NLP中的词向量对比:word2vec/glove/fastText/elmo/GPT/bert
作者:JayLou,NLP算法工程师
知乎专栏:高能NLP之路
本文已获授权,可点击文末"阅读原文"直达:
https://zhuanlan.zhihu.com/p/56382372
本文以QA形式对自然语言处理中的词向量进行总结:包含word2vec/glove/fastText/elmo/bert。
目录
一、文本表示和各词向量间的对比
1、文本表示哪些方法?
2、怎么从语言模型理解词向量?怎么理解分布式假设?
3、传统的词向量有什么问题?怎么解决?各种词向量的特点是什么?
4、word2vec和NNLM对比有什么区别?(word2vec vs NNLM)
5、word2vec和fastText对比有什么区别?(word2vec vs fastText)
6、glove和word2vec、 LSA对比有什么区别?(word2vec vs glove vs LSA)
7、 elmo、GPT、bert三者之间有什么区别?(elmo vs GPT vs bert)
二、深入解剖word2vec
1、word2vec的两种模型分别是什么?
2、word2vec的两种优化方法是什么?它们的目标函数怎样确定的?训练过程又是怎样的?
三、深入解剖Glove详解
1、GloVe构建过程是怎样的?
2、GloVe的训练过程是怎样的?
3、Glove损失函数是如何确定的?
四、深入解剖bert(与elmo和GPT比较)
1、为什么bert采取的是双向Transformer Encoder,而不叫decoder?
2、elmo、GPT和bert在单双向语言模型处理上的不同之处?
3、bert构建双向语言模型不是很简单吗?不也可以直接像elmo拼接Transformer decoder吗?
4、为什么要采取Marked LM,而不直接应用Transformer Encoder?
5、bert为什么并不总是用实际的[MASK]token替换被“masked”的词汇?
一、文本表示和各词向量间的对比
1、文本表示哪些方法?
下面对文本表示进行一个归纳,也就是对于一篇文本可以如何用数学语言表示呢?
基于one-hot、tf-idf、textrank等的bag-of-words;
主题模型:LSA(SVD)、pLSA、LDA;
基于词向量的固定表征:word2vec、fastText、glove
基于词向量的动态表征:elmo、GPT、bert
2、怎么从语言模型理解词向量?怎么理解分布式假设?
上面给出的4个类型也是nlp领域最为常用的文本表示了,文本是由每个单词构成的,而谈起词向量,one-hot是可认为是最为简单的词向量,但存在维度灾难和语义鸿沟等问题;通过构建共现矩阵并利用SVD求解构建词向量,则计算复杂度高;而早期词向量的研究通常来源于语言模型,比如NNLM和RNNLM,其主要目的是语言模型,而词向量只是一个副产物。
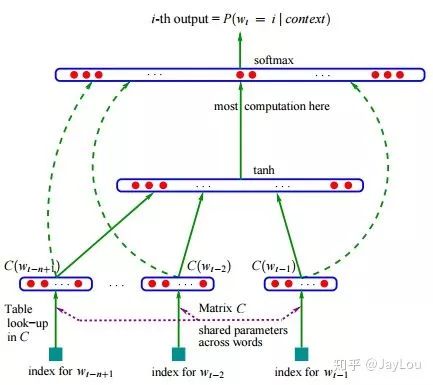
所谓分布式假设,用一句话可以表达:相同上下文语境的词有似含义。而由此引申出了word2vec、fastText,在此类词向量中,虽然其本质仍然是语言模型,但是它的目标并不是语言模型本身,而是词向量,其所作的一系列优化,都是为了更快更好的得到词向量。glove则是基于全局语料库、并结合上下文语境构建词向量,结合了LSA和word2vec的优点。

3、传统的词向量有什么问题?怎么解决?各种词向量的特点是什么?
