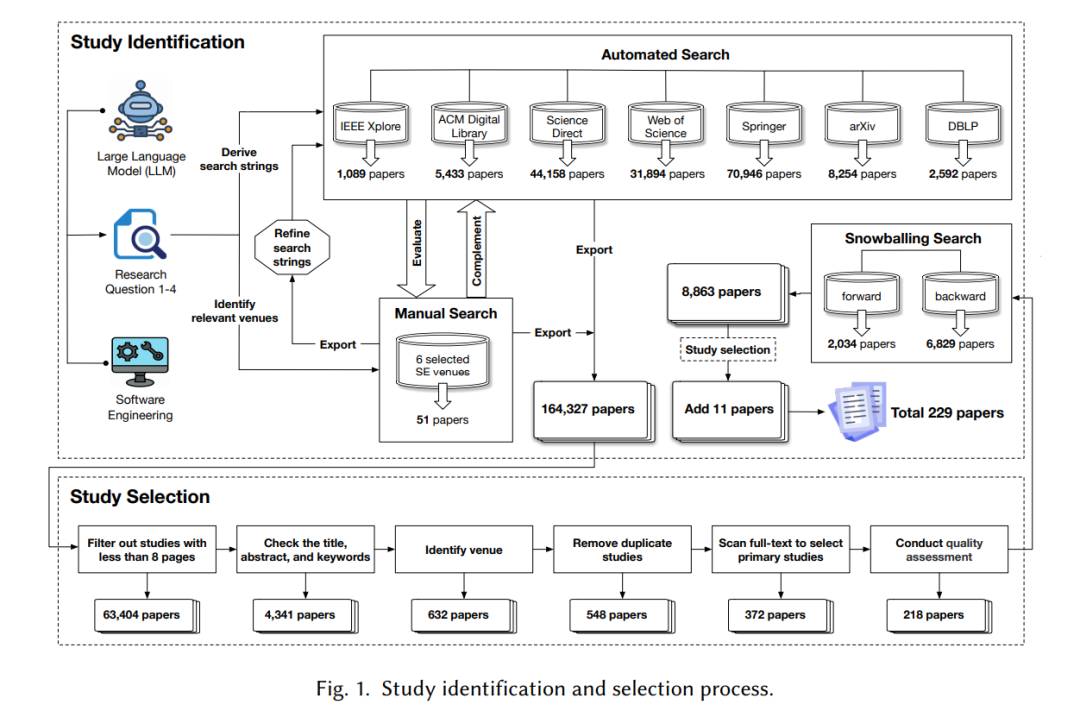
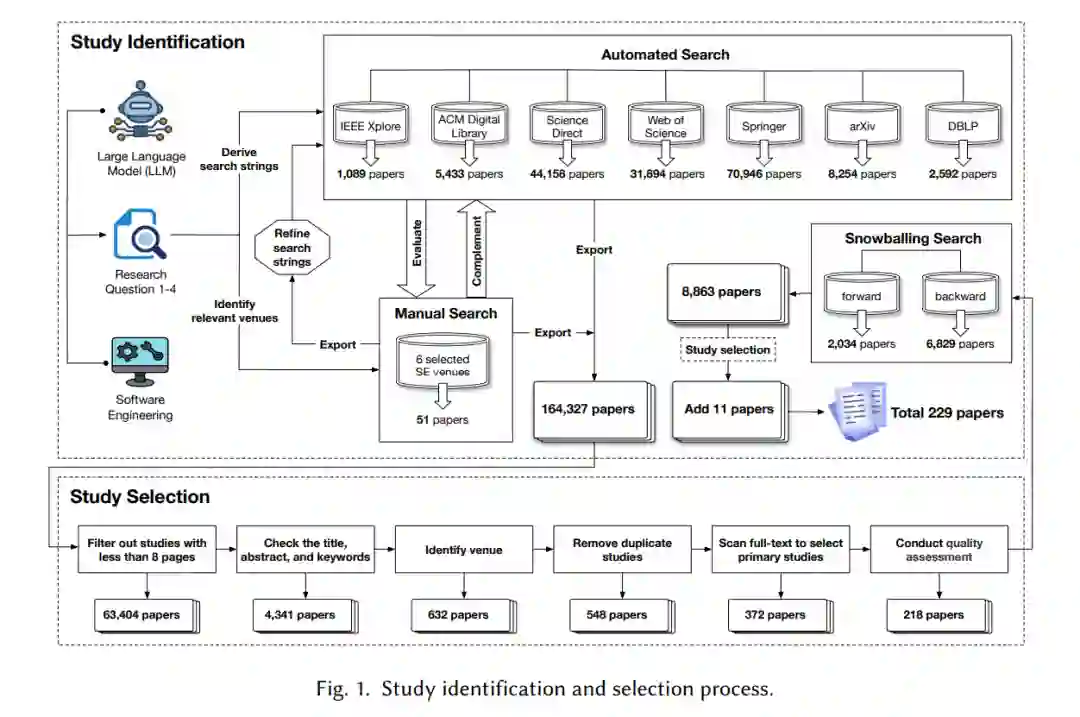
本系统性文献综述(SLR)遵循Kitchenham等人[126, 127]提出的方法,该方法也被大多数其他与SE相关的SLR所使用[148, 172, 230, 279]。遵循Kitchenham等人提供的指南,我们的方法包括三个主要步骤:规划综述(即第2.1、2.2节)、进行综述(即第2.3、2.4节)和分析基本综述结果(即第2.5节)。 RQ1:到目前为止,哪些LLM被用来解决软件工程任务?
