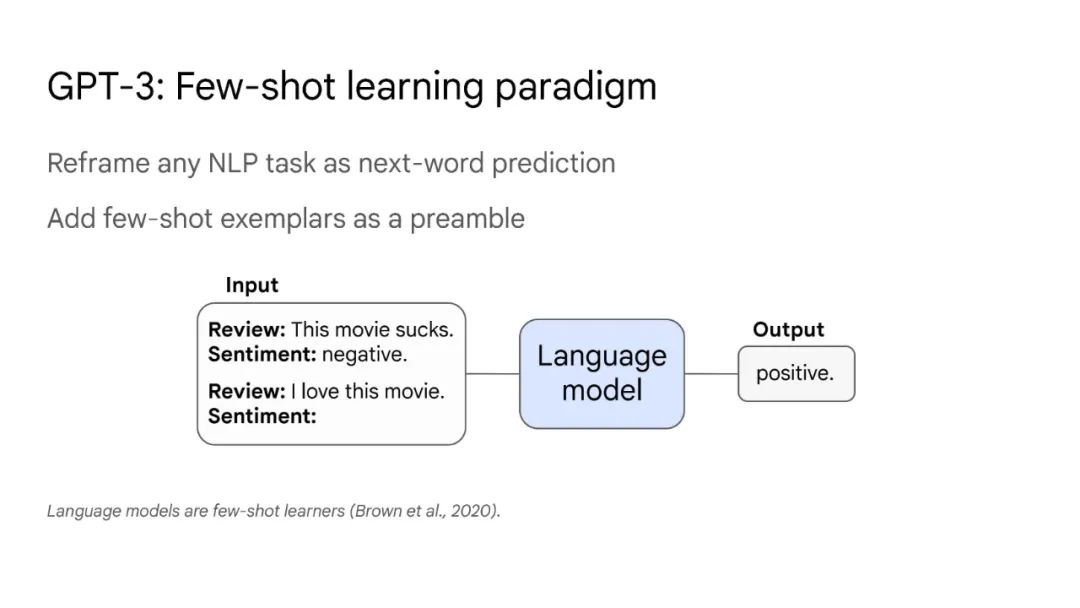
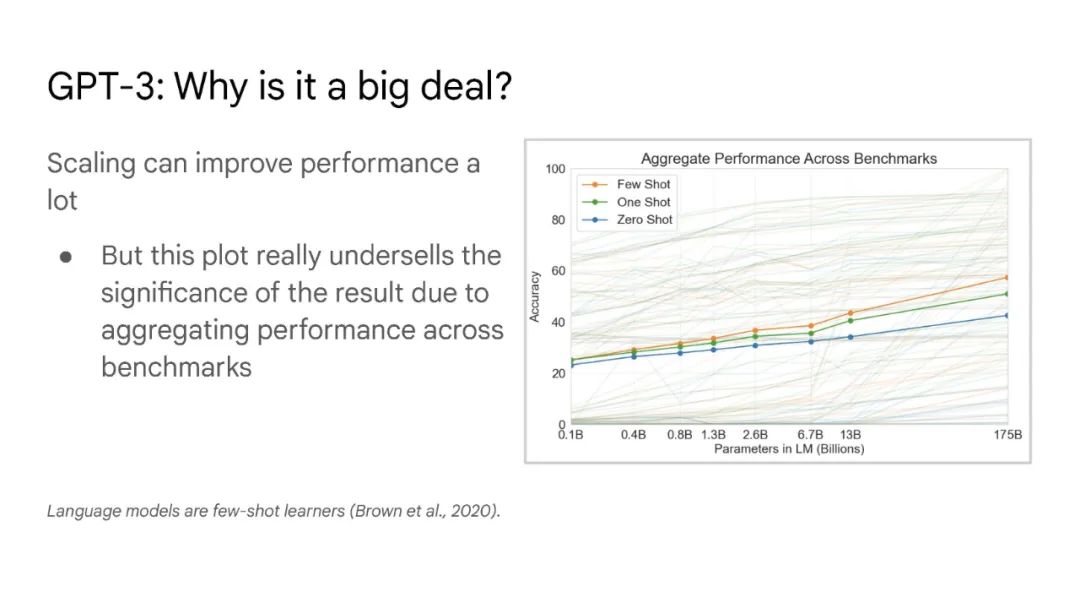
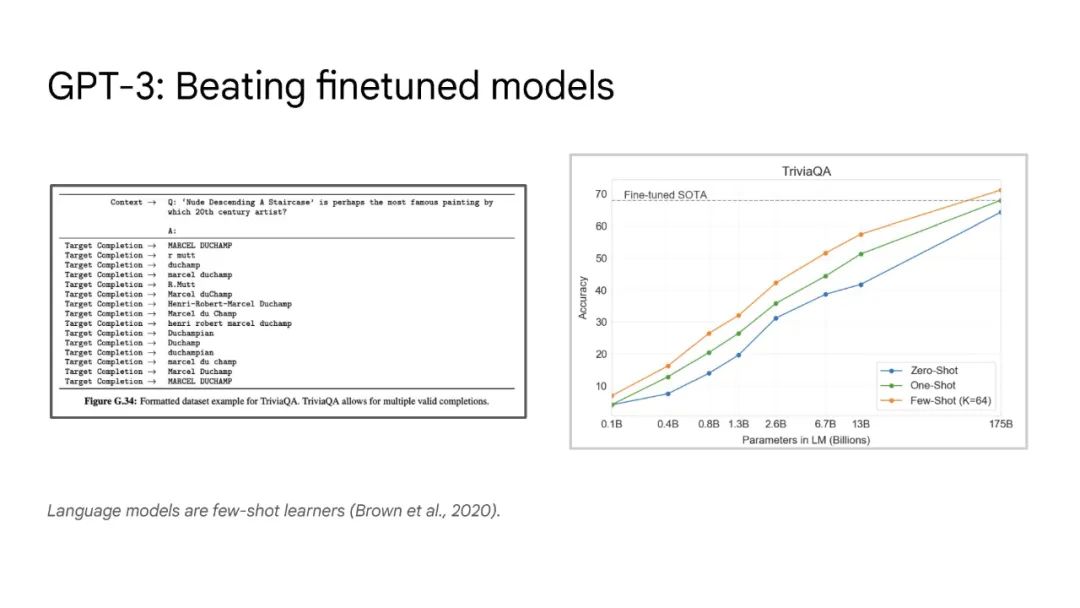