上述方法得到的词向量是固定表征的,无法解决一词多义等问题,如“川普”。为此引入基于语言模型的动态表征方法:elmo、GPT、bert。
各种词向量的特点:
(1)One-hot 表示 :维度灾难、语义鸿沟;
(2)分布式表示 (distributed representation) :
矩阵分解(LSA):利用全局语料特征,但SVD求解计算复杂度大;
基于NNLM/RNNLM的词向量:词向量为副产物,存在效率不高等问题;
word2vec、fastText:优化效率高,但是基于局部语料;
glove:基于全局预料,结合了LSA和word2vec的优点;
elmo、GPT、bert:动态特征;
4、word2vec和NNLM对比有什么区别?(word2vec vs NNLM)
1)其本质都可以看作是语言模型;
2)词向量只不过NNLM一个产物,word2vec虽然其本质也是语言模型,但是其专注于词向量本身,因此做了许多优化来提高计算效率:
与NNLM相比,词向量直接sum,不再拼接,并舍弃隐层;
考虑到sofmax归一化需要遍历整个词汇表,采用hierarchical softmax 和negative sampling进行优化,hierarchical softmax 实质上生成一颗带权路径最小的哈夫曼树,让高频词搜索路劲变小;negative sampling更为直接,实质上对每一个样本中每一个词都进行负例采样;
5、word2vec和fastText对比有什么区别?(word2vec vs fastText)
1)都可以无监督学习词向量, fastText训练词向量时会考虑subword;
2) fastText还可以进行有监督学习进行文本分类,其主要特点:
结构与CBOW类似,但学习目标是人工标注的分类结果;
采用hierarchical softmax对输出的分类标签建立哈夫曼树,样本中标签多的类别被分配短的搜寻路径;
引入N-gram,考虑词序特征;
引入subword来处理长词,处理未登陆词问题;
6、glove和word2vec、 LSA对比有什么区别?(word2vec vs glove vs LSA)
1)glove vs LSA
LSA(Latent Semantic Analysis)可以基于co-occurance matrix构建词向量,实质上是基于全局语料采用SVD进行矩阵分解,然而SVD计算复杂度高;
glove可看作是对LSA一种优化的高效矩阵分解算法,采用Adagrad对最小平方损失进行优化;
2)word2vec vs glove
word2vec是局部语料库训练的,其特征提取是基于滑窗的;而glove的滑窗是为了构建co-occurance matrix,是基于全局语料的,可见glove需要事先统计共现概率;因此,word2vec可以进行在线学习,glove则需要统计固定语料信息。
word2vec是无监督学习,同样由于不需要人工标注;glove通常被认为是无监督学习,但实际上glove还是有label的,即共现次数
。
word2vec损失函数实质上是带权重的交叉熵,权重固定;glove的损失函数是最小平方损失函数,权重可以做映射变换。
总体来看,glove可以被看作是更换了目标函数和权重函数的全局word2vec。
 。
。
7、 elmo、GPT、bert三者之间有什么区别?(elmo vs GPT vs bert)
之前介绍词向量均是静态的词向量,无法解决一次多义等问题。下面介绍三种elmo、GPT、bert词向量,它们都是基于语言模型的动态词向量。下面从几个方面对这三者进行对比:
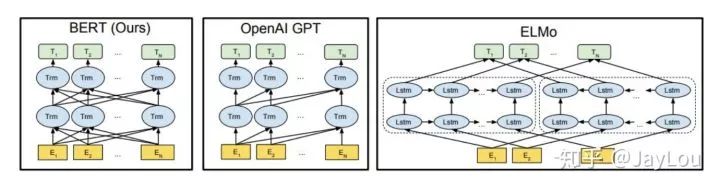
(1)特征提取器:elmo采用LSTM进行提取,GPT和bert则采用Transformer进行提取。很多任务表明Transformer特征提取能力强于LSTM,elmo采用1层静态向量+2层LSTM,多层提取能力有限,而GPT和bert中的Transformer可采用多层,并行计算能力强。
(2)单/双向语言模型:
GPT采用单向语言模型,elmo和bert采用双向语言模型。但是elmo实际上是两个单向语言模型(方向相反)的拼接,这种融合特征的能力比bert一体化融合特征方式弱。
GPT和bert都采用Transformer,Transformer是encoder-decoder结构,GPT的单向语言模型采用decoder部分,decoder的部分见到的都是不完整的句子;bert的双向语言模型则采用encoder部分,采用了完整句子。
二、深入解剖word2vec
1、word2vec的两种模型分别是什么?
