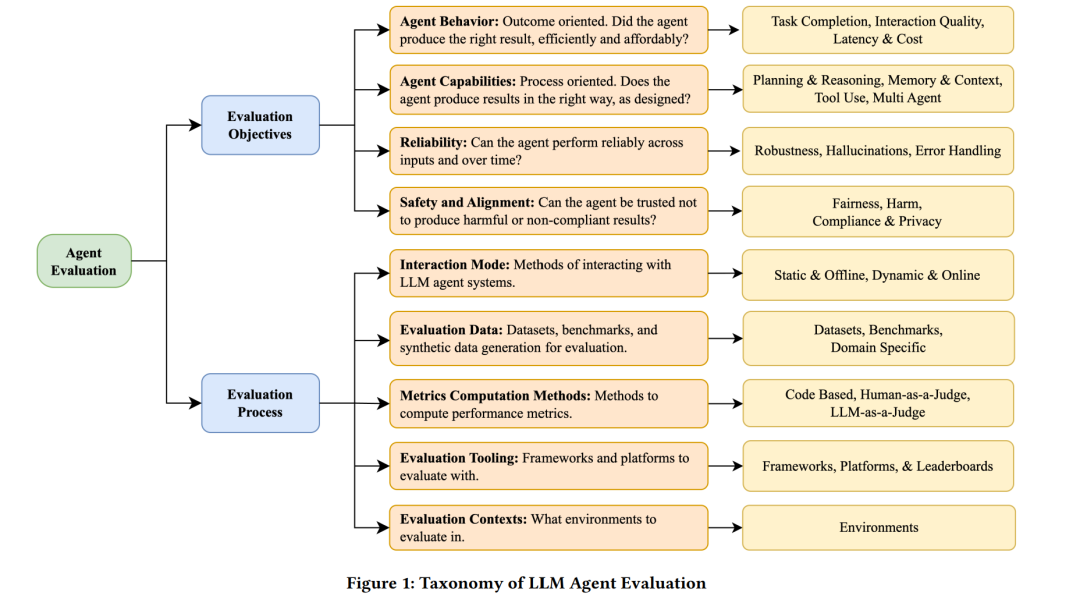
基于大语言模型(LLM)的智能体的兴起为人工智能应用开辟了全新的边界,然而,这类智能体的评估仍是一个复杂且尚不成熟的研究领域。本文综述了LLM智能体评估这一新兴方向,提出了一个二维分类体系,从两个维度组织已有研究:(1)评估目标——评估内容,包括智能体的行为、能力、可靠性与安全性;(2)评估过程——评估方法,涵盖交互模式、数据集与基准、指标计算方法以及相关工具。此外,本文还特别强调了企业级场景中面临的评估挑战,如基于角色的数据访问权限、对系统可靠性的要求、涉及动态与长期交互的任务,以及合规性问题,而这些问题在当前研究中往往被忽视。我们进一步指出了未来的研究方向,包括更全面、更真实且可扩展的评估方法。本文旨在为当前碎片化的智能体评估研究提供清晰的视角,并构建一个系统性评估框架,帮助研究人员与开发者更好地评估LLM智能体在现实世界中的部署能力。
1 引言
基于大语言模型(LLM)的智能体是能够自主或半自主地进行推理、规划与行动的系统,它们正成为人工智能领域快速发展的前沿方向之一 [69, 105]。从客户服务机器人、编程助手到数字助理,LLM智能体正在重新定义智能系统的构建方式。 随着这类智能体从研究原型逐步迈向真实应用场景 [23, 62],如何对它们进行严谨的评估成为一项紧迫而复杂的任务。与孤立评估LLM模型不同,LLM智能体的评估更具挑战性。传统LLM评估通常聚焦于文本生成或问答性能,而LLM智能体则运行在动态、交互性的环境中,它们需要推理并制定计划,调用工具、使用记忆,甚至与人类或其他智能体协作 [20]。这种复杂行为与现实环境紧密耦合,使得标准的LLM评估方法已难以胜任。打个比方,LLM评估就像是测试一台引擎的性能,而LLM智能体的评估则更像是要在各种驾驶条件下全面评估一辆汽车的性能。
LLM智能体的评估方式也不同于传统软件系统的测试。传统软件测试依赖确定性的、静态的行为,而LLM智能体本质上具有概率性和动态性,因此需要全新的评估方法。LLM智能体的评估处于自然语言处理(NLP)、人机交互(HCI)和软件工程等多个领域的交汇点,这对评估方法提出了更高的多学科要求。 尽管该领域的研究兴趣日益增长,目前的综述多聚焦于LLM模型本身的评估,或零散地讨论某些智能体能力,而缺乏系统化的整体视角 [121]。此外,企业级应用对智能体提出了额外的需求,如对数据和系统的安全访问控制、高可靠性保障(以满足审计和合规需求)、更复杂的交互模式等,这些在现有文献中往往被忽略 [107]。本文旨在为从事智能体评估的研究人员与工程实践者提供有价值的参考资料。
本综述的主要贡献包括:
提出了一套LLM智能体评估的分类体系,从两个维度系统梳理已有研究: (1)评估目标(评估什么),包括智能体的行为、能力、可靠性与安全性; (2)评估过程(如何评估),涵盖交互模式、数据集与基准、指标计算方法、评估工具与评估环境。
强调了企业级应用中的特有挑战,包括基于角色的访问控制、可靠性保障、长期交互支持以及合规性要求。
本文其余部分结构如下:第2节介绍用于分析当前智能体评估研究的分类体系;第3节探讨第一个维度“评估目标”,聚焦于应当评估智能体的哪些方面;第4节讨论第二个维度“评估过程”,聚焦评估方法的具体实现;第5节分析企业场景下的评估挑战;第6节则总结当前未解的问题并提出未来研究方向,以推动LLM智能体评估的持续发展。