

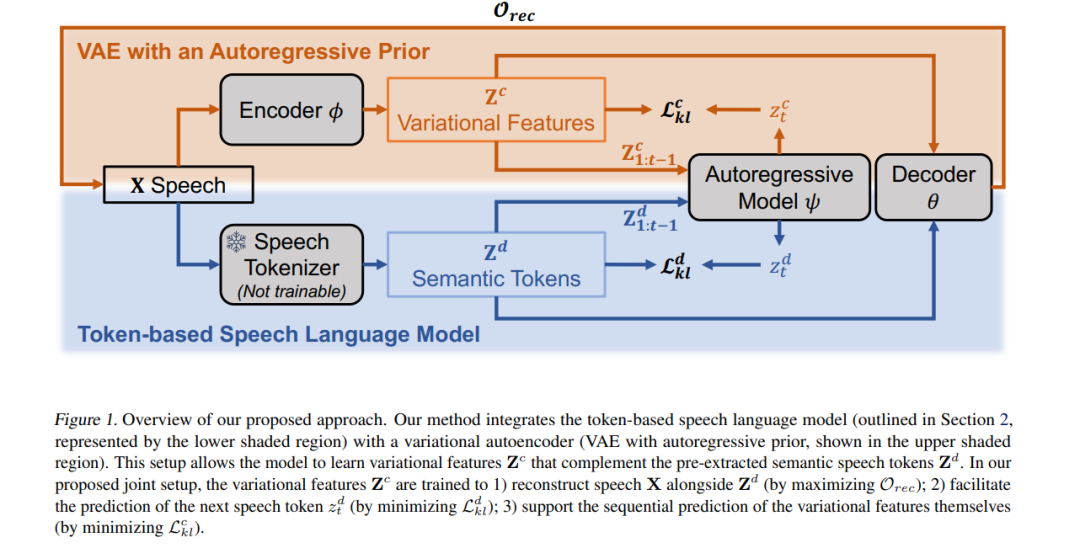
大型语言模型在文本处理上的成功激发了其在语音建模中的应用。然而,由于语音是连续且复杂的,通常需要离散化以便进行自回归建模。由自监督模型提取的语音标记(称为语义标记)通常聚焦于语音的语言层面,但忽略了韵律信息。因此,在这些标记上训练得到的模型往往生成出自然度较低的语音。已有方法试图通过向语义标记中添加音高特征来弥补这一问题,但音高本身无法完整表达各种副语言属性,且选取合适的特征通常依赖精细的人工设计。 为了解决这一问题,我们提出了一种端到端的变分方法,能够自动学习编码这些连续的语音属性,从而增强语义标记的表达能力。我们的方法无需人工提取与选择副语言特征。此外,根据人类评价者的反馈,该方法生成的语音延续在自然性上更受偏好。代码、样本与模型可在以下地址获取:https://github.com/b04901014/vae-gslm。
成为VIP会员查看完整内容
相关内容
Arxiv
40+阅读 · 2023年4月19日
Arxiv
211+阅读 · 2023年4月7日
Arxiv
20+阅读 · 2023年3月21日
相关VIP内容
相关资讯
相关论文
Arxiv
40+阅读 · 2023年4月19日
Arxiv
211+阅读 · 2023年4月7日
Arxiv
20+阅读 · 2023年3月21日