word2Vec 有两种模型:CBOW 和 Skip-Gram:
CBOW 在已知
context(w)的情况下,预测w;Skip-Gram在已知
w的情况下预测context(w);
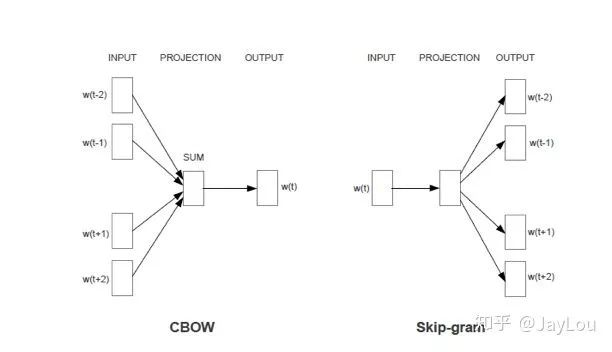
与NNLM相比,word2vec的主要目的是生成词向量而不是语言模型,在CBOW中,投射层将词向量直接相加而不是拼接起来,并舍弃了隐层,这些牺牲都是为了减少计算量,使训练更加
2、word2vec的两种优化方法是什么?它们的目标函数怎样确定的?训练过程又是怎样的?
不经过优化的CBOW和Skip-gram中 ,在每个样本中每个词的训练过程都要遍历整个词汇表,也就是都需要经过softmax归一化,计算误差向量和梯度以更新两个词向量矩阵(这两个词向量矩阵实际上就是最终的词向量,可认为初始化不一样),当语料库规模变大、词汇表增长时,训练变得不切实际。为了解决这个问题,word2vec支持两种优化方法:hierarchical softmax 和negative sampling。此部分仅做关键介绍,数学推导请仔细阅读《word2vec 中的数学原理详解》。
(1)基于hierarchical softmax 的 CBOW 和 Skip-gram
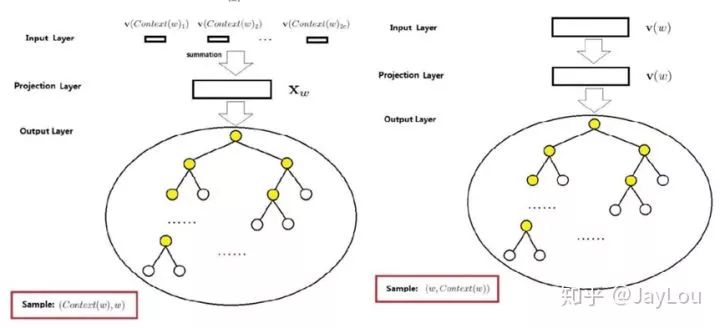
hierarchical softmax 使用一颗二叉树表示词汇表中的单词,每个单词都作为二叉树的叶子节点。对于一个大小为V的词汇表,其对应的二叉树包含V-1非叶子节点。假如每个非叶子节点向左转标记为1,向右转标记为0,那么每个单词都具有唯一的从根节点到达该叶子节点的由{0 1}组成的代号(实际上为哈夫曼编码,为哈夫曼树,是带权路径长度最短的树,哈夫曼树保证了词频高的单词的路径短,词频相对低的单词的路径长,这种编码方式很大程度减少了计算量)。
CBOW中的目标函数是使条件概率 
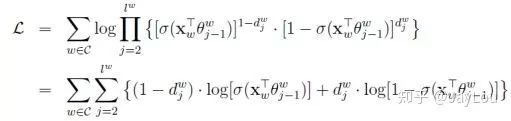
Skip-gram中的目标函数是使条件概率 
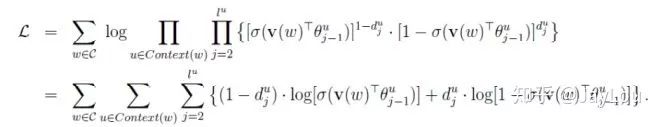
(2)基于negative sampling的 CBOW 和 Skip-gram
negative sampling是一种不同于hierarchical softmax的优化策略,相比于hierarchical softmax,negative sampling的想法更直接——为每个训练实例都提供负例。
对于CBOW,其目标函数是最大化:
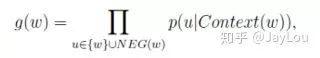
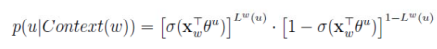
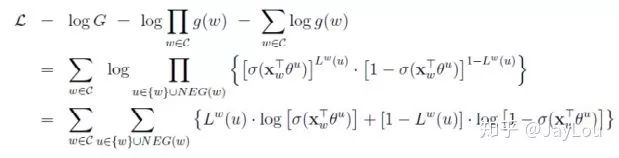
对于Skip-gram,同样也可以得到其目标函数是最大化:
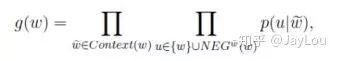
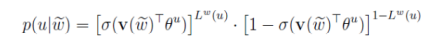
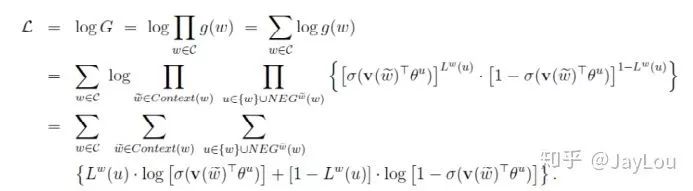
负采样算法实际上就是一个带权采样过程,负例的选择机制是和单词词频联系起来的。

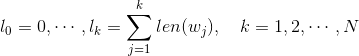
