
CVPR2025 | ODE:多模态大语言模型幻觉的开集动态评估框架
作者: 涂雅涵、胡锐、桑基韬 论文链接: https://cvpr.thecvf.com/virtual/2025/poster/33160 论文代码: https://github.com/Iridescent-y/ODE
01
研究背景 多模态大语言模型(MLLMs)在图像描述、视觉问答等任务中表现出色,但“幻觉”问题始终存在——模型会生成看似合理却与图像内容不符的回答。评估MLLMs中的幻觉对于提高模型可靠性和实际应用至关重要。 先前的研究提出了各种基准来评估MLLMs中的幻觉,重点关注不同类型(例如,存在性幻觉和关系性幻觉)或不同难度级别)。但这些基准普遍存在静态局限性:依赖固定测试数据与有限分布,易引发数据污染风险(即测试数据与训练数据重叠导致性能虚高)。例如,本研究发现:在相同语义分布下,模型在COCO2014子集上的表现显著优于最新互联网图像(图1),表明COCO数据可能已在训练中被记忆,导致评估结果失真。
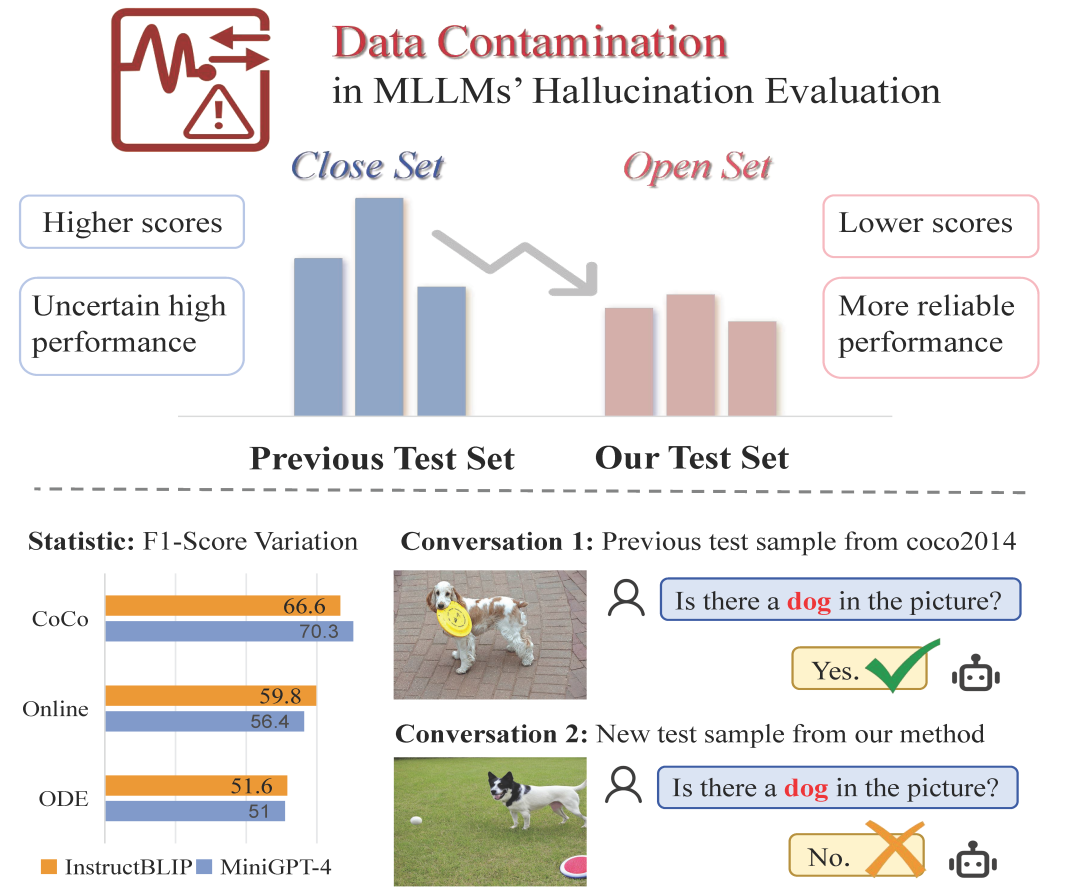
