

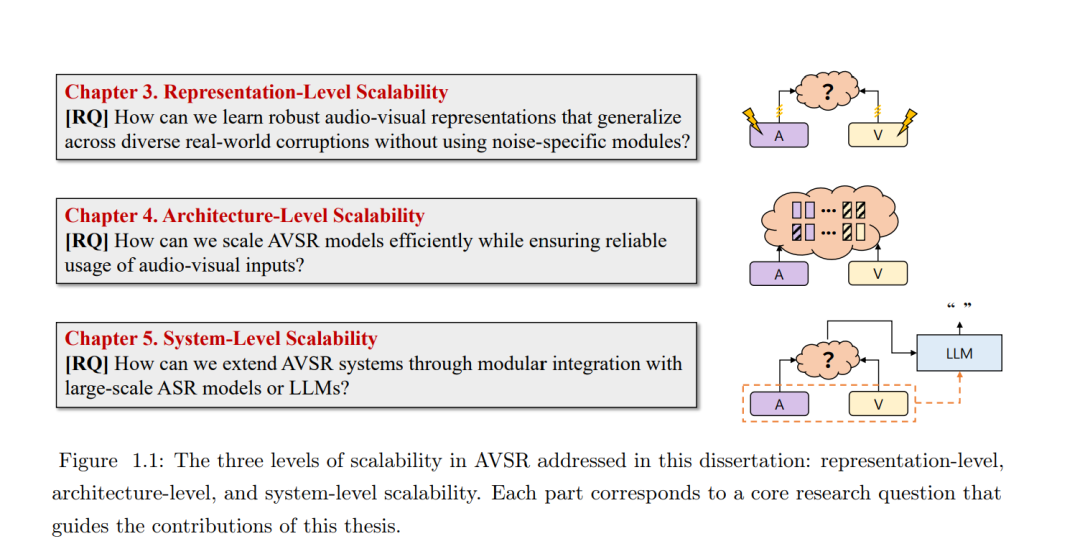
音视联合语音识别(Audio-Visual Speech Recognition,AVSR)系统在实际部署中面临着根本性的挑战:在真实世界环境下,由于不可预测的声学噪声和视觉干扰,其性能往往出现显著退化。本文指出,要克服这些挑战,必须采用一种系统化、分层式的方法,从表示、架构和系统三个层面实现稳健且可扩展的能力。 在表示层面,本文研究了构建统一模型的方法,使其能够学习对多种真实世界扰动具有内在鲁棒性的音视特征表示,从而在无需引入特定场景或任务专用模块的情况下,实现对新环境的有效泛化能力。 在架构层面,针对模型可扩展性问题,本文探索了在保证多模态输入自适应且可靠利用的前提下,高效扩展模型容量的方法,提出了一种能够根据输入特性智能分配计算资源的框架,以提升多模态建模的效率与稳定性。 在系统层面,本文进一步提出通过与大规模基础模型的模块化集成来扩展系统功能的方法,充分利用其强大的认知与生成能力,从而最大化最终的语音识别准确率。 通过在上述三个层面上系统性地提出解决方案,本文旨在构建一套面向下一代的、稳健且可扩展的 AVSR 系统,以满足真实世界应用中对高可靠性的严格需求。 关键词:音视联合语音识别,多模态表示学习,混合专家模型,生成式错误校正,大语言模型
成为VIP会员查看完整内容



