


**论文题目:**Knowledge Rumination for Pre-trained Language Models **本文作者:**姚云志(浙江大学)、王鹏(浙江大学)、毛盛宇(浙江大学)、谭传奇(阿里巴巴)、黄非(阿里巴巴)、陈华钧(浙江大学)、张宁豫(浙江大学) **发表会议:**EMNLP 2023 (Main Conference) 论文链接:https://arxiv.org/pdf/2305.08732.pdf 代码链接:https://github.com/zjunlp/knowledge-rumination 欢迎转载,转载请注明出处
一、引言
今天介绍我们在大模型时代以前的一篇名为“知识反刍”的工作。反刍是指某些动物为了更好地消化食物,在进食以后将半消化的食物从胃里返回嘴里再次咀嚼。知识反刍则是模仿这个过程,让预训练语言模型再次“咀嚼”他们已有的知识,从而更好地完成相应任务。我们通过简单地添加一个“As far as I know,”的prompt的方式,让预训练模型回忆并“咀嚼”他们已习得的知识,在多个NLP的任务上都达到了更好的效果。 二、动机
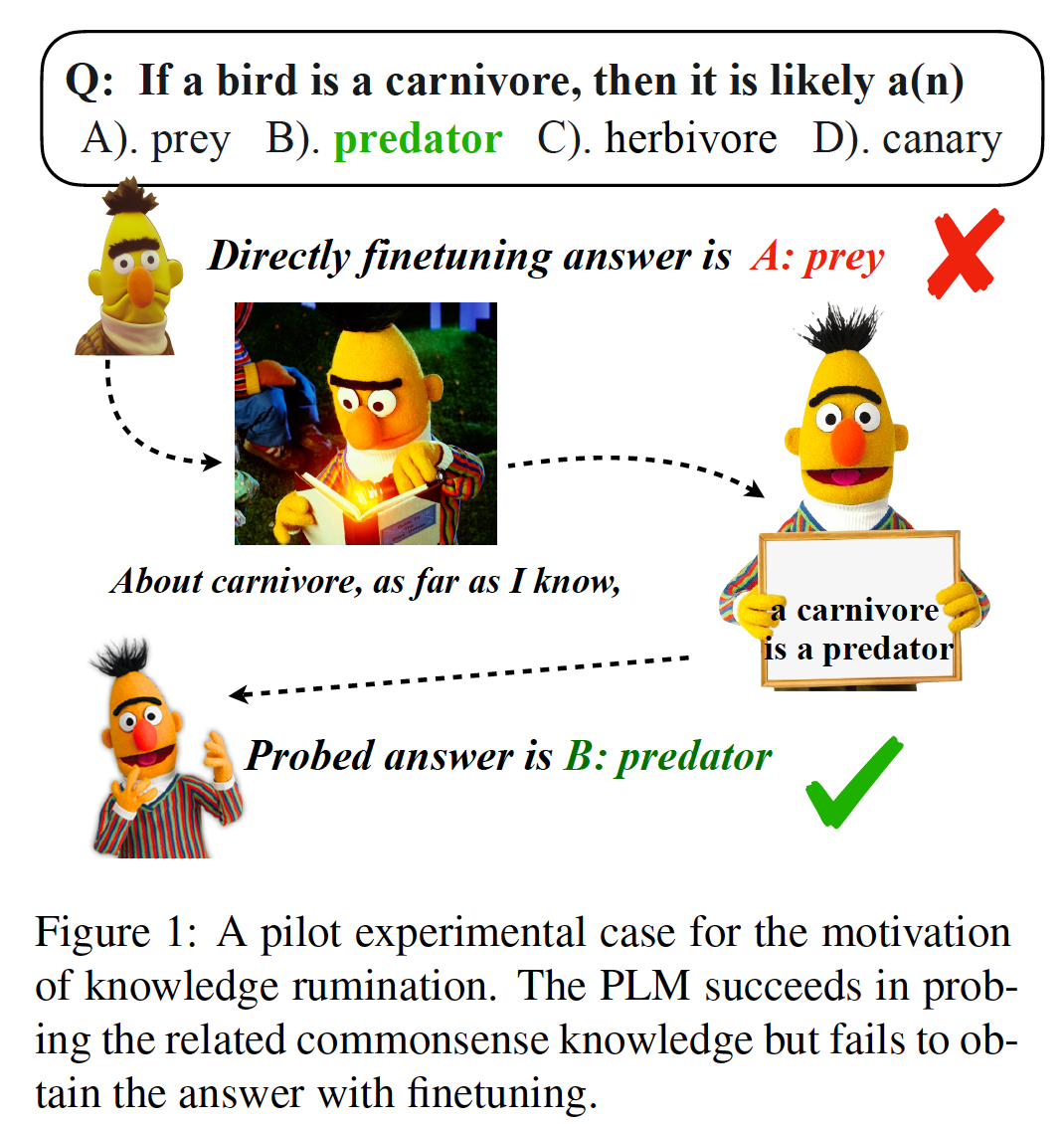
在NLP任务中通过向语言模型中注入外部知识已经是被证明是一种很有效的提升效果的方式,而另外也有研究表明经过预训练的语言模型可以被看作是一个知识库。于是,例如Rainier[1], GKP[2]等工作将大语言模型(例如GPT-3)作为一种外部知识库进行知识的生成。