图1:闭集与开集评估方法在多模态大语言模型(MLLMs)中的对比研究表明,开集测试能有效降低数据污染,并为幻觉率评估提供更可靠的衡量依据。 最近研究强调了大语言模型(LLMs)中的数据污染问题。尽管已有工作引入动态评估应对(如DyVal基于有向无环图合成样本,MSTemp重构SST-2数据集样本),但其领域限定,且缺乏针对MLLMs的防污染评估方案。 我们认为,有效的评估基准应该是开放集的,这意味着评估数据在样本和分布级别上对模型都是新颖的。受 LLM 领域污染研究的启发,同时结合多模态模型的特性,本文提出开放集动态评估协议ODE,并具有以下三点特征:(1)确保新数据集在广泛分布上的OOD评估,而非对现有数据集的改写;(2)跨不同模态的动态样本生成;以及(3)从概念粒度到属性粒度再到分布粒度的多层级动态结构。基于这些特征,本文引入了开放集动态评估 (ODE) 协议。 ODE 自动生成数据以评估 MLLM 中的对象幻觉(存在级别与属性级别)。 02
方法介绍
ODE通过四步流程动态生成评估数据:图结构建模真实场景、视觉语义信息的构建、图像生成与过滤、结构化查询设计。
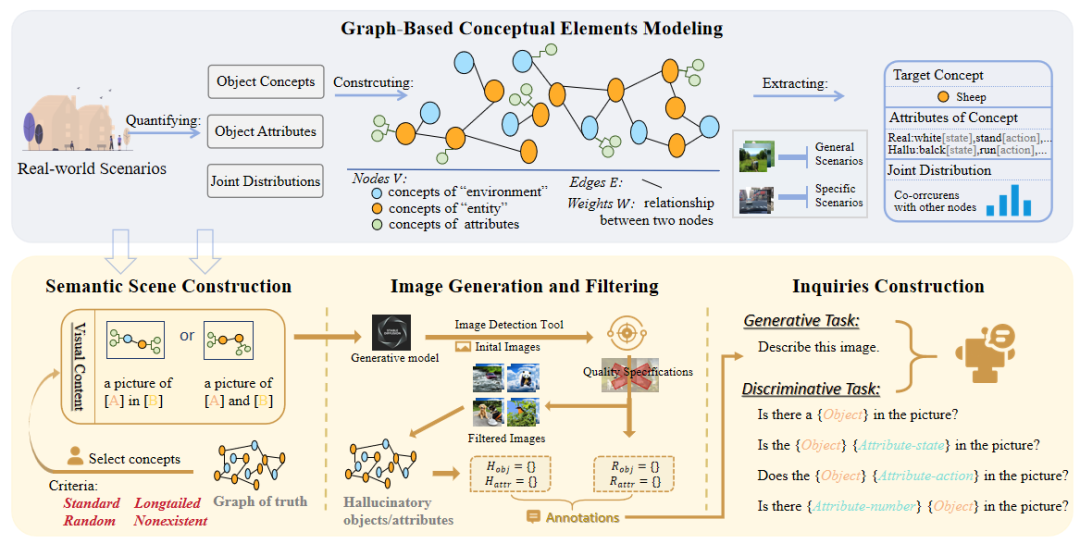
