赛尔原创 | 基于循环神经网络问句关键词提取技术研究
作者:哈工大SCIR硕士毕业生王煦祥,博士生尹庆宇
1 前言
问答系统是目前自然语言处理领域中的研究热点之一,它以精准的答案直接回答用户以自然语言方式表达的问题。问答系统相较于目前广泛应用的搜索引擎,具有许多优势:搜索引擎只对用户输入的查询返回相关的列表,用户需要翻看列表进行筛选才有可能得到所需的信息,而问答系统可以直接精准地回答用户提出的问题,更加简洁;搜索引擎擅长处理用户以关键词形式呈现的查询,用户为了获取信息经常需要花费精力构造关键词,而问答系统处理的是用户以自然语言形式呈现的查询,更加贴近用户在实际生活中与人交流的方式,显得自然贴切。信息的表达方式随着信息时代的发展而日益多样,其中利用文本来表达信息的方式又是不可替代的。随着网络的发展,线上文本信息的数量程爆炸式增长,手工获取所需文本信息的难度日益增大,因此如何高效地获取信息成为一个十分重要的课题。
为了能够有效地处理海量的文本数据,研究人员在文本分类、文本聚类、自动文摘和信息检索等方向进行了大量的研究,而这些研究都涉及到一个关键而又基础的问题,即如何获取文本中的关键词。因此,在自然语言处理和信息检索等任务中,关键词提取技术已逐渐成为热点研究问题。现有的研究成果中,关键词提取技术已被广泛应用于新闻服务、查询服务等领域,并被证明能够在信息检索、自动摘要、文本分类等任务中发挥重要作用。与此同时,海量信息处理也对关键词提取技术提出了新的挑战。
关键词是对文本主题信息的精炼,高度概括了文本的主要内容,能帮助用户快速理解文本的主旨,易于使用户判断出文本是否是自己所需的内容,从而提高信息访问和信息搜索的效率。在查询问句中,关键词代表了用户问句的主体含义。在问题分析时,提取问题中的关键词对于理解问题的语义至关重要。在信息检索中,需要从用户输入的问句中提取出对检索有用的关键词,关键词的提取的效果直接影响到信息检索的结果和答案的相似度计算与排序。因此,关键词提取是问答系统的基础,如何快速准确地从问句中提取关键词对于提升问答系统的性能至关重要。
为了能够让机器自动学习关键词的特征,将特征学习融入到模型建立的过程中,避免特征工程,在我们的研究中,我们利用LSTM模型构建神经网络层次,将目标词语的上下文信息都输入到模型中,更好地利用了词语的语义信息。实验证明了深度学习的关键词提取方法的有效性。
2 实验方法
深度学习提出了一种让计算机自动学习模式特征的方法,并将特征学习融入到了建立模型的过程中,从而减少了人为设计特征造成的不完备性。而目前以深度学习为核心的某些机器学习应用,在满足特定条件的应用场景下,已经达到了超越现有算法的识别或分类性能。
基于LSTM模型的问句关键词提取方法研究利用LSTM构建神经网络层次,对问句建模,从而能够有效获取词级别语义信息。相比较传统的神经网络而言,LSTM能够克服对不定长序列输入的不足,更好地存储历史信息,进而能够得到更好的效果。LSTM将一个词序列的历史信息存储在一个实值的历史向量中,并用这个历史向量通过迭代将整个序列连结到一起。通常来说,我们认为这个包含了历史信息的向量即可表示当前的词序列。换句话说,这个向量包含了从问句开始到当前词所需要的全部语义信息。我们通过LSTM结构,将一个词语及其历史信息共同建模到一个向量中,并可以用这个向量来表示一个词序列所包含的信息。因此,我们可以利用LSTM构建一个能考虑上文信息的网络模型,将当前词和上文出现的词语共同建模到一个向量中,来预测其成为关键词的概率。
