本文授权转载自AI科技大本营(ID:rgznai100)
![]()
啥都别说,先看图好不好
![]()
首先,恭喜DeepMind荣获大奖。
其次,获奖评语中,一定不会少的是对他家新品AlphaGo Zero的大加赞叹。
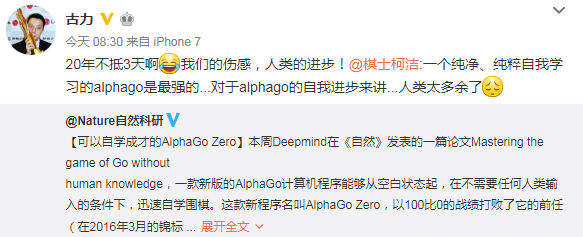
这货3天走完人类的千年棋史,这样的影响力,柯洁也坐不住了:
![]()
“AlphaGo在两年内达到的成绩令人震惊。现在,AlphaGo Zero是我们最强版本,提高了计算效率,并且没有使用到任何人类围棋数据,”AI科技大本营援引AlphaGo之父、DeepMind联合创始人兼CEO 戴密斯·哈萨比斯(Demis Hassabis)的话说到,“最终,我们想要利用它的算法突破,去帮助解决各种紧迫的现实世界问题,如蛋白质折叠或设计新材料。如果可以在这些问题上取得进展,那么它就有潜力推动人们理解生命,并以积极的方式影响我们的生活。”
好励志,好有爱,好脱俗的理想!32个赞妥妥送上!
拉回现实,这货怎么就这么牛呢?咋就能刷屏呢?
在知乎上,来自纽约大学 (New York University) · 数学&大气与海洋科学的资深博主不会功夫的潘达有一段评价,特别精彩,获得了至今为止最多的1179个点赞量,来,营长带你看一看:
旧版的AlphaGo,虽然神功小成,但斧凿痕迹显著。好似一只机器人女友,虽有绝色容颜,却长着机械手、声音冷如谷歌娘。理想的围棋人工智能,应该是简洁、优雅、浑然天成,就像死宅们的老婆新垣结衣一样。
而新版的AlphaGo,真的造出了栩栩如生的Gakki(新垣结衣)。
且不说这货3天学会blablabla,单说它的不矫情,不铺张,不依赖,不冗杂,如何能让我辈程序员不心动,不跟风,不转发,不点赞呢?人工智能当如是也。
有图有真相
这位“不会功夫的潘达”说,他读着新论文,对比前一个版本的论文(即AlphaGo Fan版本),脑补画面如下:
旧版AlphaGo:
![]()
AlphaGo Zero:
![]()
相比原机器人女友,sorry,旧版AlphaGo,这位博主为何会有如此感官呢?他在知乎中解释如下:
知乎资深博主:
具体地说,AlphaGo Zero相比于初代AlphaGo,有以下几点改进:
1. 将策略网络和价值网络合并,组成一个可以同时输出策略p和价值v的新网络
1.1 简化了新网络的结构。新策略·价值网络的输入特征平面由48个减少到了17个。其中,涉及围棋知识的输入特征(气(liberty)、征子(ladder))被删去。
2. 新策略·价值网络只需通过强化学习来训练,无需监督学习。即无需输入人类高手棋谱作为初始训练样本,只需用随机落子作为初始训练样本。
3. 优化了蒙特卡洛搜索树,主要是省去了快速走子(rollout policy),节约大量实战计算成本。
3.1 快速走子策略也需要输入大量人类已知的围棋知识,比如如何点死大眼(Nakade, 如点死直三、丁四、刀把五等棋型的唯一招法)。省去快速走子,也就省去了输入这些知识的麻烦。
