【Embedding】fastText:极快的文本分类工具
进入该链接留言送5本书:
《深度学习训练营 21天实战TensorFlow+Keras+scikit-learn》
今天我们来看 Mikolov 大佬 2016 年的另一大巨作——fastText。2013 年大佬在 Google 开源了 Word2Vec,2016 年刚就职于 FaceBook 就开源了 fastText,全都掀起了轩然大波。
fastText 模型有两篇相关论文:
-
《Bag of Tricks for Efficient Text Classification》 -
《Enriching Word Vectors with Subword Information》
截至目前为止,第一篇有 1500 多引用量,第二篇有 2700 多引用量。
从这两篇文的标题我们可以看出来 fastText 有两大用途——文本分类和 Word Embedding。
由于 fastText 模型比较简单,所以我们可以把两篇论文放在一起看。
1. Introduction
fastText 提供了简单而高效的文本分类和 Word Embedding 方法,分类精度比肩深度学习而且速度快上几个数量级。
举个例子:使用标准的 CPU 可以在十分钟的时间里训练超过 10 亿个单词,在不到一分钟的时间里可以将 50 万个句子分到 31 万个类别中。
可以看到 fastText 的速度有多惊人。
2. fastText
fastText 之所以能做到速度快效果好主要是两个原因:N-Gram 和 Hierarchical softmax。由于 Hierarchical softmax 在 Word2Vec 中已经介绍过了,所以我们只介绍一下 N-gram。
2.1 N-gram
N-gram 是一种基于统计语言模型的算法,常用于 NLP 领域。其思想在于将文本内容按照字节顺序进行大小为 N 的滑动窗口操作,从而形成了长度为 N 的字节片段序列,其片段我们称为 gram。
以“谷歌是家好公司” 为例子:
-
二元 Bi-gram 特征为:谷歌 歌是 是家 家好 好公 公司 -
三元 Tri-gram 特征为:谷歌是 歌是家 是家好 家好公 好公司
当然,我们可以用字粒度也可以用词粒度。
例如:谷歌 是 家 好 公司 二元 Bi-gram 特征为:谷歌是 是家 家好 好公司 三元 Tri-gram 特征为:谷歌是家 是家好 家好公司
N-gram 产生的特征只是作为文本特征的候选集,后面还可以通过信息熵、卡方统计、IDF 等文本特征选择方式筛选出比较重要的特征。
2.2 Embedding Model
这边值得注意的是,fastText 是一个库,而不是一个算法。类似于 Word2Vec 也只是一个工具,Skip-Gram 和 CBOW 才是其中的算法。
fastText is a library for efficient learning of word representations and sentence classification.
”
fastText 在 Skip-Gram 的基础上实现 Word Embedding,具体来说:fastText 通过 Skip-Gram 训练了字符级别 N-gram 的 Embedding,然后通过将其相加得到词向量。
举个例子:对于 “where” 这个单词来说,它的 Tri-gram 为:“<wh”, “whe”, “her”, “ere”, “re>”。由于字符串首尾会有符号,所以这里用 < 表示前缀, > 表示后缀。textFast 是对 这些 Tri-gram 进行训练,然后将这 5 个 tri-gram 的向量求和来表示 “where” 的词向量。
这样做主要有两个好处:
-
低频词生成的 Embedding 效果会更好,因为它们的 N-gram 可以和其它词共享而不用担心词频过低无法得到充分的训练; -
对于训练词库之外的单词(比如拼错了),仍然可以通过对它们字符级的 N-gram 向量求和来构建它们的词向量。
为了节省内存空间,我们使用 HashMap 将 N-gram 映射到 1 到 K,所以单词的除了存储自己在单词表的 Index 外,还存储了其包含的 N-gram 的哈希索引。
2.3 Classification Model
一般来说,速度快的模型其结构都会比较简单,fastText 也不例外,其架构图如下图所示:
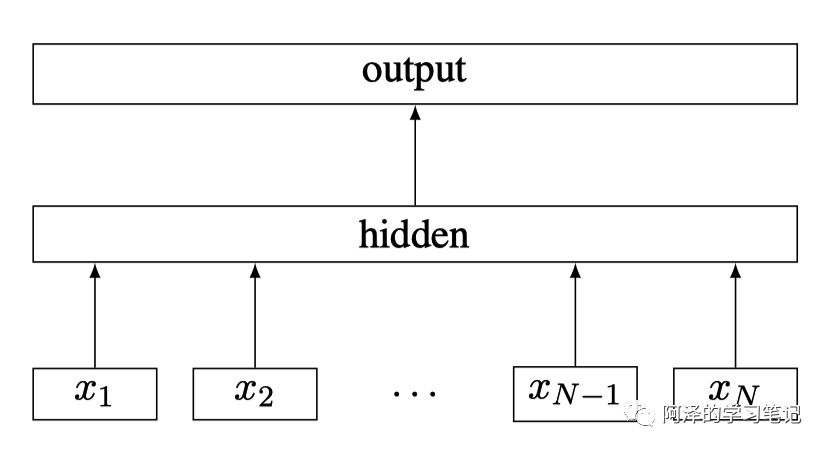
其中, 为一个句子的 N-gram 特征。
我们看到这个架构是不是感觉似曾相似?
