

随着视频内容的指数级增长,如何高效进行导航、搜索与检索成为一项重大挑战,从而对先进的视频摘要技术提出了更高要求。现有的视频摘要方法主要依赖视觉特征和时间动态信息,但往往难以准确捕捉视频内容的语义,导致生成的摘要片段不完整或语义不连贯。
为应对这一挑战,本文提出了一种全新的视频摘要框架,充分利用近年来大语言模型(Large Language Models, LLMs)的强大能力。我们预期,LLMs从海量数据中学习到的丰富知识能够以更贴近人类语义理解与主观判断的方式评估视频帧,从而有效缓解关键帧选取过程中固有的主观性问题。
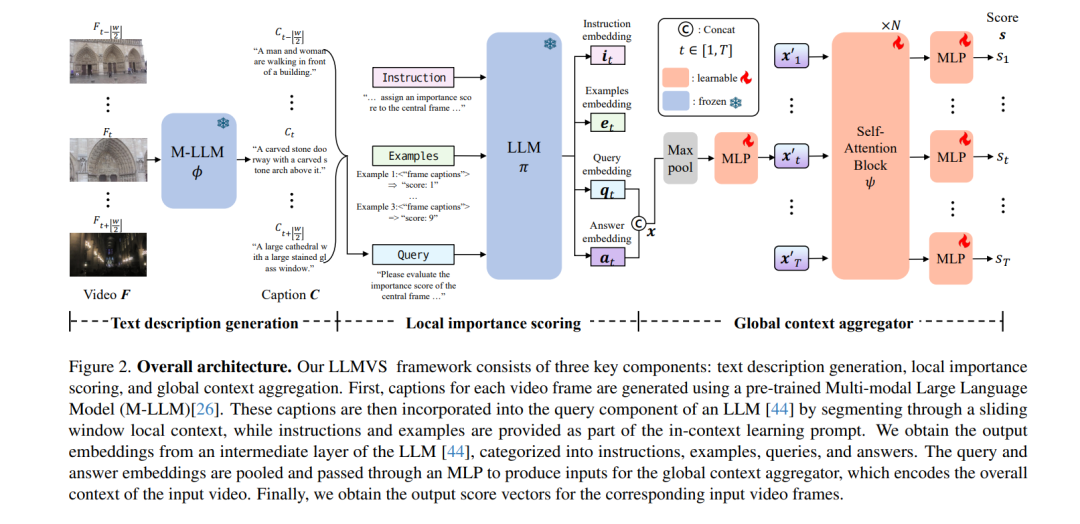
本方法被命名为基于大语言模型的视频摘要(LLM-based Video Summarization, LLMVS),其核心流程为:首先利用多模态大语言模型(Multi-modal LLM, M-LLM)将视频帧转化为描述性字幕序列;随后,基于每帧在局部上下文中的字幕信息,由LLM评估其重要性分数;最后,通过全局注意力机制在整段视频字幕的上下文中对局部评分进行优化,从而确保摘要既保留视频的细节,也反映其整体叙事结构。 实验结果表明,在标准基准测试中,本文提出的方法在性能上显著优于现有方法,充分展示了大语言模型在多媒体内容处理中的巨大潜力。
成为VIP会员查看完整内容
相关内容


相关VIP内容
相关资讯
相关论文