4. 改卷积网络为残差网络,提高训练效率。
留下的,是一个从零开始训练的神经网络,以及用简单到不能再简单的MCTS算法行棋的AlphaGo Zero。
本着对技术的无比执着之心(偶尔营长也爱走点八卦娱乐路线),以及对人类未来无比关切之心,以及对自身的高标准要求,营长决定,必须来点技术干货,因此,特别邀请到对强化学习颇有研究的Yuxi Li 博士,让远在大洋彼岸的他牺牲点睡眠时间,为我们如饥似渴求点拨求新知的读者们作点科普性的解读。
此处应有掌声![]()
![]()
![]()
Yuxi Li 博士从加拿大发来的解读:
今天Deepmind在《自然》杂志发表论文,介绍了不用人类知识的AlphaGo Zero, 从零学起,训练出围棋顶尖高手。计算机围棋作为长久以来人工智能努力攻克的目标,搜索空间巨大,评估函数非常难于设计。
AlphaGo Zero与以前版本最大的不同是完全用强化学习的self-play技术,左右互搏,不用人类的棋谱和围棋知识,无师自通。AlphaGo Zero直接用黑白棋作为输入,而没有做任何特征工程处理。AlphaGo Zero只用一个深度神经元网络,输出策略和价值,而不是像以前的版本,分别用策略网络和价值网络。AlphaGo Zero把蒙特卡洛树搜索与强化学习结合在了一起,高效、高质量地进行采样,是一种基于模型的做法;没有采用并不很准确的快速走子网络。
AlphaGo Zero以100:0的骄人成绩战胜了与李世乭对弈的版本AlphaGo Lee. AlphaGo Zero训练3天就达到AlphaGo Lee的水平,训练21天达到AlphaGo Master的水平,训练40天则超过所有其它AlphaGo版本。AlphaGo Master是2017年初60盘横扫棋坛和2017年5月与柯洁对弈的版本。在耗能方面,第一篇《自然》杂志论文中的AlphaGo用176个GPU,对战李世乭时的版本用48个TPU,而AlphaGo Master和AlphaGo Zero用4块TPU。当然,AlphaGo训练时的计算量仍然巨大。
AlphaGo Zero从零开始训练,学到了一些类似于人类的策略,也学到了一些不同于人类的打法。人类棋手应该开始向人工智能学习围棋技术了。
AlphaGo的成功,是人工智能的成功,是AlphaGo底层技术---深度学习,强化学习,蒙特卡洛树搜索---的成功。而这些人工智能技术应用非常广泛。深度学习一般用于有监督学习,比如图像分类。深度学习在语音识别、图像识别等领域已经取得革命性的突破。深度学习也在药物发现、基因表达等众多领域有着广泛应用。强化学习一般用于序列决策问题,在游戏、机器人、自然语言处理、金融、医疗、智能交通、智慧城市、智能电网、工业4.0等领域有广泛应用。蒙特卡洛树搜索则可用于传统人工智能中的规划、调度等问题。详情参见《深度强化学习综述》https://arxiv.org/abs/1701.07274.
