大型语言模型(LLMs)在各种自然语言任务上展现出卓越的性能,但它们容易受到过时数据和领域特定限制的影响。为了解决这些挑战,研究人员主要采用了两种策略:知识编辑和检索增强,通过整合来自不同方面的外部信息来增强LLMs。然而,目前仍然缺乏一个全面的综述。在本文中,我们提出一项回顾,讨论知识与大型语言模型整合的趋势,包括方法的分类、基准和应用。此外,我们对不同方法进行了深入分析,并指出了未来的潜在研究方向。我们希望这篇综述能为社区提供快速访问和对这一研究领域的全面概览,旨在激发未来的研究努力。
大型语言模型(LLMs)已经展示了在其参数中编码现实世界知识的令人印象深刻的能力,以及解决各种自然语言处理任务的显著能力(Brown等,2020年;Hoffmann等,2022年;Zeng等,2022年;Chowdhery等,2022年;Touvron等,2023年;Zhao等,2023b年)。然而,它们在知识密集型任务上仍面临严峻挑战(Petroni等,2021年),这些任务需要大量的现实世界知识。最近的研究表明,LLMs难以学习长尾知识(Kandpal等,2023年;Mallen等,2023年),无法及时更新其参数以捕捉变化的世界(De Cao等,2021年;Kasai等,2022年)(例如,ChatGPT 1的参数只包含2021年9月之前的信息,对最新的世界知识完全不知情),并且受到幻觉的困扰(Zhang等,2023a;Rawte等,2023年;Huang等,2023a年)。为了缓解这些问题,人们越来越关注通过知识编辑或检索增强来整合知识和大型语言模型。知识编辑(De Cao等,2021年;Sinitsin等,2020年)旨在使用一种有效的方法修改LLMs中过时的知识,该方法仅更新部分模型参数。检索增强(Mallen等,2023年;Shi等,2023年;Trivedi等,2023年)采用现成的检索模型从外部语料库中获取相关文档,以帮助大型语言模型并保持其参数不变。已有许多工作提出整合知识和大型语言模型,专注于上述两个方面。然而,这些努力仍然相对零散,缺乏全面和系统的综述。
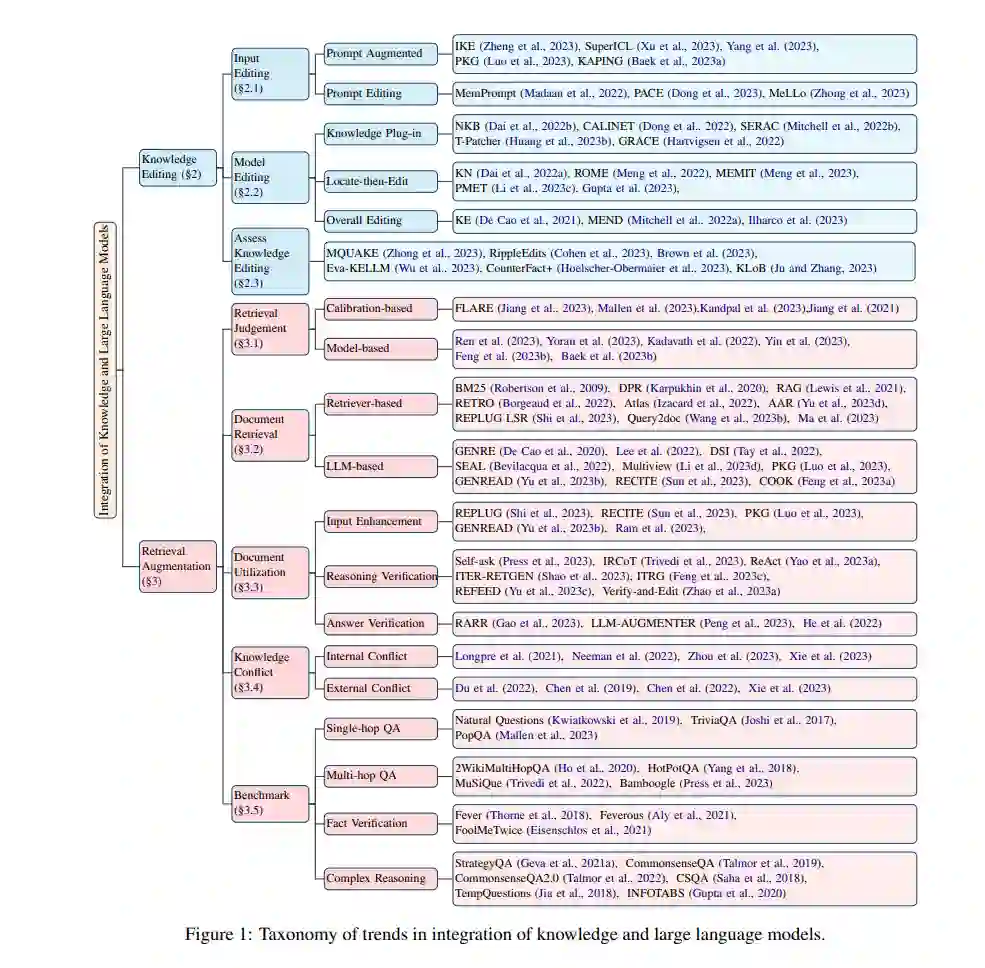