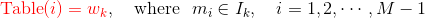
具体做法是以 N+1 个点对区间 [0,1] 做非等距切分,并引入的一个在区间 [0,1] 上的 M 等距切分,其中 M >> N。源码中取 M = 10^8。然后对两个切分做投影,得到映射关系:采样时,每次生成一个 [1, M-1] 之间的整数 i,则 Table(i) 就对应一个样本;当采样到正例时,跳过(拒绝采样)。
三、深入解剖Glove详解
GloVe的全称叫Global Vectors for Word Representation,它是一个基于 全局词频统计(count-based & overall statistics)的词表征(word representation)工具。
1、GloVe构建过程是怎样的?
(1)根据语料库构建一个共现矩阵,矩阵中的每一个元素 


(2)构建词向量(Word Vector)和共现矩阵之间的近似关系,其目标函数为: 
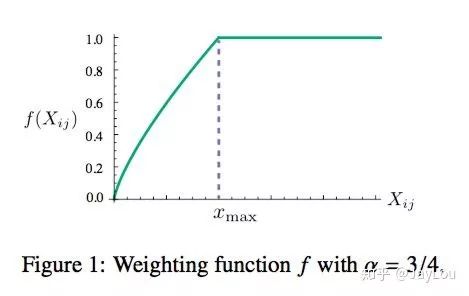
这个loss function的基本形式就是最简单的mean square loss,只不过在此基础上加了一个权重函数 

根据实验发现 




2、GloVe的训练过程是怎样的?
实质上还是监督学习:虽然glove不需要人工标注为无监督学习,但实质还是有label就是
。
向量
和
为学习参数,本质上与监督学习的训练方法一样,采用了AdaGrad的梯度下降算法,对矩阵
中的所有非零元素进行随机采样,学习曲率(learning rate)设为0.05,在vector size小于300的情况下迭代了50次,其他大小的vectors上迭代了100次,直至收敛。
最终学习得到的是两个词向量是
和
,因为
是对称的(symmetric),所以从原理上讲
和
,是也是对称的,他们唯一的区别是初始化的值不一样,而导致最终的值不一样。所以这两者其实是等价的,都可以当成最终的结果来使用。但是为了提高鲁棒性,我们最终会选择两者之和
作为最终的vector(两者的初始化不同相当于加了不同的随机噪声,所以能提高鲁棒性)。
 和
和  为学习参数,本质上与监督学习的训练方法一样,采用了AdaGrad的梯度下降算法,对矩阵
为学习参数,本质上与监督学习的训练方法一样,采用了AdaGrad的梯度下降算法,对矩阵  中的所有非零元素进行随机采样,学习曲率(learning rate)设为0.05,在vector size小于300的情况下迭代了50次,其他大小的vectors上迭代了100次,直至收敛。
中的所有非零元素进行随机采样,学习曲率(learning rate)设为0.05,在vector size小于300的情况下迭代了50次,其他大小的vectors上迭代了100次,直至收敛。 作为最终的vector(两者的初始化不同相当于加了不同的随机噪声,所以能提高鲁棒性)。
作为最终的vector(两者的初始化不同相当于加了不同的随机噪声,所以能提高鲁棒性)。3、Glove损失函数是如何确定的?(来自GloVe详解)



四、深入解剖bert(与elmo和GPT比较)
bert的全称是Bidirectional Encoder Representation from Transformers,bert的核心是双向Transformer Encoder,提出以下问题并进行解答:
1、为什么bert采取的是双向Transformer Encoder,而不叫decoder?