另一方面,我们也应该看到AlphaGo技术的局限性。深度学习和强化学习一般都需要大量数据。围棋作为一种完美信息博弈,有着明确的规则,我们可以通过这些规则产生大量数据,使用强化学习的self-play技术训练。 有些问题,比如星际争霸,虽然我们可以知道规则,但是搜索空间很可能太庞大,无法直接应用AlphaGo技术。还有很多问题,比如自动驾驶、医疗等,数据不容易获取,也不一定有明确的规则,这样就很难应用AlphaGo技术。但是,通过人工智能的进一步进展,比如在非监督学习、迁移学习、小数据学习等方面的发展,提高人工智能在知识表达、推理、逻辑等方面的能力,我们有望取得更多突破。
AlphaGo的成功是深度强化学习的开始。我们会看到深度强化学习取得更多突破,在更多领域的应用。我们也会越来越接近通用人工智能。
就在此次事件出来的第一时间,卡耐基梅隆大学机器人系博士,Facebook人工智能组研究员田渊栋就此事也在知乎发表了详细的技术点评,其在短短3个小时内,便获得了700个点赞。让我们来看一看。
Facebook人工智能组研究员田渊栋博士解读:
![]()
老实说这篇Nature要比上一篇好很多,方法非常干净标准,结果非常好,以后肯定是经典文章了。
Policy network和value network放在一起共享参数不是什么新鲜事了,基本上现在的强化学习算法都这样做了,包括我们这边拿了去年第一名的Doom Bot,还有ELF里面为了训练微缩版星际而使用的网络设计。另外我记得之前他们已经反复提到用Value network对局面进行估值会更加稳定,所以最后用完全不用人工设计的default policy rollout也在情理之中。
让我非常吃惊的是仅仅用了四百九十万的自我对局,每步仅用1600的MCTS rollout,Zero就超过了去年三月份的水平。并且这些自我对局里有很大一部分是完全瞎走的。这个数字相当有意思。想一想围棋所有合法状态的数量级是10^170(见Counting Legal Positions in Go),五百万局棋所能覆盖的状态数目也就是10^9这个数量级,这两个数之间的比例比宇宙中所有原子的总数还要多得多。仅仅用这些样本就能学得非常好,只能说明卷积神经网络(CNN)的结构非常顺应围棋的走法,说句形象的话,这就相当于看了大英百科全书的第一个字母就能猜出其所有的内容。用ML的语言来说,CNN的induction bias(模型的适用范围)极其适合围棋漂亮精致的规则,所以稍微给点样本水平就上去了。反观人类棋谱有很多不自然的地方,CNN学得反而不快了。我们经常看见跑KGS或者GoGoD的时候,最后一两个百分点费老大的劲,也许最后那点时间完全是花费在过拟合奇怪的招法上。
如果这个推理是对的话,那么就有几点推断。
一是对这个结果不能过分乐观。我们假设换一个问题(比如说protein folding),神经网络不能很好拟合它而只能采用死记硬背的方法,那泛化能力就很弱,Self-play就不会有效果。事实上这也正是以前围棋即使用Self-play都没有太大进展的原因,大家用手调特征加上线性分类器,模型不对路,就学不到太好的东西。一句话,重点不在左右互搏,重点在模型对路。
二是或许卷积神经网络(CNN)系列算法在围棋上的成功,不是因为它达到了围棋之神的水平,而是因为人类棋手也是用CNN的方式去学棋去下棋,于是在同样的道路上,或者说同样的induction bias下,计算机跑得比人类全体都快得多。假设有某种外星生物用RNN的方式学棋,换一种induction bias,那它可能找到另一种(可能更强的)下棋方式。Zero用CNN及ResNet的框架在自学习过程中和人类世界中围棋的演化有大量的相似点,在侧面上印证了这个思路。在这点上来说,说穷尽了围棋肯定是还早。
三就是更证明了在理论上理解深度学习算法的重要性。对于人类直觉能触及到的问题,机器通过采用有相同或者相似的induction bias结构的模型,可以去解决。但是人不知道它是如何做到的,所以除了反复尝试之外,人并不知道如何针对新问题的关键特性去改进它。如果能在理论上定量地理解深度学习在不同的数据分布上如何工作,那么我相信到那时我们回头看来,针对什么问题,什么数据,用什么结构的模型会是很容易的事情。我坚信数据的结构是解开深度学习神奇效果的钥匙。
另外推测一下为什么要用MCTS而不用强化学习的其它方法(我不是DM的人,所以肯定只能推测了)。MCTS其实是在线规划(online planning)的一种,从当前局面出发,以非参数方式估计局部Q函数,然后用局部Q函数估计去决定下一次rollout要怎么走。既然是规划,MCTS的限制就是得要知道环境的全部信息,及有完美的前向模型(forward model),这样才能知道走完一步后是什么状态。围棋因为规则固定,状态清晰,有完美快速的前向模型,所以MCTS是个好的选择。但要是用在Atari上的话,就得要在训练算法中内置一个Atari模拟器,或者去学习一个前向模型(forward model),相比actor-critic或者policy gradient可以用当前状态路径就地取材,要麻烦得多。但如果能放进去那一定是好的,像Atari这样的游戏,要是大家用MCTS我觉得可能不用学policy直接当场planning就会有很好的效果。很多文章都没比,因为比了就不好玩了。
另外,这篇文章看起来实现的难度和所需要的计算资源都比上一篇少很多,我相信过不了多久就会有人重复出来,到时候应该会有更多的insight。大家期待一下吧。
重大福利提醒:今晚,北京时间凌晨1点,David Silver和Julian Schrittwieser将在著名网站Reddit举办一场能够问他任何问题的AMA,对于这场问答中披露的更多细节,AI科技大本营将在第一时间带给大家。
还有那么几个小时才能等到答案,要不营长先带你们来看看一些值得关注的问题,吊吊你们的胃口也是极好的![]()
![]()
1.sml0820:相比于围棋,《星际争霸 II》的要难到什么程度?目前所困住你们的主要技术障碍是什么?阿尔法元的新方法对此有何帮助?