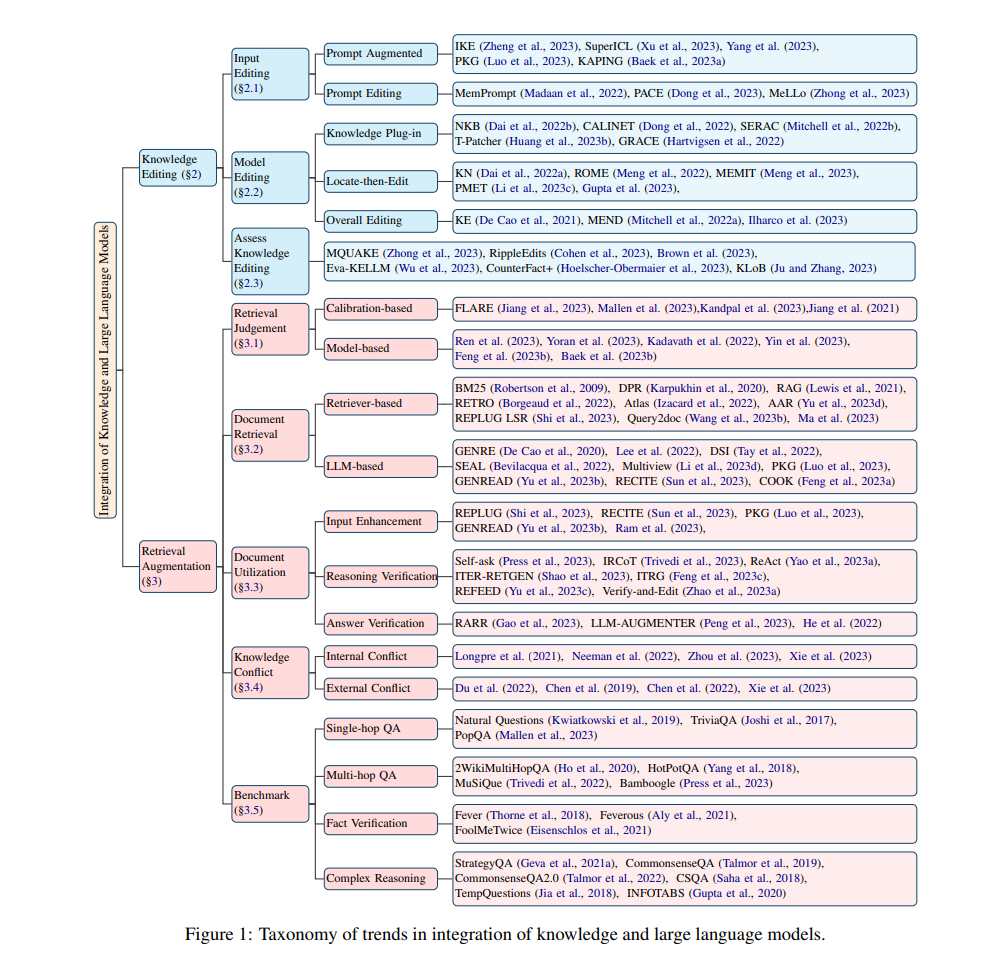
为了填补这一空白,本文提出了我们的综述的具体组织,重点关注知识编辑和检索增强,如图1所示。我们首先系统地介绍了根据模型处理结构的知识编辑方法(§2),包括输入编辑(§2.1),模型编辑(§2.2)以及评估知识编辑(§2.3),涵盖了代表性方法和通用基准。此外,我们对检索增强进行了详细讨论(§3),包括检索判断(§3.1),文档检索(§3.2),文档利用(§3.3),知识冲突(§3.4)和基准(§3.5)。然后,我们总结了一些知识与大型语言模型整合的前沿应用(§4),例如新版Bing 2。最后,为了激发该领域的进一步研究,我们提供了对未来调查方向的洞见(§5)。
2 知识编辑
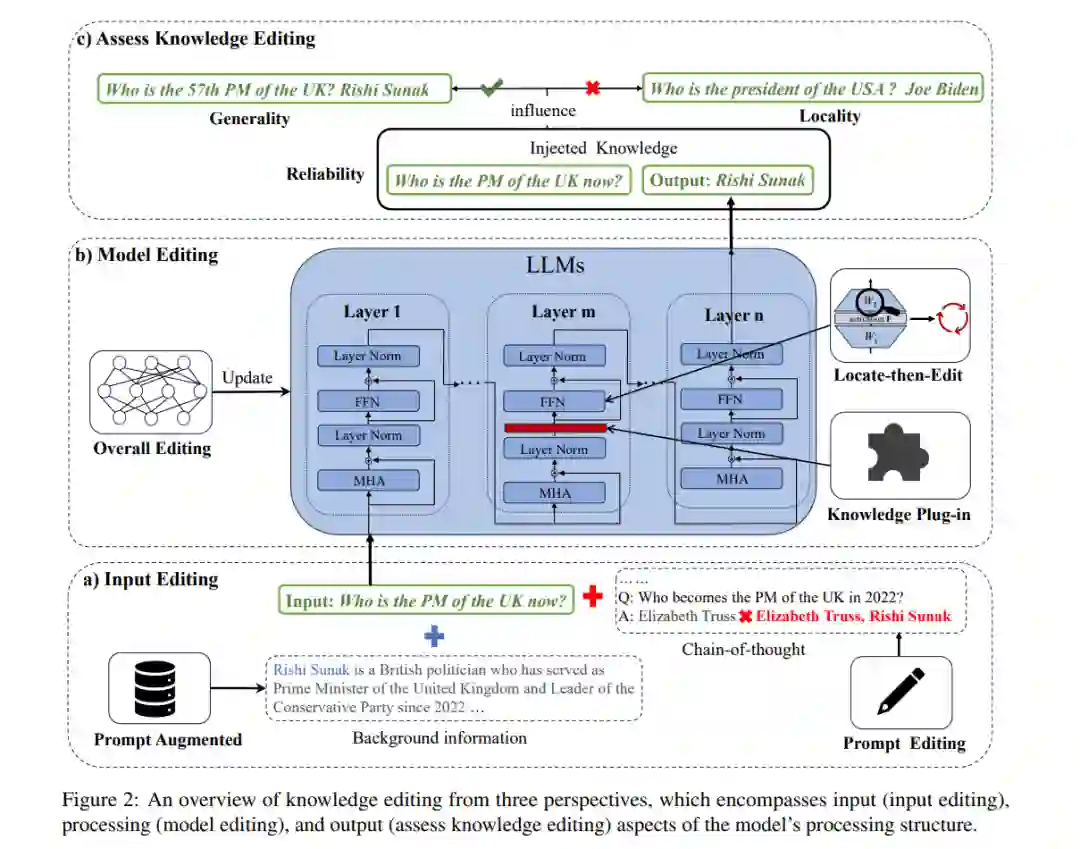
知识编辑是一种新兴方法,通过整合新知识来纠正大型语言模型(LLMs)中的不准确性和更新过时信息。在这一部分,我们深入研究了关于知识编辑的当前工作,特别关注LLMs处理结构在不同方法中的应用。如图2所示,我们将它们分为三类:输入编辑(§2.1),模型编辑(§2.2),和评估知识编辑(§2.3)。
