BERT-预训练的强大


在图像研究领域,预训练技术早已经是屡见不鲜的事情;但在自然语言理解领域,预训练大部分还只停留在Embedding层面,比如Word2Vec,Glove等,更复杂些的还有Elmo等。
不同于图像领域,自然语言理解领域,预训练虽说表现出一定的优势,但优势却远远不如图像领域那么明显。直到本文介绍的方法出现前,预训练方法都表现的不愠不火;而本文中方法的出现,则直接将自然语言理解中的预训练问题直接提到普适性的高度,引爆了业界。
BERT,全称BERT: Pre-training of Deep Bidirectional Transformers for LanguageUnderstanding,通过预训练技术,刷新了十余个NLP任务的最优结果,更直接让所有NLPer认识到,预训练技术在NLP中潜在的巨大价值。
人在认知领域的许多自然而然的学习过程,对于所有的机器学习算法来说,却往往如天埑般无法逾越。人总是通过极少次数的学习,就能够精准的识别某些东西。比如一个人,见过小猫后,第一次遇到老虎,有可能误识别成猫,但当有人告诉他,这其实是老虎,因为它更大,更强壮后,那他再次识别老虎的准确率就会突然变得非常非常高。
相信不少人都听说过Few Shot Learning,Transfer Learning等,前者试图通过少量的训练样本,让模型在该类别的识别中,达到一个很高的水平;后者则试图使用知识的可迁移性,让模型在少量样本的支持下,快速在一个陌生领域达到很高的水平。
人的认知,往往基于数十年的生活积累,无论是Few Shot Learning还是Transfer Learning,都无法做到这一点,而与这一点最为相近的,便是预训练。
一般来说,预训练是指,模型通过大量的可用文本,图像等,最大化P(X),其中,X为训练样本,模型的目标是让所有样本出现的概率尽可能达到最大。该类算法中最出名的算法莫过于Hinton的Weak-Sleep算法,该算法简介掀起了深度学习在算法领域中的革命。
最后,用一句通俗易懂的词描述一下预训练的作用:强大的正则化技巧(笑)。
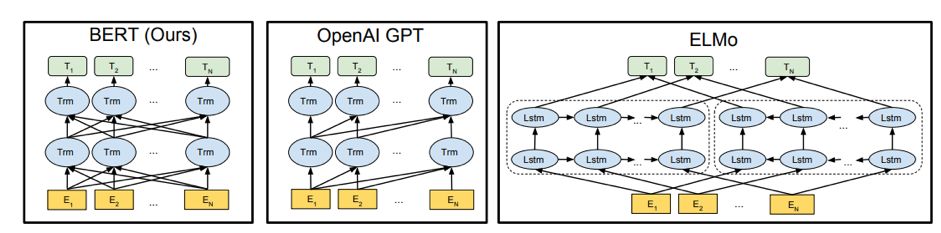
图1
图1中,分别对比了与Bert相似的两种模型,分别是OpenAI的GPT和刚刚提到的ELMo,前两种方法都预计Transformer,后一种方法则使用LSTM。不同于单向的GPT的单向,BERT更充分考虑词语与左右相关词的语义关系。
BERT的预训练过程将一段文章中,前两个句子A和B放在一起,并通过图2的方式,将其表示为向量形式。
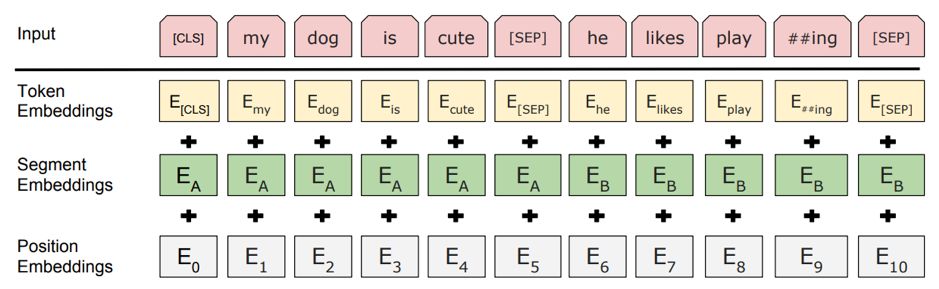
图2