GenRead[3]和RECITE[4]则是利用模型生成的知识来代替检索外部知识库得到的知识,在相关任务上取得了更好的效果。这些工作更多的都是将大模型当作一种能够提供显式知识的知识库,而实际上较小的预训练语言模型的内部也存在着没有充分利用的知识,而我们的工作是尝试去探索一种更加通用的利用模型内部隐性知识的方式。先前的一些研究表明模型在完成一些知识密集性的任务时其实通常都不能很好的利用模型内部的知识。例如在Figure1中,我们用了一个探针任务向预训练语言模型提问“当一只鸟儿是食肉动物的时候,它一般会是什么?”时,模型一开始的回答是错误的。这与认知反映测试(cognitive reflection test)的结论类似:在CRT测试中,参与测试人员通常会做出一些错误的“直觉性”回答,但是当被测试人员重新思考过后,就会回答出正确答案。 为了让模型更好的利用他们参数中存储过的知识,我们模仿这个过程,提出了一种名为知识反刍(Knowledge Rumination)的方法。知识反刍通过简单地添加一个“as far as i know“的prompt的方式,让模型反刍一下参数内的相关知识,从而充分地利用模型潜在的能力。例如图中的例子,模型重新思考了一下关于食肉动物相关的知识,发现食肉动物大多数时候是个捕食者,最后正确地做出了回答。这种简单的思路也能够扩展到很多的NLP任务上。 三、方法介绍
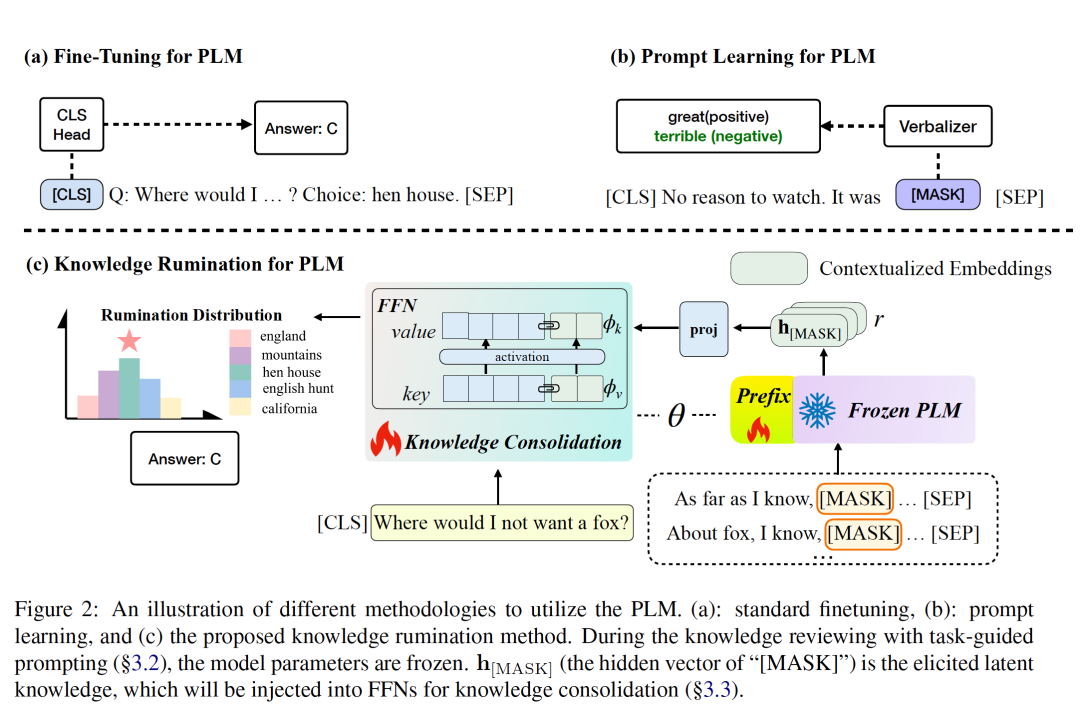