2.1 输入编辑许多大型模型庞大的参数规模和“黑盒”形式常常阻碍它们进行常规的微调,以获取新知识,例如ChatGPT、Bard3。因此,将知识注入LLMs最直接的方法涉及编辑输入(Zheng等,2023;Luo等,2023),这既节省成本又减少资源需求。输入编辑有两个方面:包括外部信息以增强提示,以及基于反馈编辑提示。调整输入不仅提供了一种直观、易理解的新知识过程描述,而且保证了原始模型知识的保存。
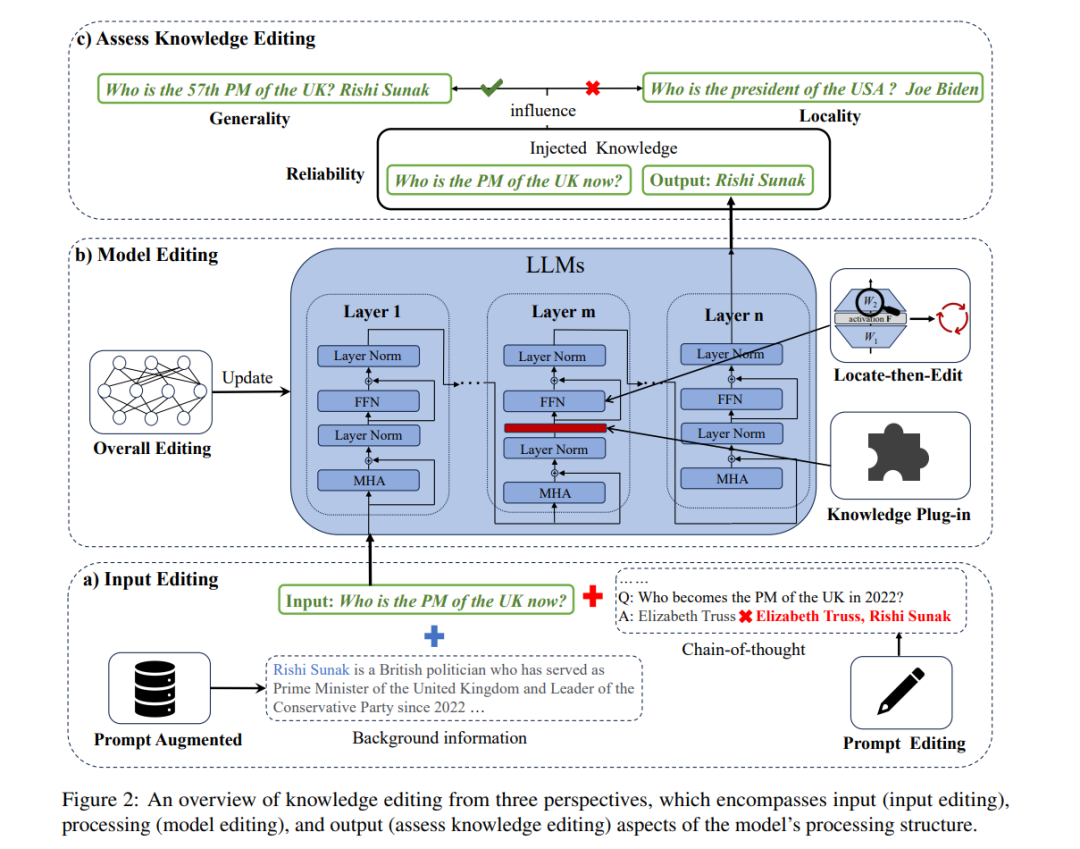
2.2 模型编辑与编辑输入不同,许多研究致力于以参数化方式进行细粒度的模型编辑,这可以确保注入知识的持久性。根据针对LLMs参数的不同操作,我们将它们分为三类,即知识插件、定位然后编辑和整体编辑。