图2,BERT的Embedding层,该层考虑了三种不同的Embedding,分别是图中的第二层Token Embedding,第三层Segment Embedding以及第四层Position Embedding。对于Token Embedding,BERT与其他的深度模型并没有本质区别;Segment Embedding则是BERT独有的,它区分了两个句子A和B,Position Embedding则更关注每个字词在句子中的实际位置,它最早提出与Transformer。
文本表示成向量后,BERT通过连续多层的Transformer,深层次计算了词语之间的关联性,其Transformer结构如下图所示:
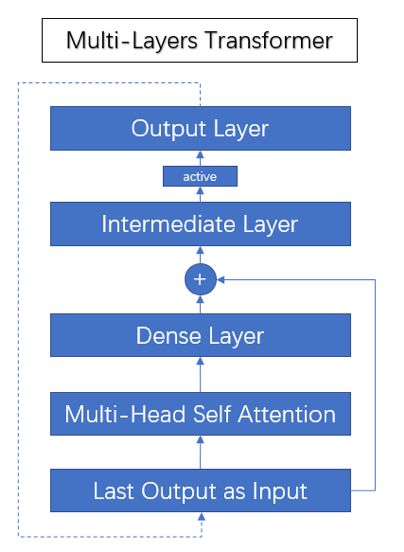
图3
图3,Transformer内部结构,将上层输出作为当前层输入,首先计算Multi Head Attention又称Self-Attention,通过全链接层后,作为Residual与输入相加,再通过一层Intermediate Layer,Intermediate Layer类似一个两头尖,中间宽的网络,目的是散化特征后,再次聚集,有点像矩阵分解对于缺失值补全,最后通过一个激活函数输出当前层结果。
插播一句,最新ICLR2019中,有文章表示,更深层的网络可以降低类内的Variance,有兴趣的同学可以去查下文章“A CLOSER LOOK AT FEW-SHOT CLASSIFICATION”。
前面介绍了网络的基本网络结构,文中省去了很多复杂的公式。下面介绍一下BERT的预训练过程。
BERT文章中,提出了两种预训练方式,即Masked Language Model和Next Sentence Prediction。
Masked Language Model:在训练过程中随机遮盖15%的词,在最终的输出层,预测这些被遮盖的词。作者在论文中提出,这15%的词中,有80%真正被覆盖,10%维持不变,10%被替换成其他词,其目的是为了让模型充分的利于双向语言模型来预测真正的被Mask掉的词。
Next Sentence Prediction:在训练过程中,作者选择了大量连续的句对,构成类别0;同时构造了大量非连续句对,构成类别1。预训练阶段,通过分类其来判断是两句话是否是连续的两句话。
需要指出的是,作者使用了图1,CLS标记最终的Embedding来预测句子关系,使用Mask位置Token(80%Mask,10%Hold,10%Replace)的Embedding来预测原Token。
作者使用了16块TPU训练了基准的BertBase,使用64块TPU训练了更大的模型BertLarge,每组预训练都持续4天。同样的计算量放到当前的M40Nvidia显卡,大概要90天,Emmm….