大型语言模型
·


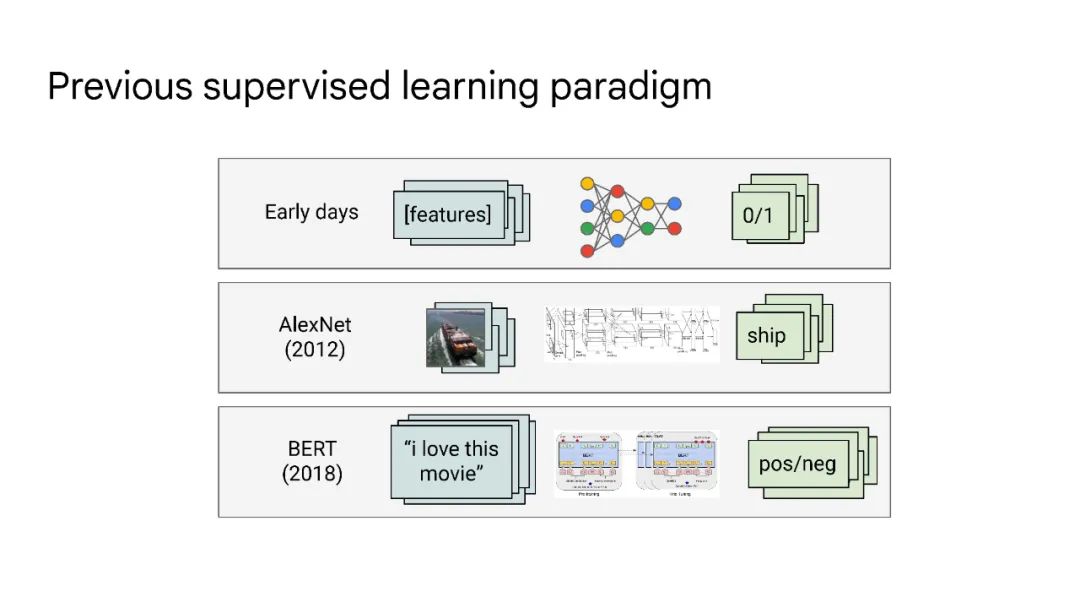
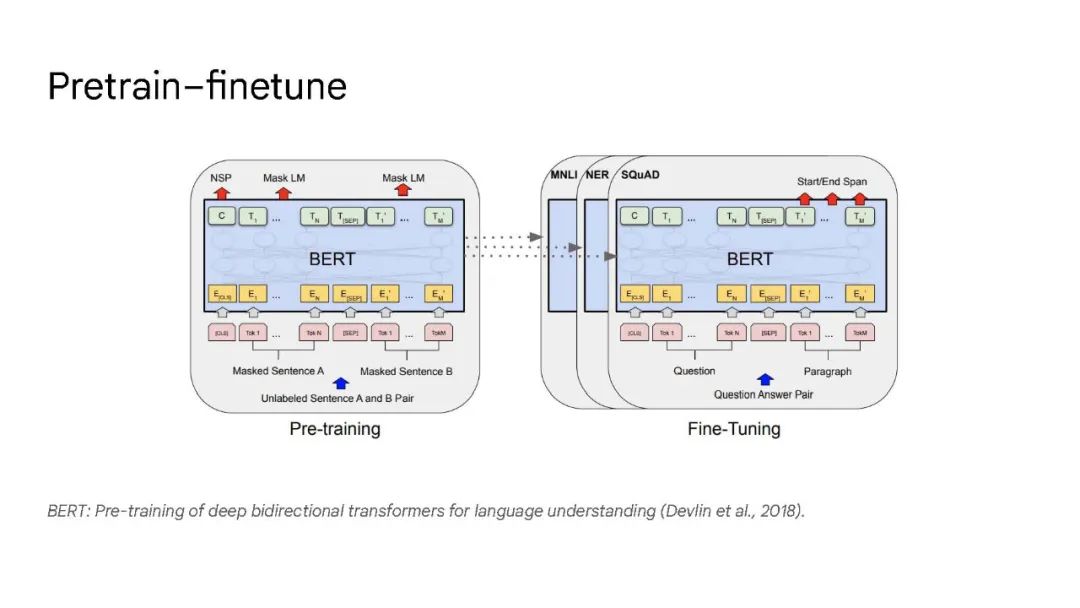