2.3 评估知识编辑在编辑输入和模型之后,可以通过审查输出来评估知识整合的程度。这一小节主要介绍模型评估的特点,并提供表1中知识编辑的一般基准概览。当前用于编辑知识的方法主要旨在整合三元事实知识,这些知识集中在问答(QA)任务上,即ZsRE(Levy等,2017年)。此外,CounterFact是一个专门为知识编辑任务构建的评估数据集,用于衡量与仅仅表面上改变目标词汇相比显著变化的有效性(Meng等,2022年)。评估知识编辑的三个主要属性包括可靠性、通用性、局部性(Yao等,2023b;Huang等, 2023b)。
3 检索增强如第2节所讨论,知识编辑(De Cao等,2021年)是一种有效的方法,通过修改大型语言模型特定部分的参数来更新过时的知识。然而,知识编辑也面临着一些其他问题。首先,目前还不完全清楚知识在大型语言模型中是如何以及在哪里存储的。其次,知识与参数之间的映射关系非常复杂,修改与某些知识对应的参数可能会影响其他知识。在本节中,我们介绍了检索增强,这是一种在保持参数不变的情况下整合知识和大型语言模型的另一种方法。
与主要将外部知识参数化以更新大型语言模型的知识编辑不同,检索增强在推理阶段使用非参数化形式的外部知识。检索增强通常由一个检索器和一个大型语言模型组成。给定输入上下文后,检索器首先从外部语料库中获取相关文档。然后,我们可以在不同阶段使用相关文档来提高大型语言模型的性能。在本节中,我们专注于检索增强的以下关键问题:
• 大型语言模型什么时候需要通过检索来增强?(§3.1) • 如何检索相关文档?(§3.2) • 大型语言模型如何利用检索到的文档?(§3.3) • 如何解决不同文档中的知识冲突?(§3.4)"
检索判断对于检索增强的大型语言模型,一个非常重要的问题是了解LLMs的知识边界(Yin等,2023年)并确定何时检索补充知识。当前的检索判断方法主要分为两类:基于校准的判断和基于模型的判断。
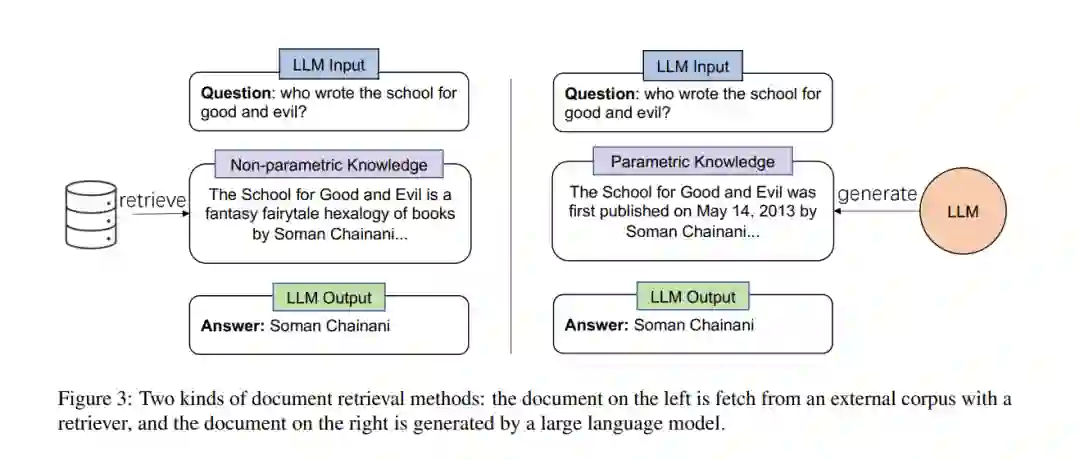
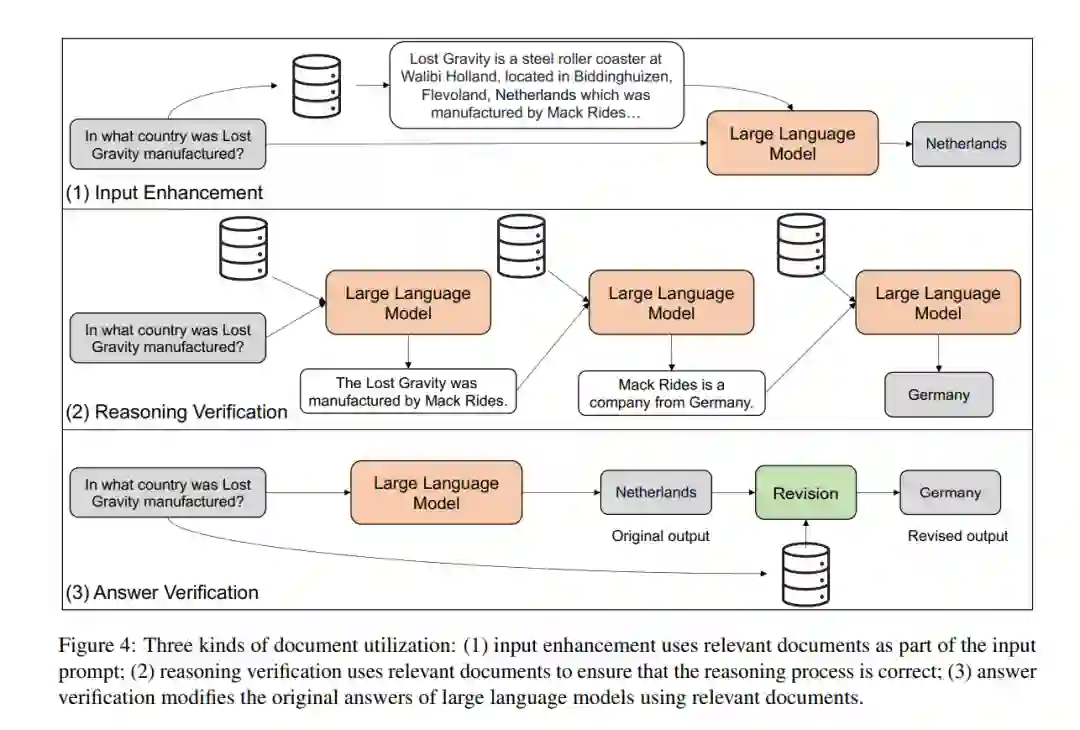
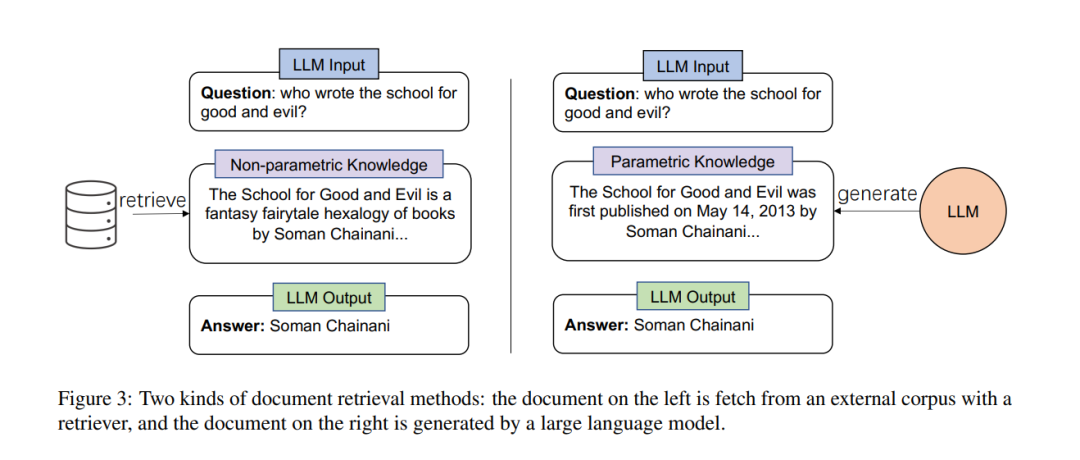
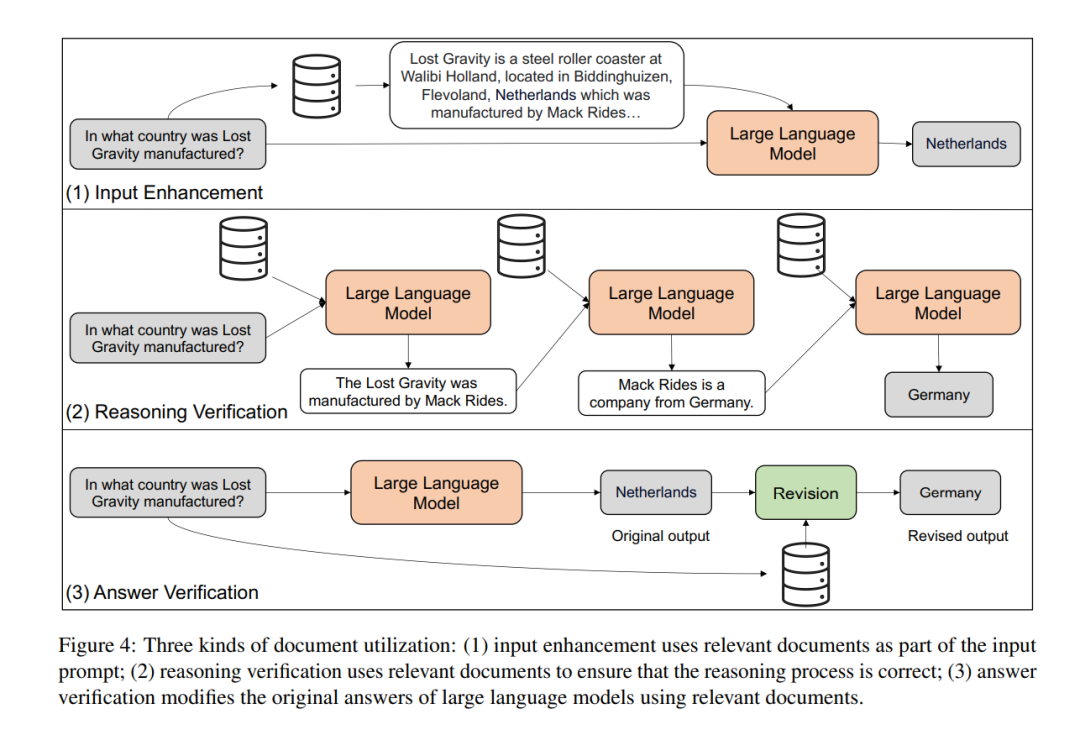
文档检索如图3所示,获取相关文档有两种方法。一种方法是使用检索器从外部语料库(例如维基百科)中获取相关文档。另一种方法是使用大型语言模型生成相关文档。文档利用一旦我们拥有了相关文档,我们如何使用它们来提升大型语言模型的能力?如图4所示,我们将使用文档的不同方式分为三类:输入增强、推理验证和答案验证。
检索增强LLMs中的知识冲突,在模型推理中有两个知识来源,它们的分工模糊且不透明。第一个是通过预训练和微调注入的隐含参数化知识(即它们学习到的权重)。第二个是上下文知识,通常作为文本段落从检索器中获取。知识冲突意味着所包含的信息是不一致和矛盾的。如图5所示,知识冲突有两种类型:内部冲突和外部冲突。内部冲突指的是大型语言模型中的知识与检索文档中的知识之间的不一致。外部冲突指的是检索到的多个文档之间的不一致。
结论
在本文中,我们对知识与大型语言模型的整合进行了综述,并提供了其主要方向的广泛视角,包括知识编辑和检索增强。此外,我们总结了常用的基准和前沿应用,并指出了一些有希望的研究方向。我们希望这篇综述能为读者提供当前进展的清晰图景,并激发更多的工作。