基础模型通过在大规模数据集上进行预训练,提供了强大且通用的架构,从而彻底改变了人工智能的发展。然而,将这些庞大的模型适配于具体下游任务通常需要微调,这在计算资源上可能代价高昂。参数高效微调(Parameter-Efficient Fine-Tuning,PEFT)方法通过仅选择性地更新一小部分参数,来应对这一挑战。与此同时,联邦学习(Federated Learning,FL)允许在不共享原始数据的情况下,在分布式客户端之间协作训练模型,使其非常适用于对隐私敏感的应用场景。
本文综述了参数高效微调技术在联邦学习环境中的融合发展。我们将现有方法系统性地分为三大类:一是加性PEFT(引入可训练的新参数);二是选择性PEFT(仅微调已有参数的子集);三是重参数化PEFT(通过变换模型结构以实现高效更新)。对于每一类方法,我们分析了其如何应对联邦环境下的独特挑战,包括数据异质性、通信效率、计算资源限制和隐私问题。
此外,我们还根据应用领域对文献进行整理,涵盖自然语言处理与计算机视觉任务。最后,本文讨论了若干值得关注的未来研究方向,包括面向更大规模基础模型的扩展、联邦PEFT方法的理论分析,以及适用于资源受限环境的可持续方案。
1 引言
基础模型(Foundation Models,FMs)[92, 104, 105, 52] 通过提供稳健且通用的架构,展现出卓越的能力。它们在理解上下文和语义细节方面表现出色,能够胜任包括自然语言处理(NLP)和计算机视觉(CV)在内的多个领域的多种任务。为了将这些模型适配于特定的下游应用,通常需要进行微调,以提升其在新数据集和任务上的表现。传统方法称为全量微调(full fine-tuning),即更新模型的全部参数。然而,这种方法在面对大规模模型时计算成本极高,难以承受。 为了解决这一问题,研究者提出了**参数高效微调(Parameter-Efficient Fine-Tuning,PEFT)**方法 [42]。该类方法仅选择性地调整一小部分参数,其余部分保持不变,从而显著降低了计算需求。近期的前沿PEFT方法 [47] 已表明,这些方法能够在大幅减少计算开销的同时,达到与全量微调相当的性能。
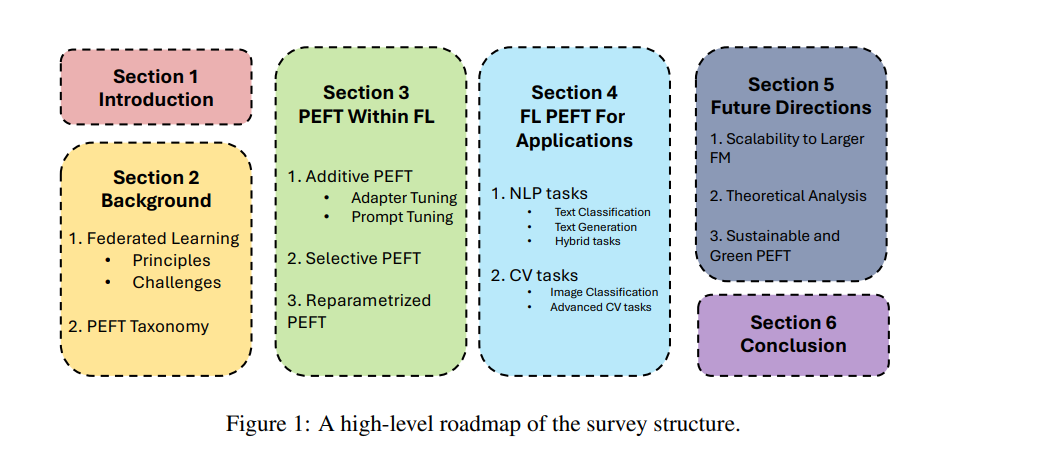
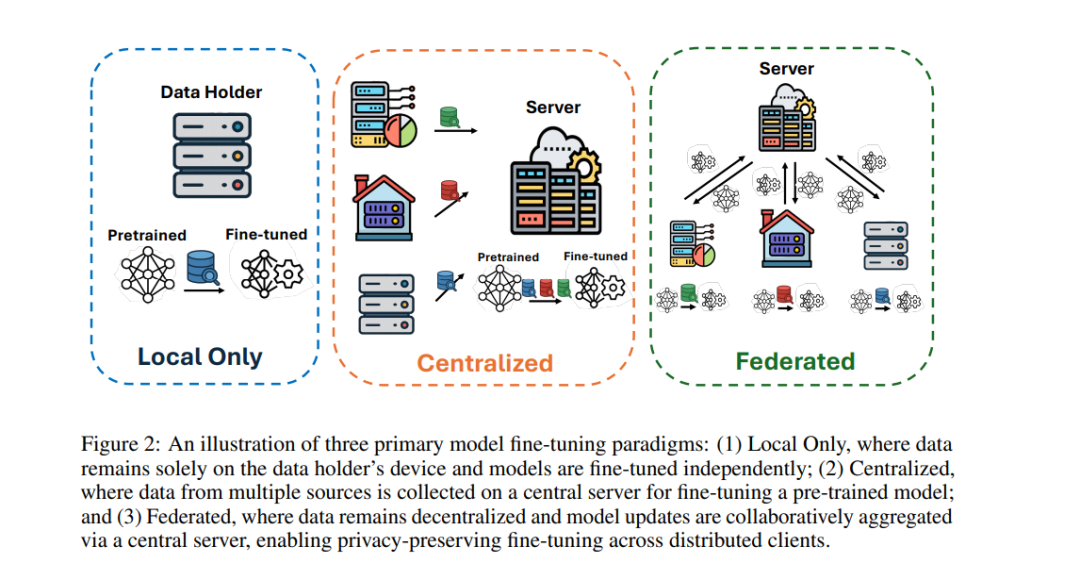