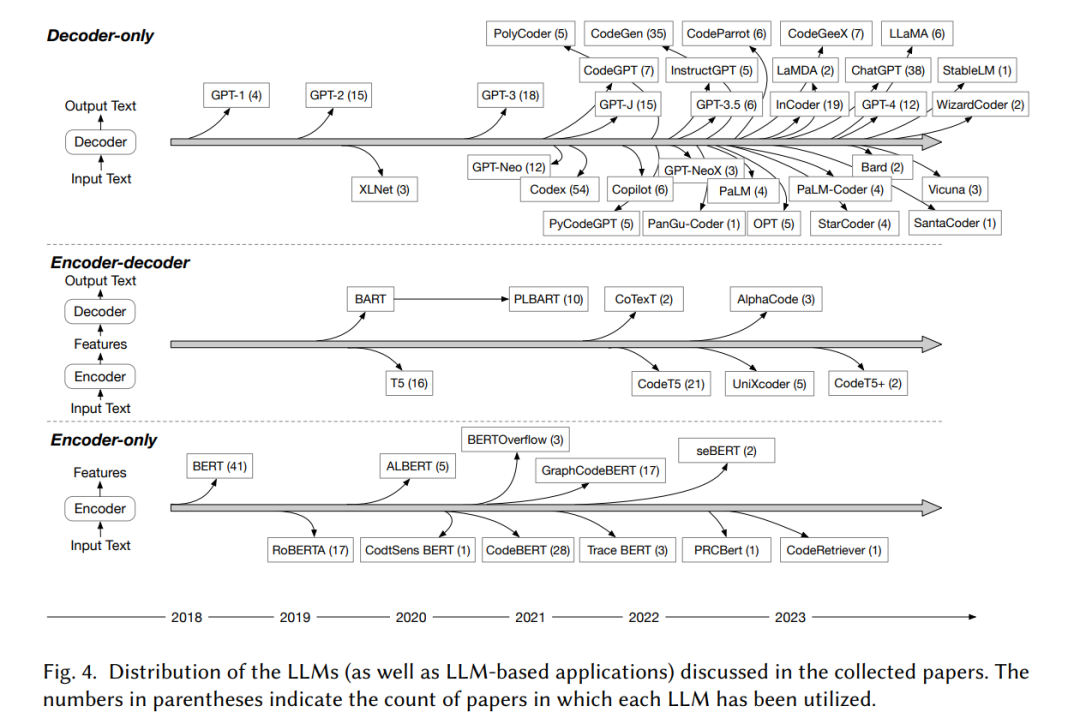
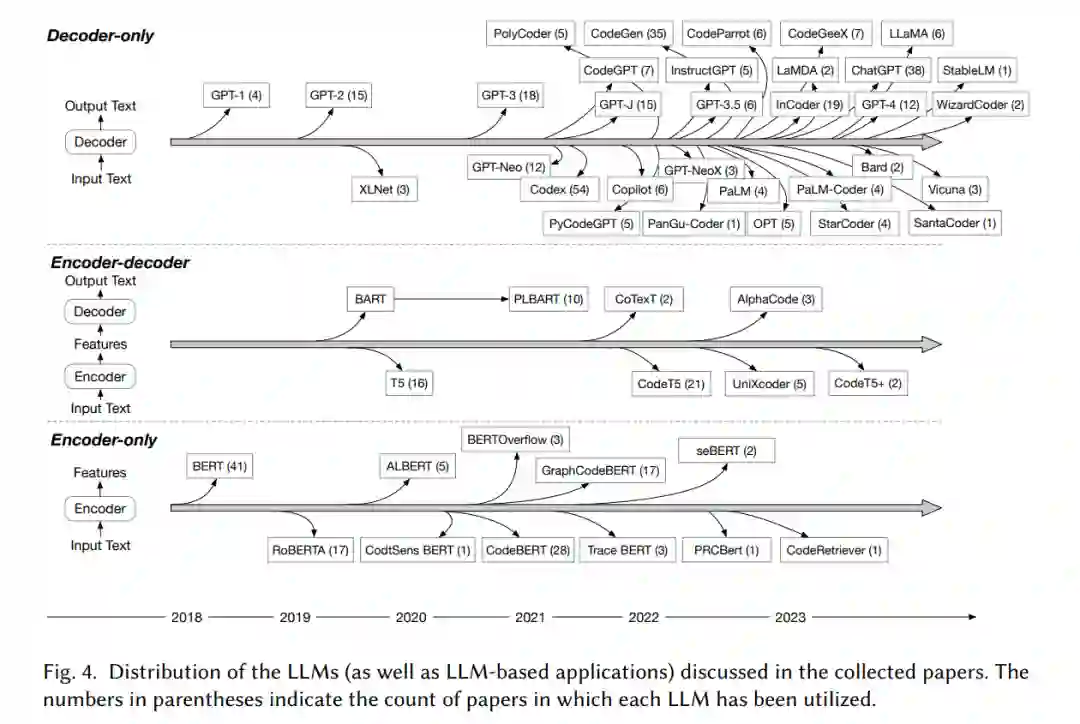
(1) 在收集的论文中,有50多种不同的LLM用于SE任务,根据不同LLM的底层架构或原理,我们将汇总的LLM分为3类,即仅编码器、编码器-解码器和仅解码器LLM。(2) 我们分析了LLM用于SE任务的使用趋势。使用最广泛的LLM是仅解码器架构的LLM,有30多种LLM属于仅解码器类别,有138篇论文研究了仅解码器LLM在SE任务中的应用。****
RQ2 在LLMS中,SE相关数据集是如何收集、预处理和使用的?
(1) 我们根据数据来源将数据集分为4类:开源、收集、构建和工业数据集。开源数据集的使用最为普遍,在177篇明确说明数据集的论文中约占63.84%。(2) 我们将所有数据集内的数据类型分为5组:基于代码、基于文本、基于图、基于软件库和组合。在将LLM应用于SE任务中,基于文本和基于代码的数据类型使用最为频繁。这一模式表明,LLM在SE任务中特别擅长处理基于文本和代码的数据,利用其自然语言处理能力。(3) 我们总结了不同数据类型的数据预处理步骤,发现了几个常见的预处理步骤,即数据提取、不合格数据删除、重复实例删除和数据分割。
RQ3:使用什么技术来优化和评估SE中的LLMS ?
(1)我们分析了LLMs中常用的参数和学习率优化器,发现Fine-tuning和Adam分别是最常用的参数优化和学习率调整技术。(2)我们强调了提示工程技术在改善LLMs执行SE任务时的应用和有效性。通过探索各种类型的提示,包括硬提示和软提示,这种新兴的微调范式在数据稀缺的任务中特别有优势,提供了与任务相关的知识,提高了LLMs在不同代码智能任务中的通用性和有效性。(3)我们根据回归、分类、推荐和生成这四种问题类型总结了最广泛使用的评估指标。生成任务中出现了13种不同的评估指标,其次是分类任务,有9种指标。