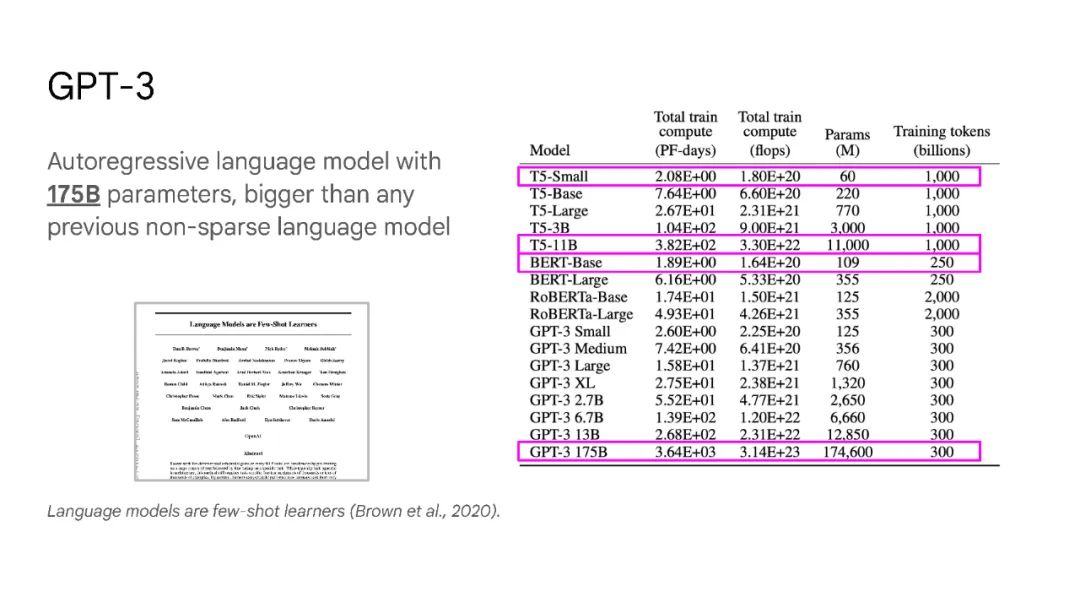
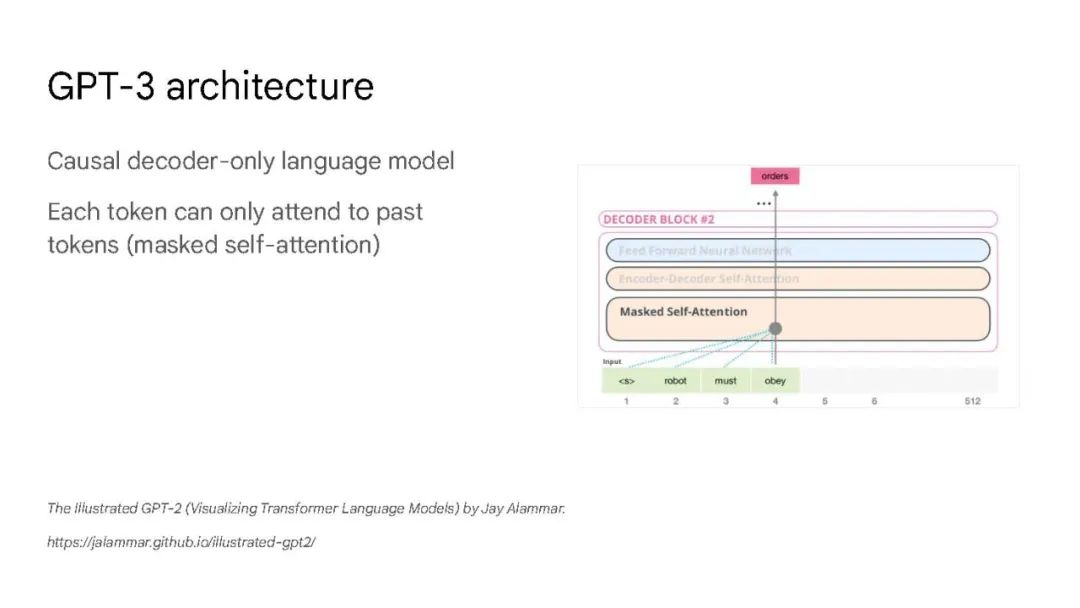
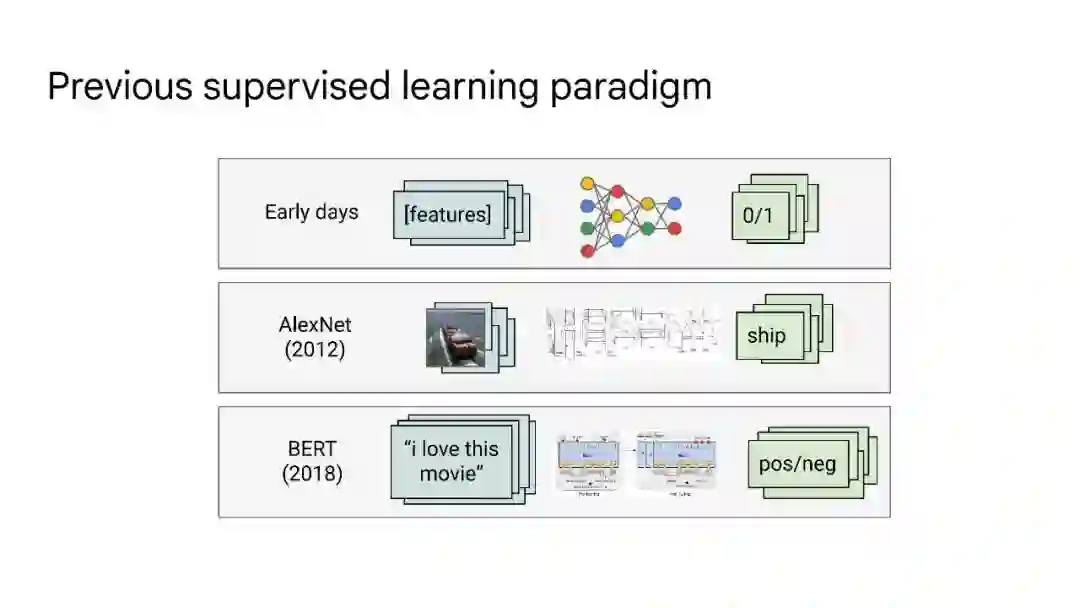