尽管PEFT方法在计算资源上具有显著优势,但为了有效适配具体的下游任务,仍需大量数据 [42]。然而,单一实体所拥有的数据往往难以满足这一需求,这就需要多个数据拥有者之间进行合作,共同利用分散的数据资源。在这种多方协作的场景下,隐私问题随之而来,因为多方微调过程中可能泄露敏感信息。在法律、医疗和金融等高度敏感的数据领域,隐私问题尤为关键 [33],因此必须实施严格的隐私保护机制。 联邦学习(Federated Learning,FL)[79] 提供了一种可行的解决方案,它允许在不直接共享原始数据的前提下进行协同模型微调。FL使得多个参与方能够在保障数据隐私的同时,参与模型的适配过程,从而有效应对上述挑战。 鉴于将PEFT与基础模型融合于FL框架中具有显著优势,已有大量研究开始探索这一方向 [112, 128]。这些工作采用不同的PEFT方法,在FL环境中对各类基础模型进行微调。尽管如此,将PEFT引入FL环境也带来了新的挑战,如数据异质性、可扩展性、计算约束和通信开销。针对这些挑战,研究者已提出了多种解决方案。 随着该领域研究的不断深入,系统性综述显得尤为重要。虽然已有若干综述探讨了基础模型在联邦学习中的应用,但尚无工作专门聚焦于FL中的PEFT,并涵盖最新进展。例如,[14, 119] 主要研究FL中基础模型的隐私保护机制,[117, 132] 探讨了基础模型在FL中的未来发展方向;而[64] 虽然对基础模型与FL的结合做出了较全面的综述(包括对PEFT的讨论),但由于发布时间较早,未能涵盖大量近期发布的FL-PEFT方法。 为填补这一空白,本文系统性地回顾了联邦学习环境下的参数高效微调研究。我们基于PEFT方法类别和应用任务,对现有工作进行了分类和梳理,涵盖自然语言处理与计算机视觉等多个方向。 本文的组织结构如下:第二部分介绍联邦学习的基本概念、核心原理、常见挑战及PEFT的基础知识;第三部分基于[42]提出的分类方法,对在FL中应用的PEFT方法进行分类和分析:3.1节探讨加性PEFT方法,即引入新权重参数或修改激活函数;3.2节研究选择性PEFT方法,即只微调部分已有参数;3.3节聚焦于重参数化PEFT方法,如LoRA及其变种在FL中的应用。第四部分根据预训练模型类型及目标任务对文献进行梳理。第五部分提出当前仍未解决的研究挑战,并展望未来的发展方向。最后,第六部分对本文综述的主要发现进行总结。