fastText 与 Word2Vec 的 CBOW 架构是非常相似的,但与 CBOW 不同的是:fastText 输入不仅是多个单词 Embedding 向量,还将字符级别的 N-gram 向量作为额外的特征,其预测是也不是单词,而是 Label(fastText 主要用于文本分类,所以预测的是分类标签)。
3. Experiment
我们简单看下 fastText 的两个实验——Embedding 和文本分类;
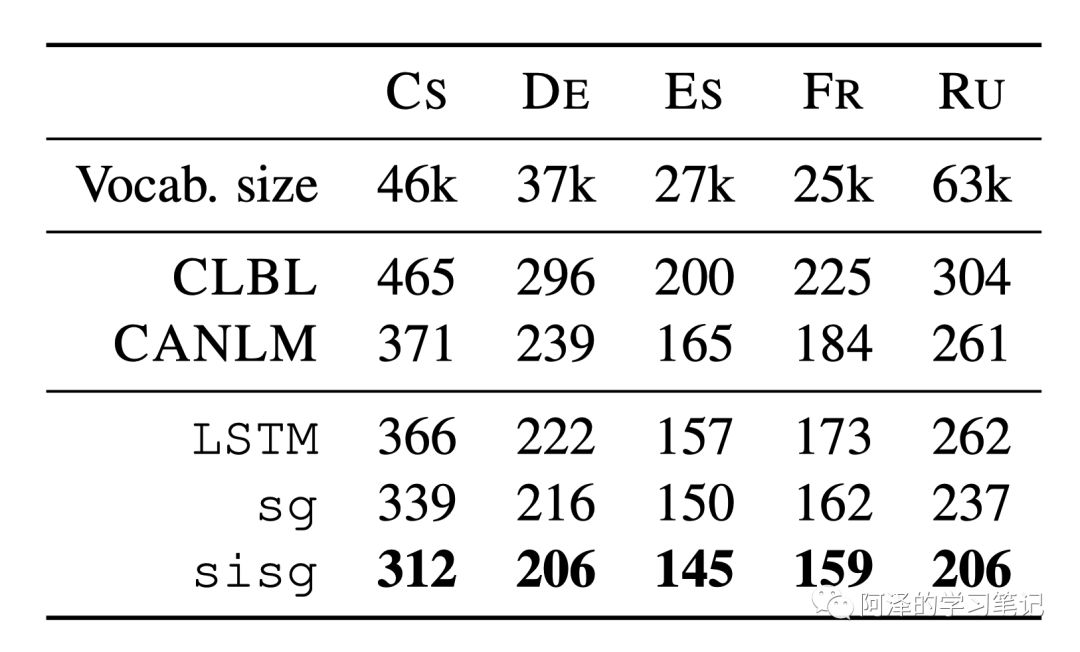
3.1 Embeddng
sisg 是 fastText 用于 Embedding 的模型,实验效果如下:
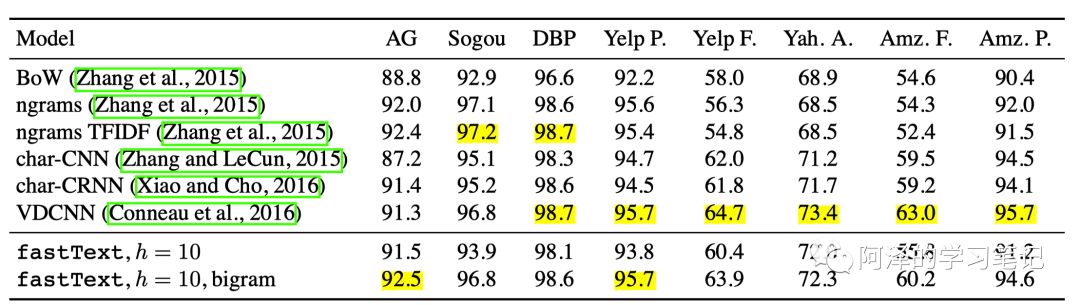
3.2 Classification
分类实验的精度 fastText 比 char-CNN、 char-RCNN 要好,但比 VDCNN 要差。(但这里注意:fastText 仅仅使用 10 个隐藏层节点 ,训练了 5 次 epochs。)
在速度上 fastText 快了几个数量级。(此处注意:CNN 和 VDCNN 用的都是 Tesla K40 的 GPU,而 fastText 用的是 CPU)
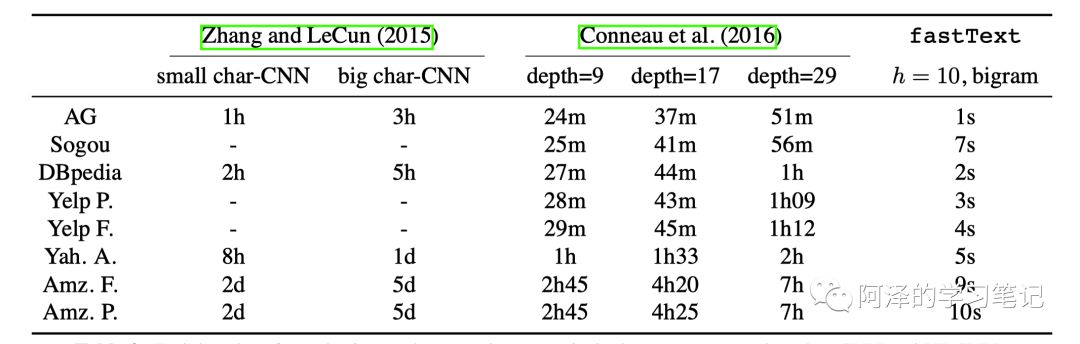