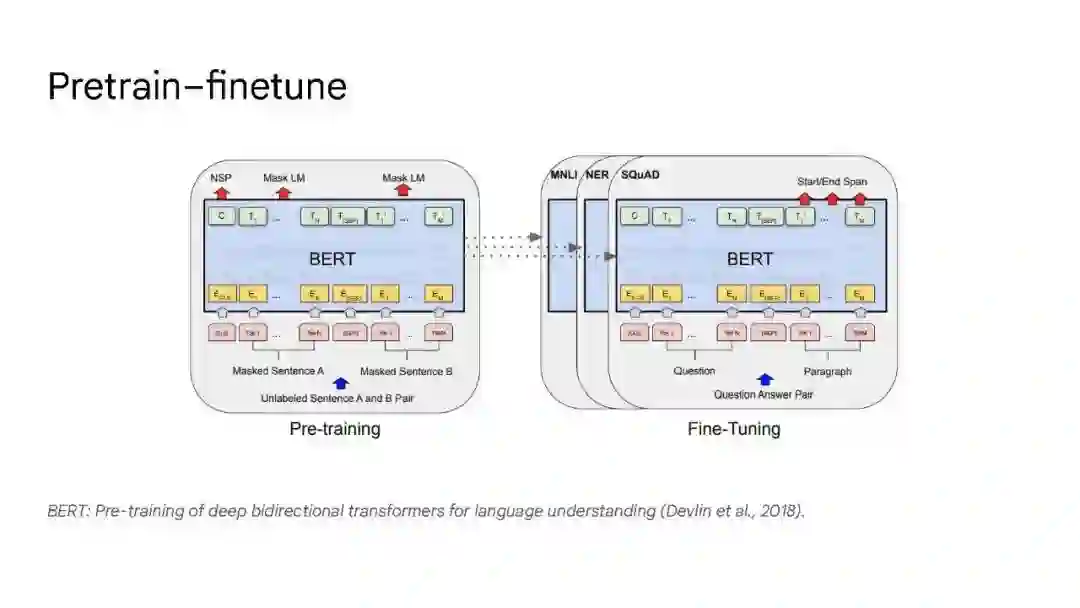
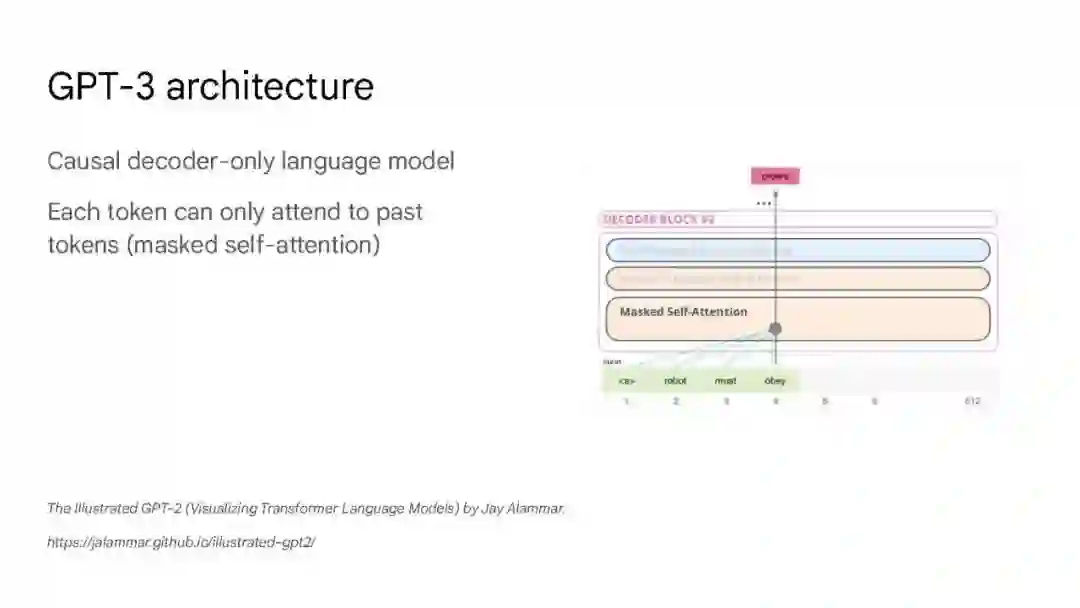