本章节详细地介绍如何在预训练语言模型中应用知识反刍的方法。在整个知识反刍的过程中,我们两次的用到PLM,一次是反刍知识,一次是融合应用知识。 这里以常识推理任务为例。对于一个推理任务,当给定question , context , 候选答案,最后的会得到一个最高得分的答案 . 而在进行知识反刍的过程中,我们将预训练语言模型的原始参数冻结,使用prefix-tuning的方式在训练的过程中让模型回忆出问题相关的知识。具体来说,对于固定的原始模型,我们对每一个问题都添加一个反刍的诱导性提示词,例如"As far as I know,",得到回忆出的知识。在具体实验过程中,我们根据任务的不同类型使用了三种不同的引导模型回忆知识的prompt。
- Background Prompt: 引导模型反思一些与问题相关的背景知识。
- Mention Prompt: 引导模型反思一些实体相关的知识,例如在图2中的例子中,我们让模型对于实体fox回忆相关知识。
- Task Prompt: 引导模型对回忆一些当前任务相关的知识。
在较小的预训练语言模型中,我们使用了向量化的输出作为模型自我反思中得到的知识内容(我们在GPT3等大型模型中进行反刍实验时,让模型直接生成自然语言的知识)。具体来说在有了这些引导模型回忆知识的prompt了之后,我们通过添加一下[MASK] token的方式,让预训练语言模型将他们回忆出的知识向量化地体现在这些token之中,符号化表示如下所示:。在得到与训练模型回忆出的知识后,我们将向量化的知识注入到预训练模型的FFN层中: 并最终得到常识推理任务的结果: 而这个过程中我们需要对最后融合反思知识的模型进行训练,具体的loss函数如下: 四、实验