下面是标签预测的结果,两个模型都使用 CPU 并开了 20 个线程:
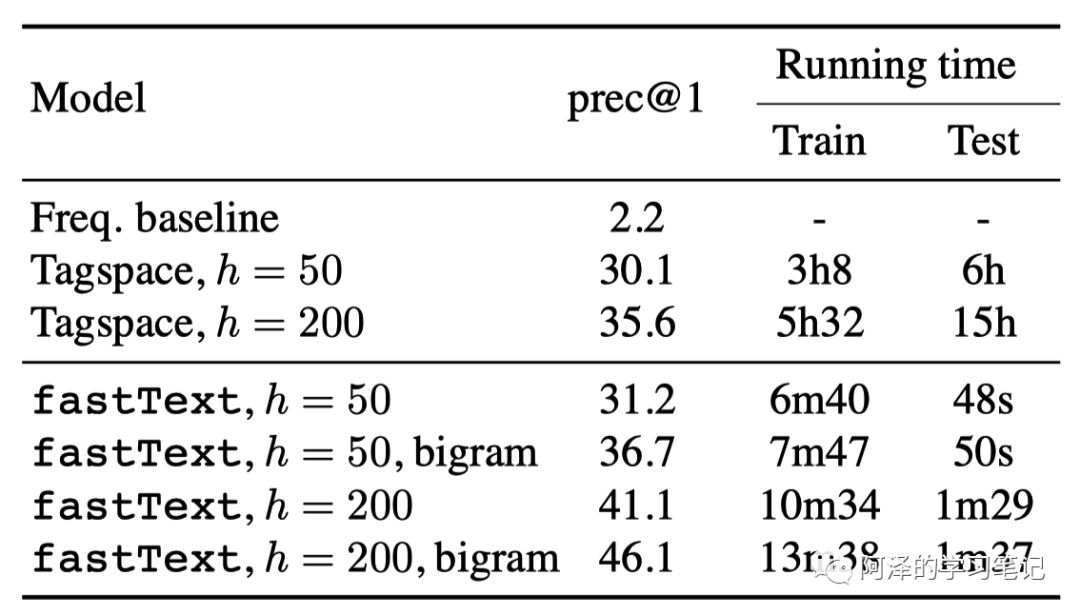
4. Conclusion
一句话总结:fastText 是一个用于文本分类和 Embedding 计算的工具库,主要通过 N-gram 和 Hierarchical softmax 保证算法的速度和精度。
关于 Hierarchical softmax 为什么会使 fastText 速度那么快?而在 Word2Vec 中没有看到类似的效果?
我觉得是因为 fastText 的标签数量相比 Word2Vec 来说要少很多,所以速度会变的非常快。其次 Hierarchical softmax 是必要的,如果不同的话速度会慢非常多。
另外,fastText 可能没有什么创新,但他却异常火爆,可能有多个原因,其中包括开源了高质量的 fastText,类似 Work2Vec,当然也会有 Mikolov 大佬和 Facebook 的背书。
总的来说,fastText 还是一个极具竞争力的一个工具包。
5. Reference
-
《Bag of Tricks for Efficient Text Classification》 -
《Enriching Word Vectors with Subword Information》





