

大型语言模型(Large Language Models,LLMs)已经深刻改变了自然语言处理领域,但其内部机制在很大程度上仍然是不透明的。近年来,机制可解释性(mechanistic interpretability)作为理解大语言模型内部工作原理的重要途径,受到了研究界的广泛关注。在众多机制可解释性方法中,稀疏自编码器(Sparse Autoencoders,SAEs)因其能够将大语言模型中复杂、叠加的特征解耦为更具可解释性的组成部分,而逐渐成为一种极具潜力的方法。 本文对用于解释和理解大语言模型内部机制的稀疏自编码器方法进行了系统而全面的综述。本文的主要贡献包括: (1)系统梳理了稀疏自编码器的技术框架,涵盖其基本结构、设计改进以及有效的训练策略; (2)总结并分析了对 SAE 特征进行解释的不同方法,并将其划分为基于输入的解释方法与基于输出的解释方法; (3)讨论了用于评估 SAE 性能的多种评测方法,涵盖结构层面与功能层面的评价指标; (4)探讨了稀疏自编码器在理解与操控大语言模型行为方面的实际应用。
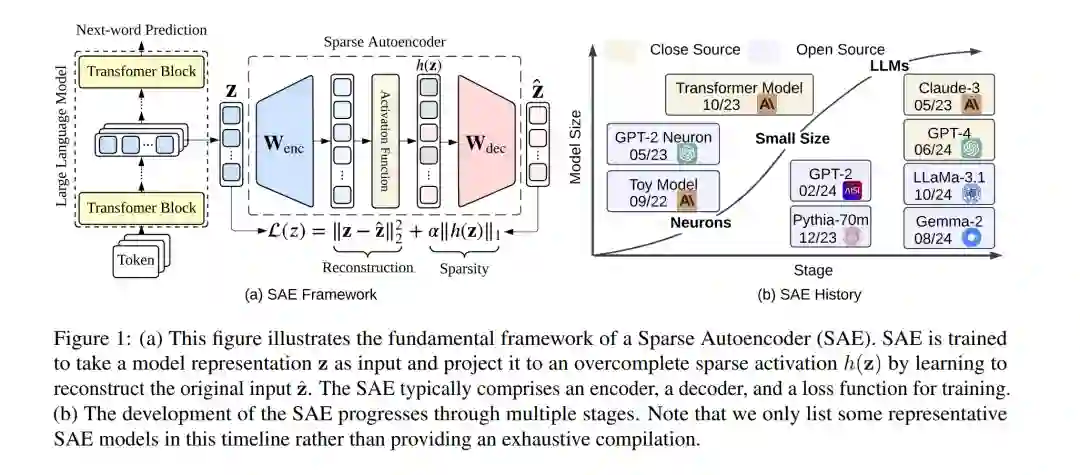
1 引言
大型语言模型(Large Language Models,LLMs),如 GPT-4、Claude-3.5、DeepSeek-R1 和 Grok-3,已成为自然语言处理领域中极具影响力的工具,在文本生成、复杂推理等多种任务上展现出卓越能力。然而,随着模型规模和结构复杂度的不断提升,理解其内部表征与决策过程正变得愈发困难。大语言模型所呈现出的这种“黑箱”特性,促使研究界对机制可解释性(mechanistic interpretability)产生了日益浓厚的兴趣。该研究方向旨在将大语言模型拆解为可理解的组成部分,并系统性地分析这些组成部分之间的相互作用,从而揭示模型行为的内在机理。 在众多用于解释大语言模型的方法中,稀疏自编码器(Sparse Autoencoders,SAEs)逐渐成为一条尤为有前景的研究路线,尤其在应对大语言模型可解释性中的一个核心挑战——多语义性(polysemanticity)方面表现突出。大语言模型中的许多神经元往往同时对多个看似无关的概念或特征作出响应,这种现象被称为多语义性。其成因通常被认为与叠加表示(superposition)有关,即模型通过将多个独立特征以线性组合的方式编码到有限数量的神经元中,从而在神经元数量受限的情况下表示更多特征。 稀疏自编码器通过学习一种过完备且稀疏的激活表示,为缓解这一问题提供了有效途径。具体而言,SAE 在重构目标网络某一层激活的同时引入稀疏性约束,从而将原本叠加在一起的特征解耦为更具可解释性的表示单元。借助这种方式,SAE 能够从模型激活中提取出数量更多、语义更为单一(monosemantic)的特征,为理解大语言模型正在处理的信息提供更清晰的视角。已有研究表明,该方法有望将原本难以理解的激活空间转化为更加符合人类直觉的表示形式,从而为复杂模型的机制分析提供一种更为有效的“解释词汇”。
1.1 贡献与独特性
本文贡献
本文围绕稀疏自编码器在大语言模型可解释性中的应用进行了系统而全面的综述,主要贡献体现在以下几个方面: 1. 系统梳理了稀疏自编码器的技术框架,包括其基本结构、多种设计改进方案以及有效的训练策略(第 2 节)。 1. 总结并分析了针对 SAE 特征的不同解释与分析方法,并将其整体划分为基于输入的解释方法与基于输出的解释方法两大类(第 3 节)。 1. 讨论了评估稀疏自编码器性能的多种评价方法,涵盖结构性指标与功能性指标两个层面(第 4 节)。 1. 探讨了稀疏自编码器在理解与操控大语言模型行为方面的现实应用场景(第 5 节)。 1. 此外,在附录中,我们进一步介绍了提出 SAE 方法的关键动机,讨论其与更广义机制可解释性研究之间的联系,给出补充实验评估,并总结当前研究面临的挑战与潜在的发展方向。