2.Cassandra120: 你们认为AlphaGo有希望解决史上最难的围棋问题(Igo Hatsuyôron's 120)吗?即赢得下述链接http://igohatsuyoron120.de/2015/0039.htm中所给定的中盘对弈,或是确认某一种给定走子方案的正确与否?
3.fischgurke:AlphaGo 大战柯洁时,你们所承诺的“AlphaGo tool”做到什么程度了?它最终的形态会是什么样呢?一个可以咨询AlphaGo关于围棋对弈决策的在线界面吗?
4.pjox:
既然AlphaGo已经退役了,你们有没有打算公布它的源代码呢?这将对全球围棋社区与当前的机器学习研究产生巨大的影响。关于德米斯·哈萨比斯在乌镇所宣布的围棋工具,到底到啥时候你们才能发布出来?
5.RayquazaDD:
感谢你们举办此次AMA。关于最新发布的AlphaGo Zero论文:
最新的AlphaGo Zero是否依然在训练中?它接下来的突破会是什么方向?还是另一个版本的自我对弈吗?
论文中提到,无论执黑还是执白,AlphaGo Zero都能赢AlphaGo master两子。然而,在最后的自我对局中,AlphaGo Zero却在像人类棋手一样点小目,其中的原因是什么呢?
你们在论文中提到,AlphaGo Zero以89:11赢得它同AlphaGo Master的对战,这100局棋谱能否对外公布?
多么好学的孩子们啊,快,到营长的怀抱里来。瞧瞧你们!就当营长这一亩三分地儿是AMA吧,有啥好问题,留言区走着...没准营长就能帮你解答一二
说了这么多,其实,营长还是有点细思极恐的拔凉拔凉横在心口,正如以下微博的留言,唉...
![]()
天天给你们做资讯,天天被AI鄙视,今天是被狗鄙视了!!!
附:
点评大咖背景资料
Yuxi Li 博士:加拿大阿尔伯塔大学(University of Alberta)计算机系博士、博士后。曾在中国任副教授、在美国任资深数据科学家。在强化学习、深度学习、机器学习、人工智能等领域有十余年研发经验。于2017年在arXiv上发表Deep Reinforcement Learning: An Overview《深度强化学习综述》,https://arxiv.org/abs/1701.07274,引起广泛关注。最近创办attain.ai公司。
田渊栋博士:田渊栋,卡耐基梅隆大学机器人系博士学位、上海交通大学硕士学位和学士学位,前谷歌无人车项目组成员,现任 Facebook 人工智能组研究员,主要负责 Facebook 的智能围棋项目 Dark Forest。
![]()
限时干货下载
Step 1:长按下方二维码,添加微信公众号“数据玩家「fbigdata」”
Step 2:回复【2】免费获取完整数据分析资料「包括SPSS\SAS\SQL\EXCEL\Project!」
![]()