图2:开集动态评估协议的工作流程包括构建图结构并基于该图生成测试样本,具体分为四个步骤。 图结构概念建模: 构建加权图 G=(V,A,E,W)抽象现实场景: ·节点V**:从大规模数据集提取的对象概念(如“猫”、“草地”),区分为实体级与环境级; ·属性A:描述对象的状态、动作、数量等特征; ·边权W:**基于概念共现频率刻画语义关联(如“桌子”与“椅子”的高频共现)。 动态语义场景生成:
基于图结构,依据边权(共现关联程度)的不同,设计四类分布标准抽取概念进行组合,覆盖从高频到虚构的语义关联:高频共现Standard、长尾分布Long-tail**、随机组合Random****、虚构组合Fictional**。在测试集设计中,视觉信息包括所提取到的两个主要的对象概念及其属性(也可能没有特定的属性),并以“实体+实体”、“实体+环境”两种组合方式呈现。****
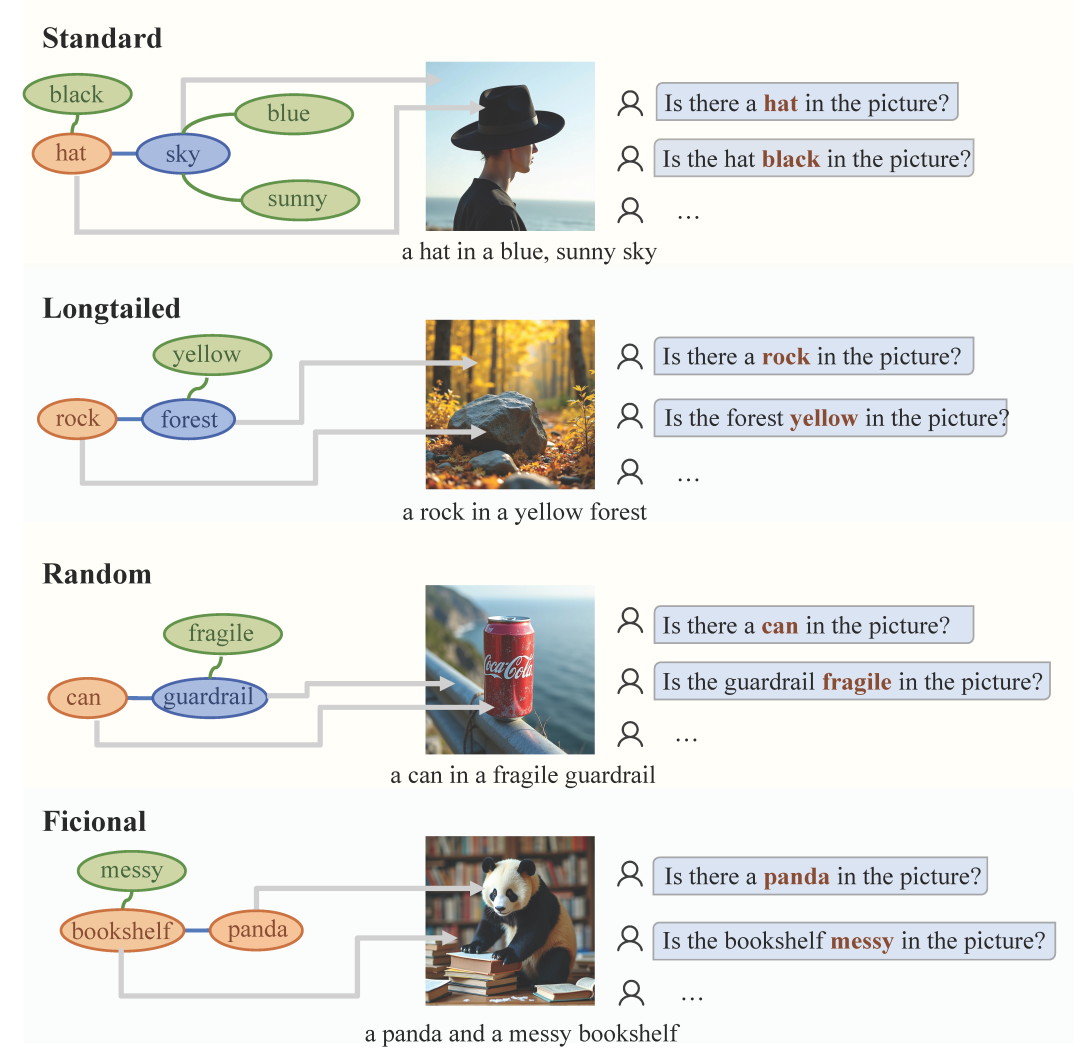
图3:四种分布样本示例。 高质量图像生成与过滤:
为避免模型接触过测试数据,采用文本到图像模型(如 FLUX.1-dev)生成测试图像。通过正向提示(如"clear entity")与负向提示(如"bad anatomy")优化生成质量,动态调整 prompt 、多次生成避免噪声。基于开放词汇检测模型过滤低置信度样本(实体检测置信度<0.65被丢弃),确保评估数据的可靠性。 结构化查询设计:
设计自动化提示模板评估多维度幻觉: 生成任务:“请描述此图像”,检测模型生成内容的真实性; 判别任务:
·存在性:“图片中存在{对象}吗?” ·属性:“图片中的{对象}处于{状态}吗?/执行{动作}吗?/数量为{数量}吗?” ·反事实查询:如“是否存在{虚构对象}?”,检测存在性/属性虚构倾向 03
评估实验
**
**
合成图像有效性验证
**
**
**对比实验:**相同概念下,**模型在COCO数据表现 > 互联网来源最新图像 ≈ ODE合成图像****→ **某些模型潜在数据污染,合成图像与真实图像评估结果近似。
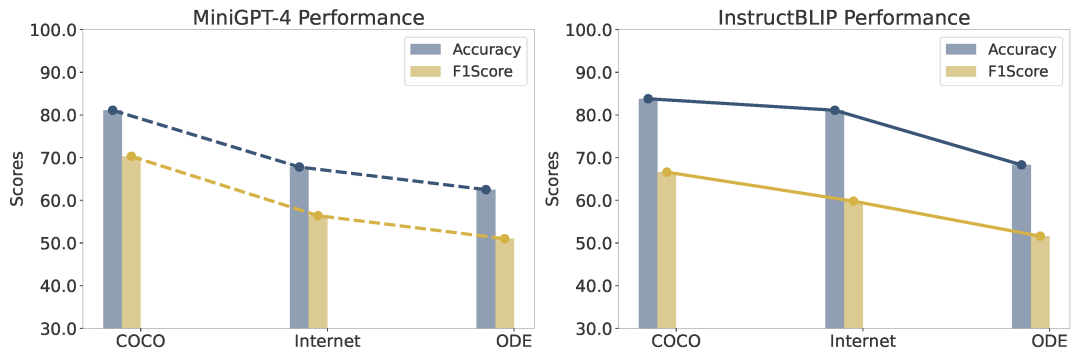
图4:评估效果对比 ****
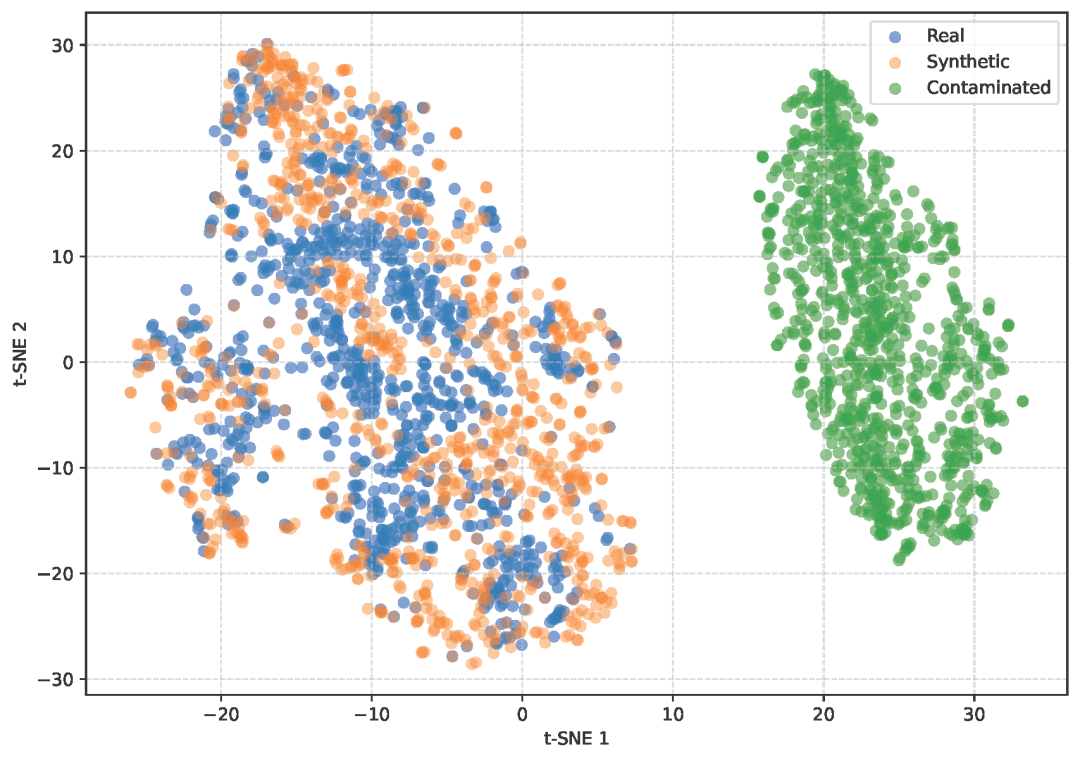
