学界 | 北京大学研究者提出注意力通信模型ATOC,助力多智能体协作
选自arXiv
作者:Jiechuan Jiang、Zongqing Lu
机器之心编译
参与:Huiyuan Zhuo、路
近日,来自北京大学的研究者在 arXiv 上发布论文,提出一种新型注意力通信模型 ATOC,使智能体在大型多智能体强化学习的部分可观测分布式环境下能够进行高效的通信,帮助智能体开发出更协调复杂的策略。
从生物学角度来看,通信与合作关系密切,并可能起源于合作。例如,长尾黑颚猴可以发出不同的声音来警示群体中的其他成员有不同的捕食者 [2]。类似地,在多智能体强化学习(multi-agent reinforcement learning,MARL)中,通信对于合作尤为重要,特别是在大量智能体协同工作的场景下,诸如自动车辆规划 [1]、智能电网控制 [20] 和多机器人控制 [14]。
深度强化学习(RL)在一系列具有挑战性的问题中取得了显著成功,如游戏 [16] [22] [8] 和机器人 [12] [11] [5]。我们可以把 MARL 看作是独立的 RL,其中每个学习器都将其他智能体看成是环境的一部分。然而,随着训练进行,其他智能体的策略是会变动的,所以从任意单个智能体的角度来看,环境变得不稳定,智能体间难以合作。此外,使用独立 RL 学习到的策略很容易与其他智能体的策略产生过拟合 [9]。
本论文研究者认为解决该问题的关键在于通信,这可以增强策略间的协调。MARL 中有一些学习通信的方法,包括 DIAL [3]、CommNet [23]、BiCNet [18] 和 master-slave [7]。然而,现有方法所采用的智能体之间共享的信息或是预定义的通信架构是有问题的。当存在大量智能体时,智能体很难从全局共享的信息中区分出有助于协同决策的有价值的信息,因此通信几乎毫无帮助甚至可能危及协同学习。此外,在实际应用中,由于接收大量信息需要大量的带宽从而引起长时间的延迟和高计算复杂度,因此所有智能体之间彼此的通信是十分昂贵的。像 master-slave [7] 这样的预定义通信架构可能有所帮助,但是它们限定特定智能体之间的通信,因而限制了潜在的合作可能性。
为了解决这些困难,本论文提出了一种名为 ATOC 的注意力通信模型,使智能体在大型 MARL 的部分可观测分布式环境下学习高效的通信。受视觉注意力循环模型的启发,研究者设计了一种注意力单元,它可以接收编码局部观测结果和某个智能体的行动意图,并决定该智能体是否要与其他智能体进行通信并在可观测区域内合作。如果智能体选择合作,则称其为发起者,它会为了协调策略选择协作者来组成一个通信组。通信组进行动态变化,仅在必要时保持不变。研究者利用双向 LSTM 单元作为信道来连接通信组内的所有智能体。LSTM 单元将内部状态(即编码局部观测结果和行动意图)作为输入并返回指导智能体进行协调策略的指令。与 CommNet 和 BiCNet 分别计算内部状态的算术平均值和加权平均值不同,LSTM 单元有选择地输出用于协作决策的重要信息,这使得智能体能够在动态通信环境中学习协调策略。
研究者将 ATOC 实现为端到端训练的 actor-critic 模型的扩展。在测试阶段,所有智能体共享策略网络、注意力单元和信道,因此 ATOC 在大量智能体的情况下具备很好的扩展性。研究者在三个场景中通过实验展示了 ATOC 的成功,分别对应于局部奖励、共享全局奖励和竞争性奖励下的智能体协作。与现有的方法相比,ATOC 智能体被证明能够开发出更协调复杂的策略,并具备更好的可扩展性(即在测试阶段添加更多智能体)。据研究者所知,这是注意力通信首次成功地应用于 MARL。
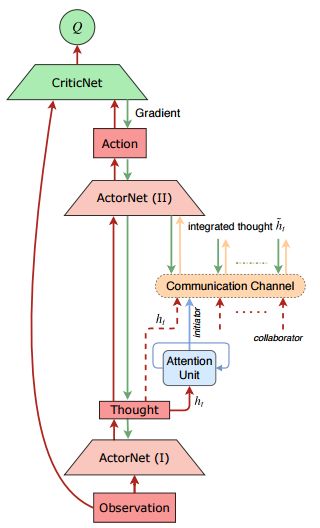
图 1:ATOC 架构。

