

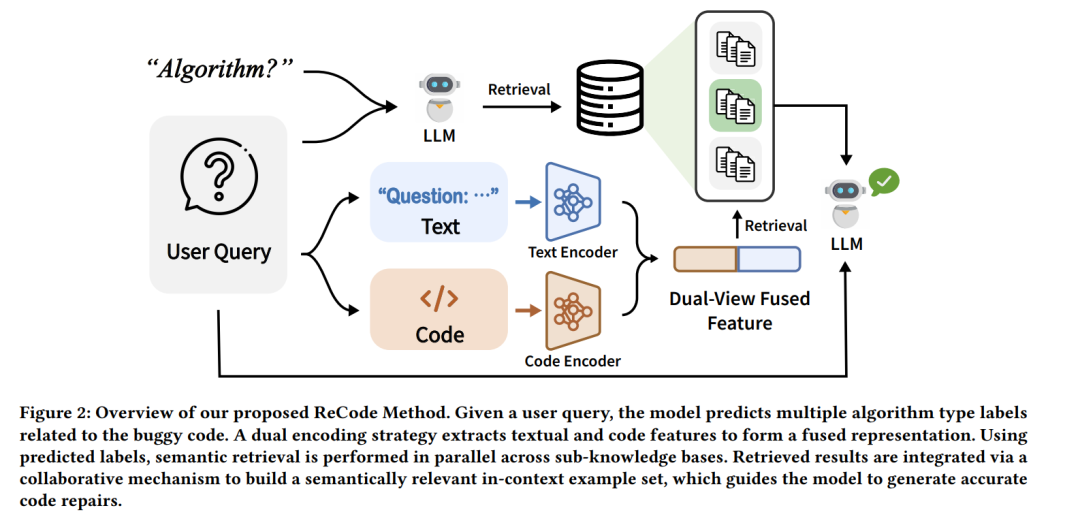
近年来,大语言模型(LLMs)在代码生成与自动程序修复等任务中展现出令人瞩目的能力。尽管性能可观,但现有大多数代码修复方法往往存在训练成本高或推理计算开销大的问题。检索增强生成(RAG)凭借其高效的上下文学习范式,为这一问题提供了更具可扩展性的替代方案。然而,传统检索策略通常依赖整体性的代码—文本嵌入,难以捕捉代码的结构细节,导致检索质量欠佳。 为克服上述局限,我们提出 ReCode,一种面向高效且精确代码修复的细粒度检索增强上下文学习框架。ReCode 包含两项核心创新:(1) 算法感知的检索策略,通过对算法类型进行初步预测来缩小检索空间;(2) 模块化双编码器架构,分别处理代码与文本输入,实现输入与检索上下文之间的细粒度语义匹配。 此外,我们构建了 RACodeBench,一个基于真实用户提交的缺陷代码的新基准数据集,用以弥补合成基准的不足并支持更贴近现实的评估。实验结果表明,在 RACodeBench 与编程竞赛数据集上,ReCode 在显著降低推理开销的同时,取得了更高的修复准确率,凸显了其在真实代码修复场景中的应用价值。
成为VIP会员查看完整内容
相关内容
Arxiv
42+阅读 · 2023年4月19日
Arxiv
217+阅读 · 2023年4月7日
相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
217+阅读 · 2023年4月7日