4.1 数据集
我们在两类benchmark上进行了实验:
- Reasoning benchmark: 包括了 commonsenseQA, PIQA等数据集
- GLUE benchmark
4.2 基线方法
常识推理任务
我们将roberta-large和deberta-large作为我们的底座模型进行了实验同时作为基线进行对比,并且选择了几个知识增强方法作为基线:QA-GNN, GreaseLM, Dragon GLUE benchmark
在GLUE benchmark上我们将LM-BFF作为我们的实验对比方法。
4.3 常识推理结果
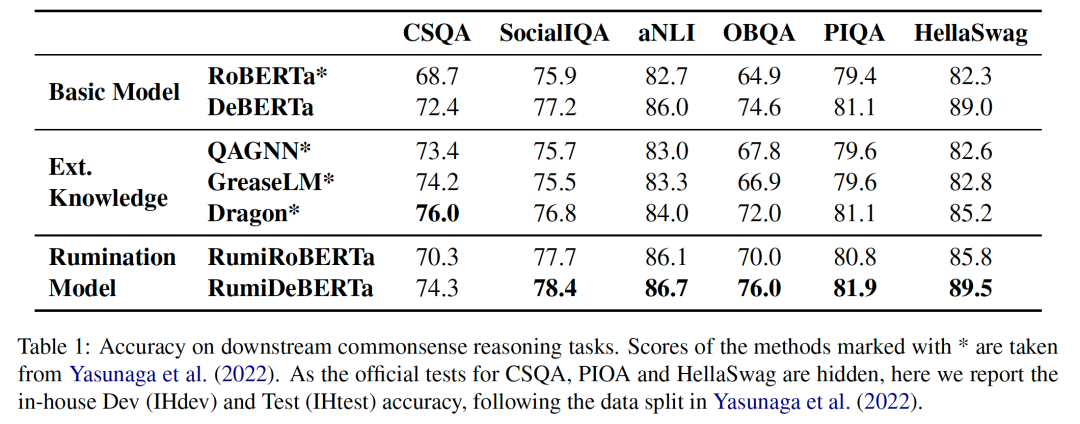
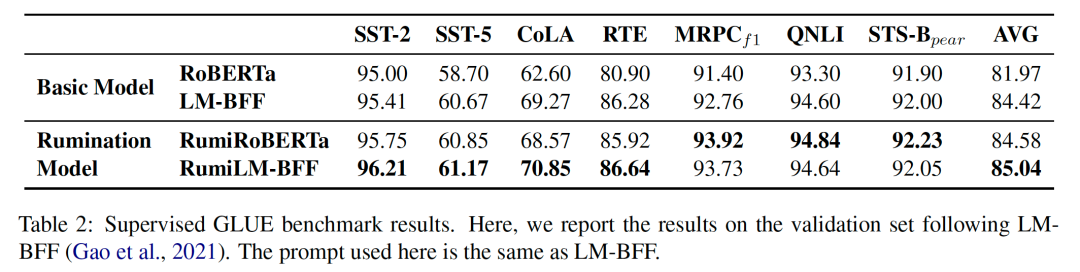
4.4 OOD实验
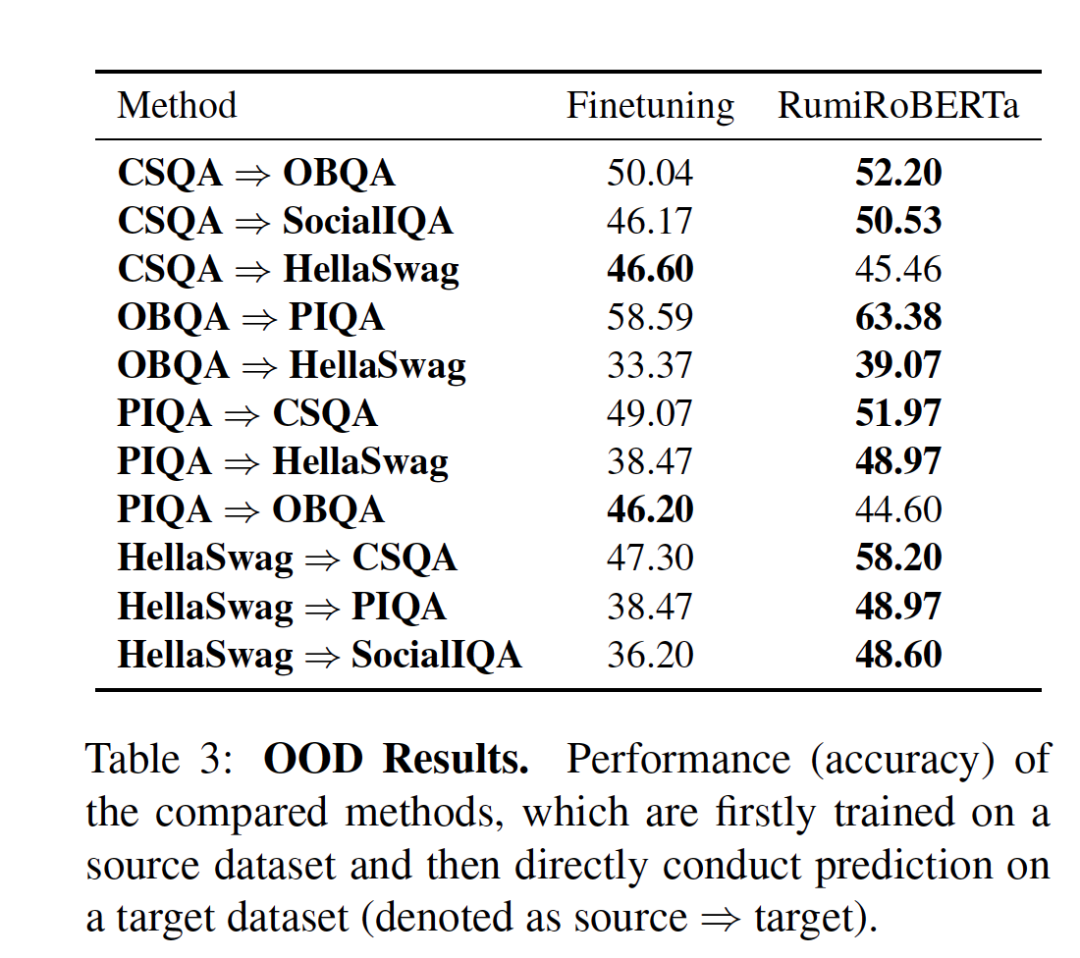
对于不同的数据集我们在训练完rumination模型之后,在out-of-distribution的数据集上进行了实验验证,可以看到大多数情况下反刍模型带来的out-of-distribution能力要比微调要好。
五、分析
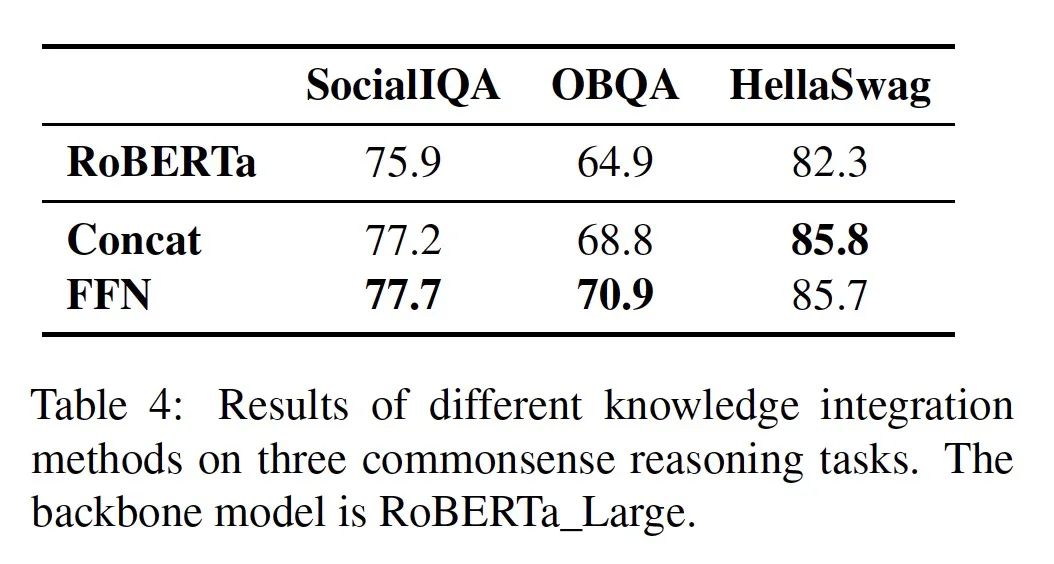
5.1 不同的知识融合方式
5.2 模型究竟反刍了些什么?
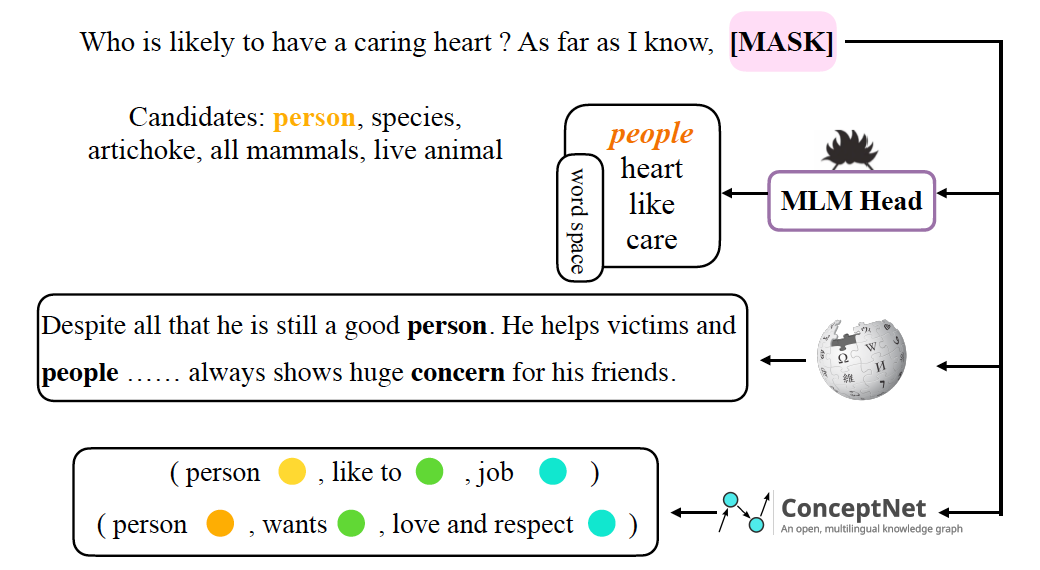