图 2:实验场景图示:协作导航(左)、协作推球(中)、捕食者-猎物(右)。
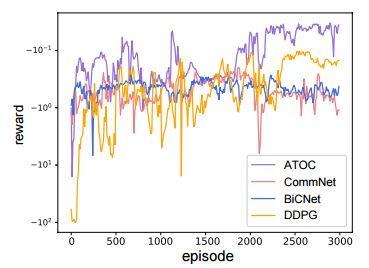
图 3:在协作导航训练期间,ATOC 奖励与基线奖励的对比。

表 1:协作导航。
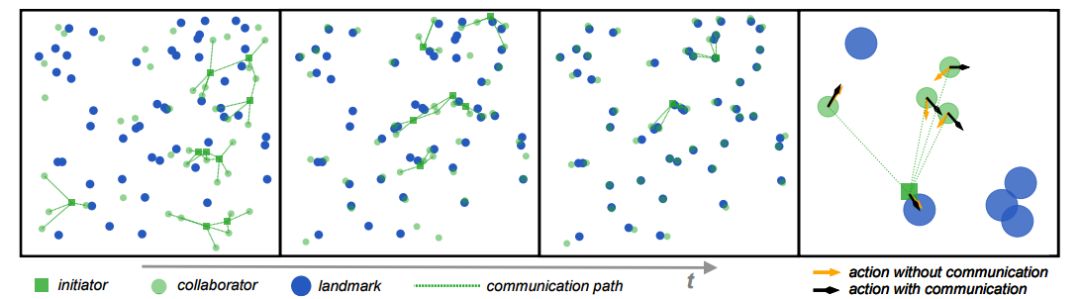
图 4:ATOC 智能体之间关于协作导航的通信可视化。最右边的图片说明在有无通信时,一组智能体采取的行动。
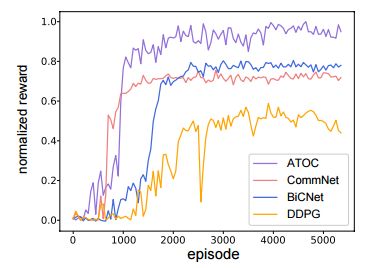
图 5:在协作推球训练期间,ATOC 奖励与基线奖励的对比。

表 2:协作推球。
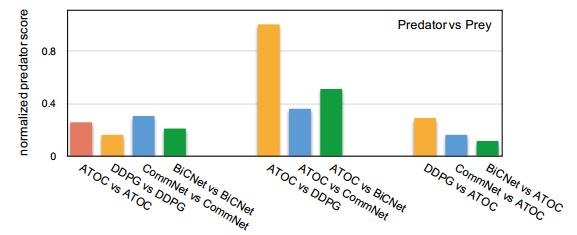
图 6:在捕食者-猎物中,ATOC 和基线的捕食者得分的交叉对比。

ATOC 算法。
论文:Learning Attentional Communication for Multi-Agent Cooperation

论文链接:https://arxiv.org/pdf/1805.07733.pdf
摘要:通信可能是多智能体协作的一个有效途径。然而,现有方法所采用的智能体之间共享的信息或是预定义的通信架构存在问题。当存在大量智能体时,智能体很难从全局共享的信息中区分出有助于协同决策的有用信息。因此通信几乎毫无帮助甚至可能危及多智能体间的协同学习。另一方面,预定义的通信架构限定特定智能体之间的通信,因而限制了潜在的合作可能性。为了解决这些困难,本论文提出了一种注意力通信模型,它学习何时需要通信以及如何整合共享信息以进行合作决策。我们的模型给大型的多智能体协作带来了有效且高效的通信。从实验上看,我们证明了该模型在不同协作场景中的有效性,使得智能体可以开发出比现有方法更协调复杂的策略。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com