图5:图像特征可视化 **特征空间对齐:人为构造数据污染,三类图像特征(基于详细语义描述生成的图像、受污染图像以及未污染真实图像)的可视化分析表明受污染图像形成异常分布,而合成图像与未污染真实图像高度对齐。验证其评估可靠性。
**
幻觉评估分析
在 Standard、Long-tail、Random、Fictional 四种分布下对 8 种 MLLMs 评估,发现静态基准测试与ODE性能之间的不一致性、分布鲁棒性差异**、任务与属性对语义理解的不同适应程度等现象。******
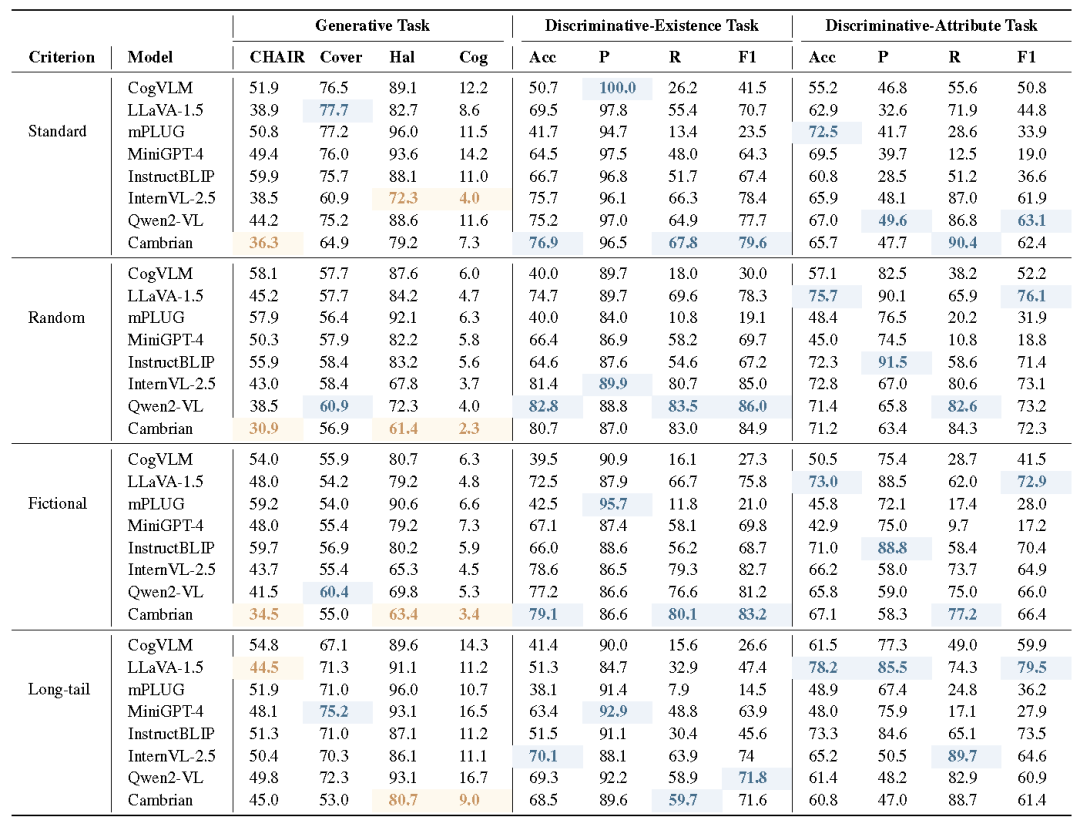
图6:评估结果概览****
动态更新的迭代评估
ODE支持动态更新的benchmark评估机制。更新形式包括引入新的目标概念组合、属性变换,以及更新图的底层知识库,加入更多的物体类别及其关系。文本-图像模型的灵活选择也可以进一步防止风格过拟合,通过多次评估取均值可降低随机性。这种定期更新机制使得benchmark能够覆盖更广泛的分布场景,确保模型评估结果的准确性和全面性。
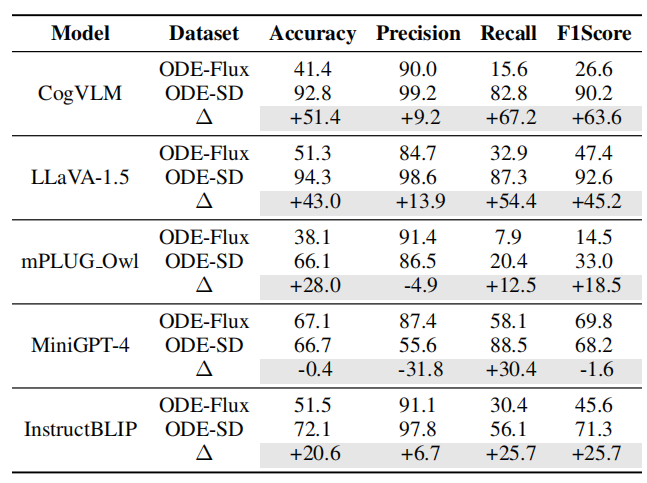
图7:模型在两个数据集上的生成式与判别式任务(对象存在性幻觉)性能对比,并展示数据集间的差异值 04