在知识反刍得到了比较好的实验结果之后,我们也探究了模型究竟反刍了些什么的这个问题。我们从实验中挑选了模型原来回答错误,但在反刍之后回答正确的case进行了详细的分析。 我们将这个case中生成的反刍向量过了一层MLM head,得到了这些token映射的词,并且我们还将用这些向量与wikipidea以及conceptNet中的语料进行相似度计算。可以看到在这个例子中,预训练语言模型能够回忆起一些与答案相近的知识,例如people,good person等。 5.3 大模型知识反刍
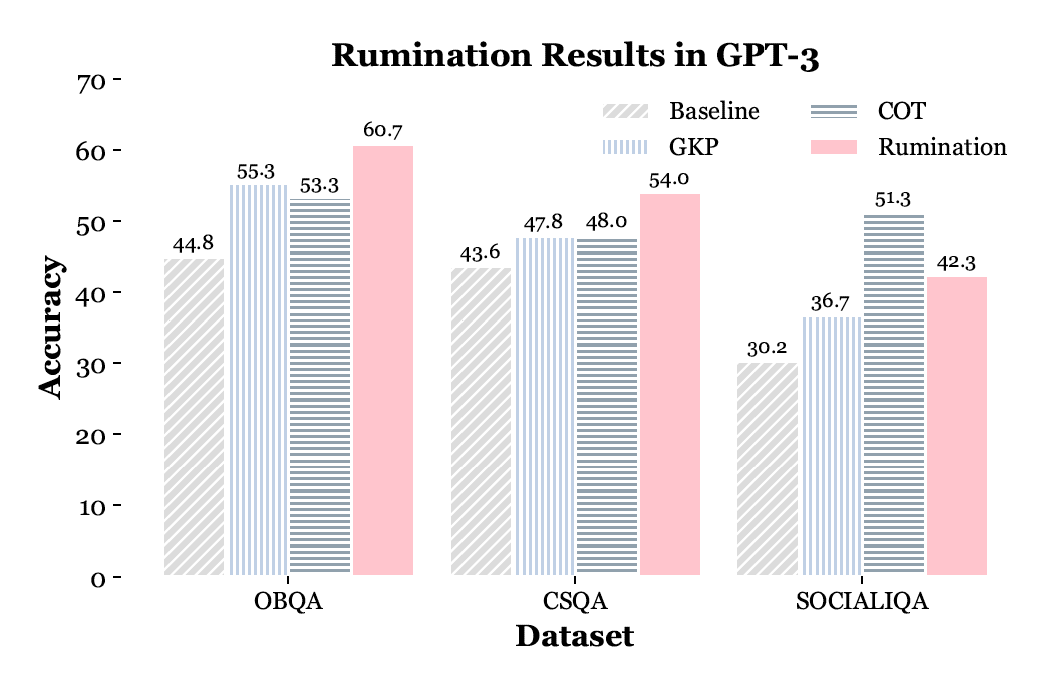
现在人们更多地会应用黑盒的大语言模型,因此我们也将知识反刍的思路在大模型上(GPT-3)进行了实验。在先前的一些工作中(GKP)其实也已经有了类似的思路,通过prompt的方式让大模型返回一些相关的知识。这里我们在之前工作的基础上,通过添加一个According to the [Knowledge], the answer is 的prompt的方式,让模型融合之前他们反刍出来的知识。而CoT这种生成推理路径的方法实际上也是一种充分利用模型本身的知识的方法,因此我们也将其作为实验对比。 可以看到大模型在反刍相关知识后还是能够得到较好的效果的。而在模型推理的过程中如何更好地利用他们内部的知识也是一个未来可探索的方向。 5.4 错误分析
我们在大模型中进行反刍的时候,对反刍的实验进行了定量的错误分析。我们将错误定义为四种不同的类型。
- Failure to Utilize:模型反刍出了有用的知识,但是在后续并没有完成正确的回答
- Ineffective Rumination:在反刍的知识中,排序最靠前的知识与完成对应任务并不相关,但是在剩余的知识中有相关的知识。
- Incorrect Memory:模型反刍出来的知识是错误的
- Missing Information:模型并没有完成任务相关的知识
我们人工的对100个bad case进行了分析,可以看到大部分情况下错误的出现还是由于模型中并没有对应的知识。

六、总结
在这篇工作中我们模仿人类反思知识的模式,提出了知识反刍的方法,可以作为一种比较通用的利用模型内部知识的方式。同时我们进行了详细的实验分析了在反刍过程中模型实际上想起了一些什么知识。在未来,我们计划将知识反刍应用到更多的自然语言处理任务和更多类型的模型中。如果对文章中方法以及实验的细节感兴趣,欢迎大家阅读原文或在github上提出issue。
参考文献
[1] RAINIER: Reinforced Knowledge Introspector for Commonsense question Answering. [2] Generated Knowledge Prompting for Commonsense Reasoning. [3] Generate Rather Than Retrieve: Large Language Models are Strong Context Generators. [4] Recitation-Augmented Language Models.