还有,作者在10亿级别的语料上,预训练整个模型(不服就干--- 某某某)。
论文中,作者一共提出4种不同的Fine-Tuning方法,如图4所示:
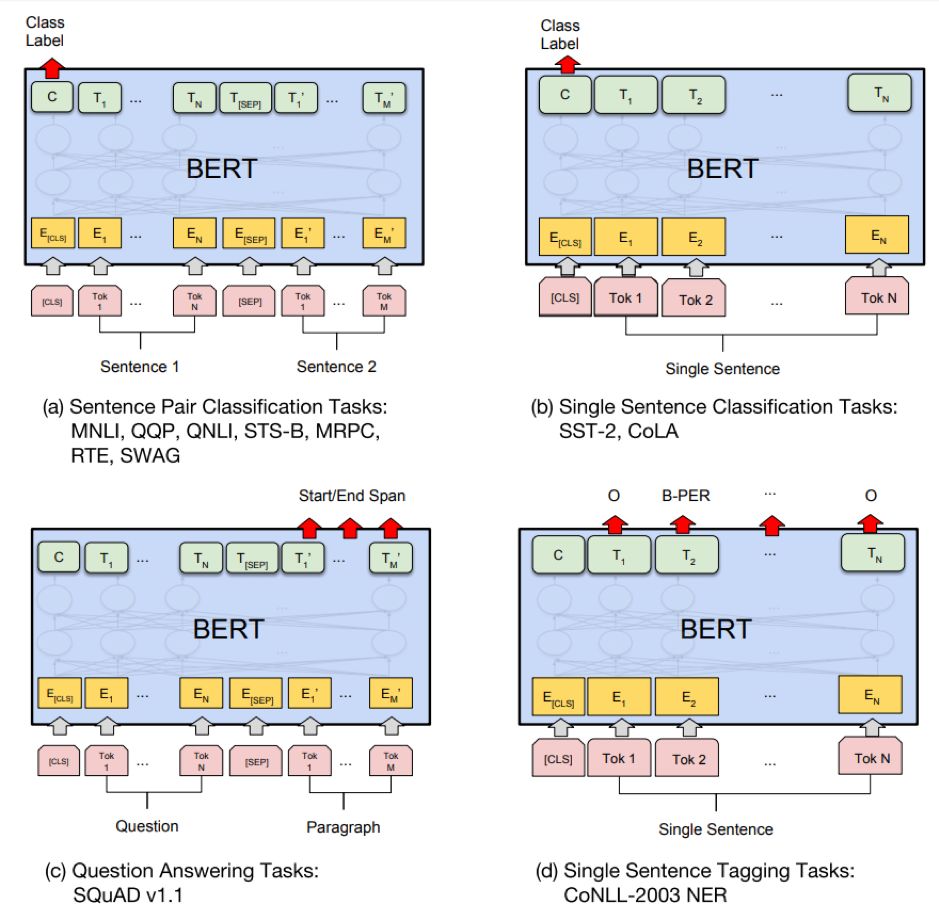
图4
四种方法中,分别对应:
(a)句子间的逻辑关系推理;
(b)单句话的分类任务;
(c)阅读理解,QA问答;
(d)实体识别。
Fine-Tuning过程中,需要注意的是,所有的分类任务都是用CLS标记对应的Embedding连接的分类器。
在实验结果方面,BERT效果极为出色:
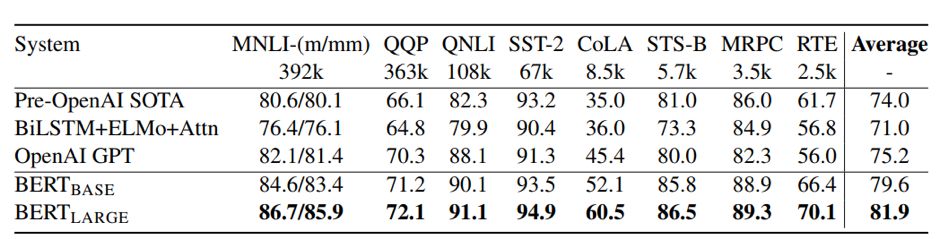
结果1,BERT在句子推理及分类任务中的表现,表格中的对比模型都是当下真正意义上的State-Of-Art的Model,相比之下,更体现出BERT的出色效果。在所有数据集中都有非常明显的提升,平均提升超过6个百分点。
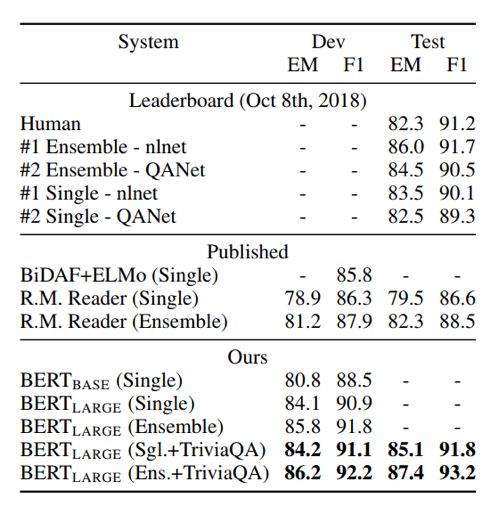
结果2
结果2,在SQuAD中Bert的效果对比,结果中,BERT同样有非常出色的效果,相比之前最好的模型,单模型便达到了nlnet的Ensemble的效果;Emsemble更是提升近2个百分点。
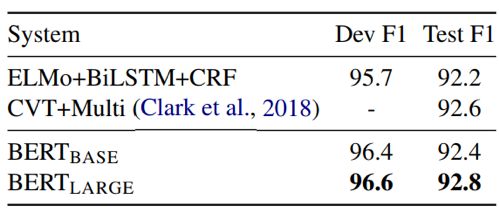
结果3
结果3,在命名实体识别任务中,Bert效果同样超过了当前的最好方法。
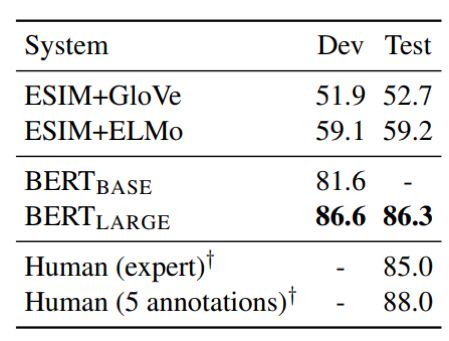
结果4
结果4,在SWAG数据集中,该数据集有点像英语四级中的阅读理解,回复的答案不再是简单的额词,而是复杂度的句子,BERT的结果在现有模型的基础上直接提升27个百分点,甚至超过了人类的表现。
BERT的强大当然不止于此,本文中也只是简单的带大家简单的过一遍文章,在实际应用中,笔者已经充分感受到了Bert的出色之处。
在困扰笔者很久的一份数据集上,多层双向LSTM效果长期局限在0.94,其他模型低于0.94的前提下,BERT直接将结果提升到0.95(这让笔者看到了未来的曙光,括弧笑)。同时在冷启动任务上,收集了几千条包含几十个类的数据后,BERT直接做FineTuning,就可以训练出一个相当可以的分类模型(尖括号赞),这里没有尝试FewShot的强(装)大(**)能(效)力(果)是个遗憾。