框架应用 * 幻觉倾向分析与诊断
针对评估结果构建概念-幻觉频率矩阵并聚类,可定位模型弱点,为针对性优化提供方向。
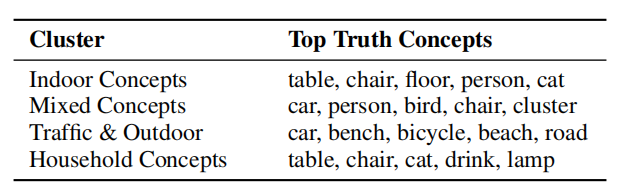
图8:幻觉分析聚类示例 * 领域特定场景的幻觉检测
ODE 可定制化生成稀有概念组合,填补特定领域现有数据集的局限性(如分布狭窄和样本量小导致对罕见或复杂场景的适应性不足)

图9:ODE在交通运输领域构建的稀有分布样本示例。 * 模型微调优化
结果显示利用 ODE 生成的多样化样本进行模型微调,能缓解幻觉问题。
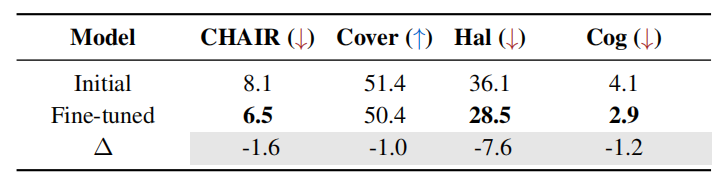
图10:生成式任务性能对比
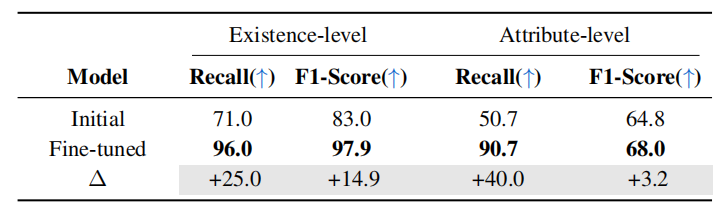
图11:判别式任务性能对比 05
总结
ODE 通过开集动态评估协议,首次解决 MLLMs 物体幻觉评估中的数据污染问题,为 MLLMs 的幻觉研究提供了更可靠的基准。其生成的多样化样本与迭代评估能力不仅揭示了模型真实能力边界,还为模型微调与领域适配提供方案。
E N D 文案:涂雅涵 排版:辛梓源 责任编辑:桑基韬、黄晓雯