BERT Transformer 使用双向self-attention,而GPT Transformer 使用受限制的self-attention,其中每个token只能处理其左侧的上下文。双向 Transformer 通常被称为“Transformer encoder”,而左侧上下文被称为“Transformer decoder”,decoder是不能获要预测的信息的。
2、elmo、GPT和bert在单双向语言模型处理上的不同之处?
在上述3个模型中,只有bert共同依赖于左右上下文。那elmo不是双向吗?实际上elmo使用的是经过独立训练的从左到右和从右到左LSTM的串联拼接起来的。而GPT使用从左到右的Transformer,实际就是“Transformer decoder”。
3、bert构建双向语言模型不是很简单吗?不也可以直接像elmo拼接Transformer decoder吗?
BERT 的作者认为,这种拼接式的bi-directional 仍然不能完整地理解整个语句的语义。更好的办法是用上下文全向来预测[mask],也就是用 “能/实现/语言/表征/../的/模型”,来预测[mask]。BERT 作者把上下文全向的预测方法,称之为 deep bi-directional。
4、bert为什么要采取Marked LM,而不直接应用Transformer Encoder?
我们知道向Transformer这样深度越深,学习效果会越好。可是为什么不直接应用双向模型呢?因为随着网络深度增加会导致标签泄露。如下图:
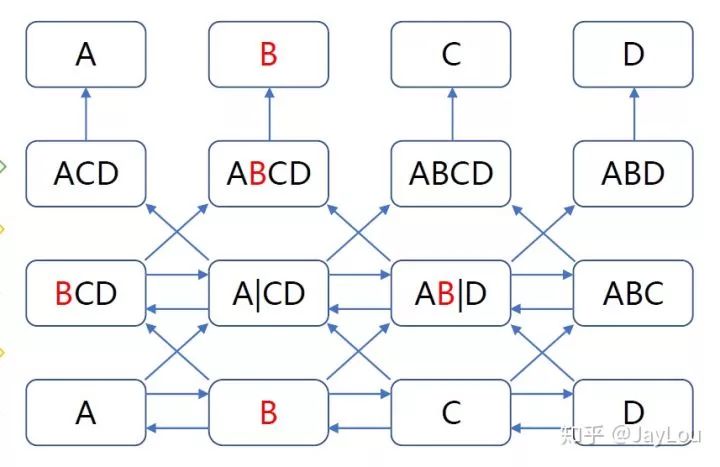
深度双向模型比left-to-right 模型或left-to-right and right-to-left模型的浅层连接更强大。遗憾的是,标准条件语言模型只能从左到右或从右到左进行训练,因为双向条件作用将允许每个单词在多层上下文中间接地“see itself”。
为了训练一个深度双向表示(deep bidirectional representation),研究团队采用了一种简单的方法,即随机屏蔽(masking)部分输入token,然后只预测那些被屏蔽的token。论文将这个过程称为“masked LM”(MLM)。
5、bert为什么并不总是用实际的[MASK]token替换被“masked”的词汇?