就目前来看,遗憾的是Bert的耗时很难满足上线需求,而且自己预训练模型,很难自己训练出理想的预训练效果(耗时长,调参难度大,自己训练往往会降低模型规模)。对笔者来说,Bert的主要作用是:1、线上给你个希望;2、线下干啥都行。
最后,强行种草:
1、 预训练是正则化方法(不知真假,姑且信了)
2、 模型宽,泛化效果好(理由同上);模型深,学习能力强(低类内Variance);
参考文献
[1] Devlin J, ChangM W, Lee K, et al. Bert: Pre-training of deep bidirectional transformers forlanguage understanding[J]. arXiv preprint arXiv:1810.04805, 2018.
[2] Vaswani A, Shazeer N, Parmar N, et al.Attention is all you need[C]//Advances in Neural Information ProcessingSystems. 2017: 5998-6008.
[3] Matthew Peters,Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, andLuke Zettlemoyer. 2018. Deep
[4] Alec Radford, Karthik Narasimhan, TimSalimans, and Ilya Sutskever. 2018. Improving language understanding withunsupervised learning. Technical report, OpenAI

微信ID:WeChatAI

登录查看更多
相关内容

专知会员服务
79+阅读 · 2019年12月29日
Arxiv
15+阅读 · 2018年10月11日




相关VIP内容
专知会员服务
79+阅读 · 2019年12月29日
相关资讯
相关论文
Arxiv
15+阅读 · 2018年10月11日