

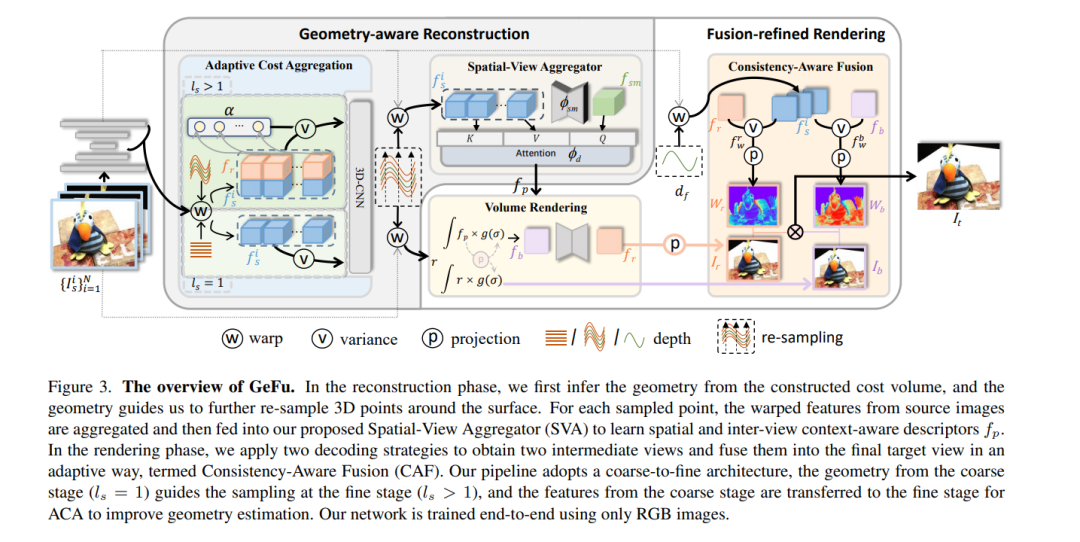
泛化NeRF的目标是为未见过的场景合成新的视角。常见做法包括构建基于方差的成本体积用于几何重建,并编码3D描述符用于解码新视角。然而,现有方法在具有挑战性的条件下显示出有限的泛化能力,这是由于几何不准确、描述符次优和解码策略等因素造成的。我们逐点解决这些问题。首先,我们发现基于方差的成本体积展示出失败模式,因为由于遮挡或反射,对应于同一点的像素的特征在不同视角中可能不一致。我们引入了一种自适应成本聚合(ACA)方法,以增强一致像素对的贡献并抑制不一致的像素对。与之前仅将2D特征融合进描述符的方法不同,我们的方法引入了一个空间-视图聚合器(SVA),通过空间和视图间交互将3D上下文融入描述符。在解码描述符时,我们观察到两种现有的解码策略在不同领域表现出色,它们是互补的。我们提出了一种一致性感知融合(CAF)策略,以利用这两者的优势。我们将上述ACA、SVA和CAF融合进一个粗到细的框架中,称为面向几何感知的重建与融合精炼渲染(GeFu)。GeFu在多个数据集上达到了最先进的性能。代码可在https://github.com/TQTQliu/GeFu 获取。
成为VIP会员查看完整内容
相关内容
Arxiv
30+阅读 · 2023年4月19日
Arxiv
140+阅读 · 2023年4月7日
相关VIP内容
相关资讯
相关论文
Arxiv
30+阅读 · 2023年4月19日
Arxiv
140+阅读 · 2023年4月7日