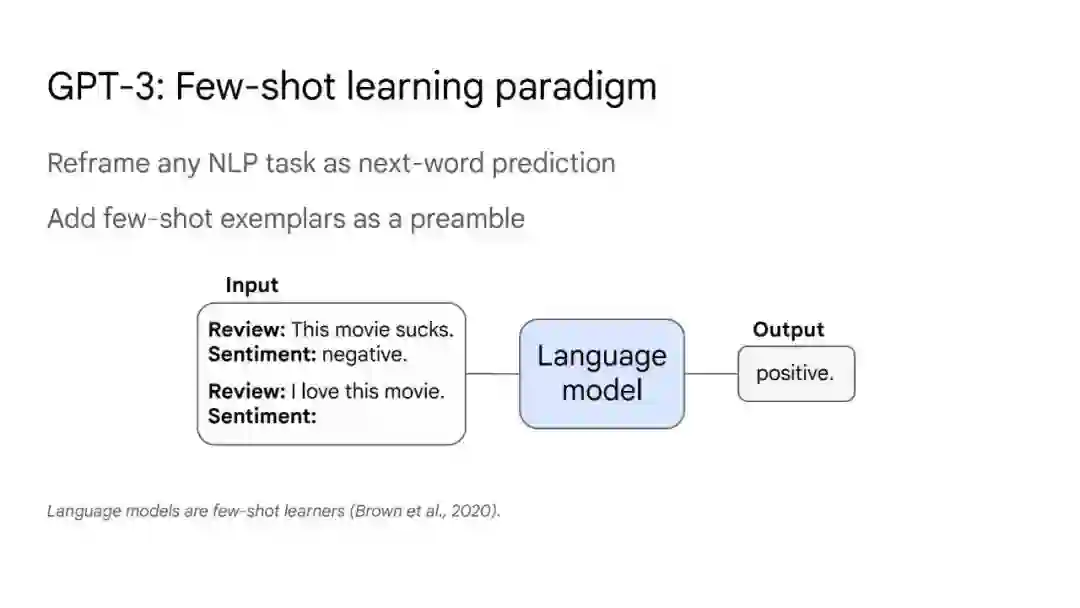
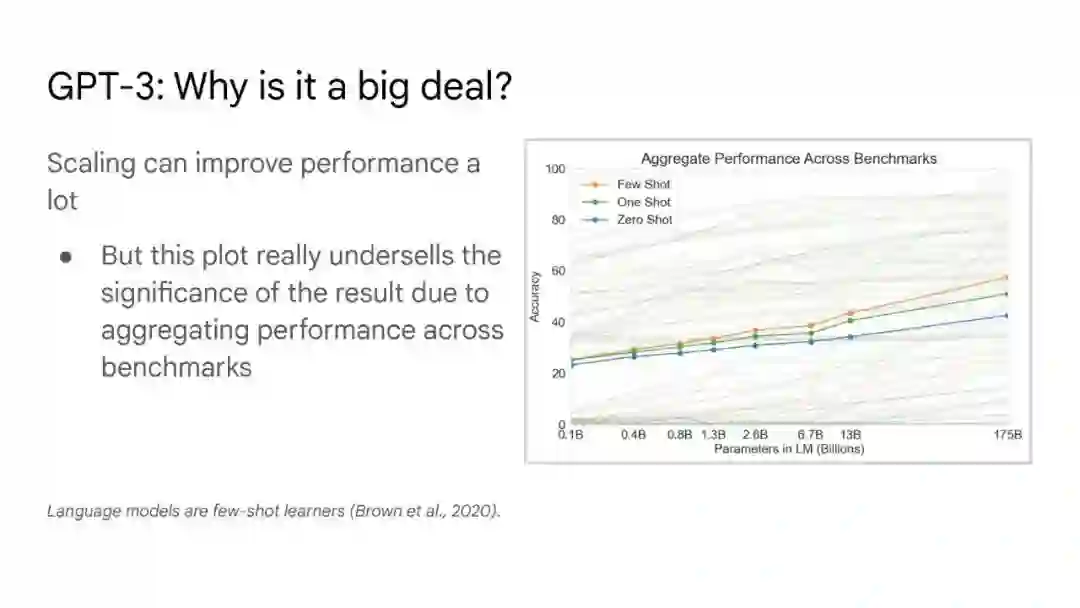
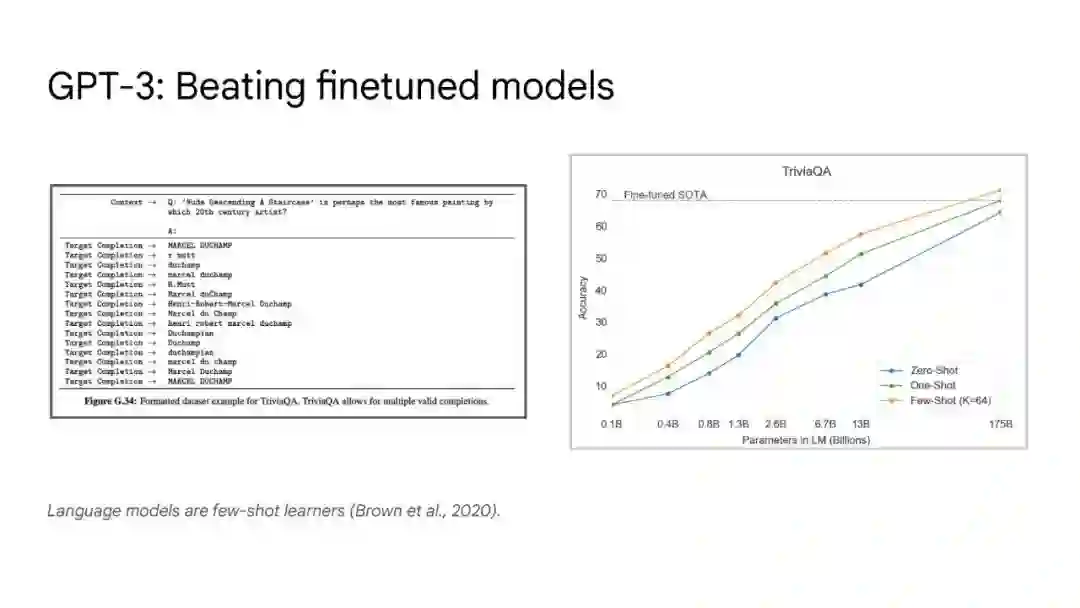
大语言模型已被证明可以在广泛的下游任务中可预见地提高性能和样本效率。本文讨论的是一种不可预测的现象,我们称之为大型语言模型的涌现能力。我们认为,如果一种能力不存在于较小的模型中,而存在于较大的模型中,那么这种能力就是突现的。因此,不能简单地通过外推较小模型的性能来预测突发能力。这种涌现性的存在意味着额外的扩展性可以进一步扩展语言模型的功能范围。





成为VIP会员查看完整内容






相关内容
相关主题
相关VIP内容
相关资讯