NLP必读 | 十分钟读懂谷歌BERT模型:虽然这确实能让团队获得双向预训练模型,但这种方法有两个缺点。首先,预训练和finetuning之间不匹配,因为在finetuning期间从未看到[MASK]token。为了解决这个问题,团队并不总是用实际的[MASK]token替换被“masked”的词汇。相反,训练数据生成器随机选择15%的token。例如在这个句子“my dog is hairy”中,它选择的token是“hairy”。然后,执行以下过程:
数据生成器将执行以下操作,而不是始终用[MASK]替换所选单词:
80%的时间:用[MASK]标记替换单词,例如,my dog is hairy → my dog is [MASK]
10%的时间:用一个随机的单词替换该单词,例如,my dog is hairy → my dog is apple
10%的时间:保持单词不变,例如,my dog is hairy → my dog is hairy. 这样做的目的是将表示偏向于实际观察到的单词。
Transformer encoder不知道它将被要求预测哪些单词或哪些单词已被随机单词替换,因此它被迫保持每个输入token的分布式上下文表示。此外,因为随机替换只发生在所有token的1.5%(即15%的10%),这似乎不会损害模型的语言理解能力。
使用MLM的第二个缺点是每个batch只预测了15%的token,这表明模型可能需要更多的预训练步骤才能收敛。团队证明MLM的收敛速度略慢于 left-to-right的模型(预测每个token),但MLM模型在实验上获得的提升远远超过增加的训练成本。
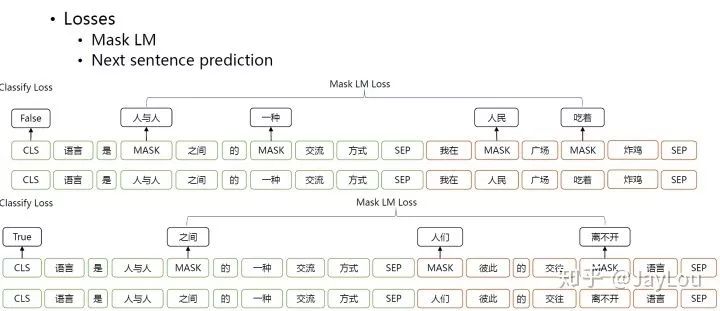
bert模型的主要创新点都在pre-train方法上,即用了Masked LM和Next Sentence Prediction两种方法分别捕捉词语和句子级别的representation。
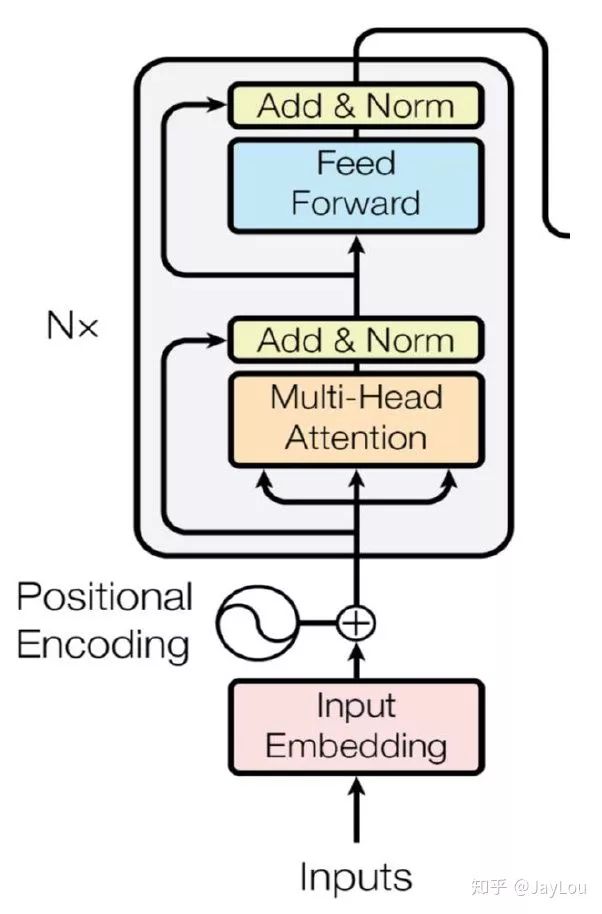
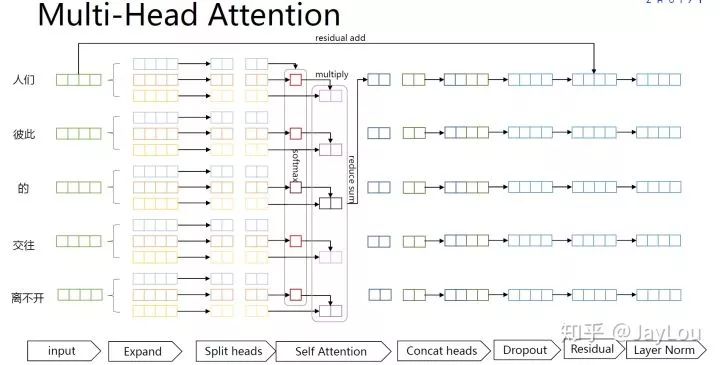
下面给出了Transformer Encoder模型的整体结构:
Reference
word2vec 中的数学原理详解
GloVe详解
从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史
NLP必读 | 十分钟读懂谷歌BERT模型
谷歌BERT解析----2小时上手最强NLP训练模型