RQ4: 到目前为止,使用LLM解决了哪些特定的SE任务?
(1) 基于软件开发生命周期,将软件工程任务分为6个活动:软件需求、软件设计、软件开发、软件测试、软件维护和软件管理。随后,我们总结了LLMs在这些SE活动中的具体应用。(2) 我们总结了55个SE任务,发现LLMs在软件开发中应用最广泛,有115篇论文提到了21个SE任务。软件管理的应用最少,只有1篇论文提到了该领域。(3) 代码生成和程序修复是软件开发和维护活动中使用LLMs最普遍的任务。我们分析了在这些任务中反复验证的性能最好的LLMs,并总结了新发现。
结论
随着LLM的出现,自然语言处理领域正在经历范式转移。这些模型处理庞大复杂的语言任务的潜力,可能会从根本上重塑自然语言处理实践的格局。在这篇系统性文献综述中,我们深入研究了LLM在自然语言处理中的新兴应用随着LLM的出现,自然语言处理领域正在经历范式转移。这些模型处理庞大复杂的语言任务的潜力,可能会从根本上重塑自然语言处理实践的格局。在这篇系统性文献综述中,我们深入研究了LLM在自然语言处理中的新兴应用,包括自其成立以来发表的论文。我们首先检查了在自然语言处理任务中使用的各种LLM,并探索了它们的独特特征和应用(RQ1)。然后,我们深入研究了数据收集、预处理和使用的过程,阐明了健壮和精心策划的数据集在LLM成功实施中的重要作用(RQ2)。接下来,我们研究了用于优化和评估LLM在自然语言处理任务中性能的各种策略(RQ3)。最后,我们回顾了从LLM中获得显著收益的具体自然语言处理任务,揭示了LLM所做出的实际贡献(RQ4)。此外,我们强调了现有的挑战,并提供了研究路线图,概述了有前途的未来方向。