该方法主要通过LSTM构建一个分类器,对于句子中的每个词,预测其成为关键词的概率。对于一个词,我们抽取从其句首开始的所有词组成词序列,放入LSTM中进行学习。LSTM的输入是通过大规模语料预训练好的词向量序列,LSTM的输出是这个词成为关键词的概率,根据设定的阈值,我们即可根据概率来选出句子中的关键词。利用深度学习的方法一方面能够有效避免冗杂的特征工程,另一方面使用预训练的词向量可以充分利用词的语义信息来从语义层面帮助判别关键词。
在问句关键词提取任务中,要判断当前词语是否是关键词,当前词语的下文信息与上文信息同样重要。然而,由于网络是单向的,只能顺序将从句首到当前词的所有词语输入到网络中,而忽略了后文信息对判断当前词是否为关键词所产生的影响。因此,为了将目标词的上下文均输入到模型中,我们在之前的LSTM模型上进行了一些改动,使用了以目标词为中心的LSTM结构(Target-Centered LSTM,TC-LSTM)。其主要思想是将目标词的上文信息和下文信息都输入到模型,两个方向上的信息共同建模到一个向量之中,能够更好地对目标词的重要程度进行表示,从而来预测其是否是关键词的概率。我们相信,同时捕获目标词上下文信息的关键词提取方法,能够提高关键词提取的准确性。
具体来说 ,我们使用两个LSTM网络,左边的是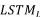
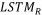
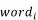
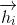
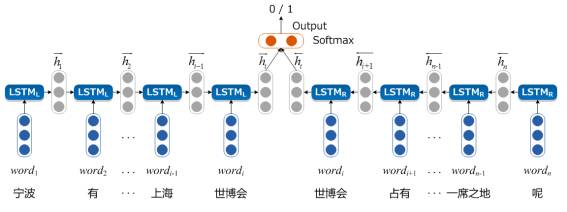
图1 以目标词为中心的LSTM模型关键词提取方法的系统结构图
例如问句“宁波有什么特产能在上海世博会占有一席之地呢”,我们要判断“世博会”是否为关键词。首先,我们将目标词 “世博会”和其上文信息,即“宁波”、“有”、“什么”、“特产”、“能”、“在”、“上海”和“世博会”这些词语的词向量从左到至右以此依次输入到
3 实验数据及评价指标
3.1 实验设置
我们的深度学习的网络结构使用深度学习框架Keras搭建。Keras是基于Theano的一个深度学习框架,用Python语言编写,是一个高度模块化的神经网络库,支持GPU和CPU。我们从百度知道抓取了1.70 GB的数据,数据集其中包含了375048个问句。经过自动生成标注数据和过滤筛选,去掉标注为关键词的数量少于1的句子,并去掉了问题分类为“游戏”、“外语”、“主板”、“显卡”、“软件”、“电脑”、“相机”、“数学”的问题,最终自动标注243882个问句。我们使用google的开源工具word2vec,利用2012版搜狗新闻数据(SogouCS)训练得到词向量。训练词向量时,使用Skip-gram模型,每个词向量的维度为100维。
3.2 实验结果与分析
在人工标注的测试集上,我们对基于深度学习的问句关键词提取方法进行了实验。在实验结果中,我们对比了传统LSTM和TC-LSTM的效果,从而验证了TC-LSTM的有效性。实验结果如下所示:
表1 基于LSTM模型的关键词提取方法实验结果
方法 |
P |
R |
F1 |
MaxEnt |
78.00% |
83.09% |
80.46% |
LSTM |
78.31% |
86.90% |
82.38% |
TC-LSTM |
79.76% |
87.57% |
83.48% |
通过实验结果对比,我们发现,相比较传统机器学习方法而言,使用LSTM方法能够获取更好的效果,F值达到83.48%,说明了深度学习方法的有效性。当我们使用了TC-LSTM时,效果相比较传统LSTM来说不论在准确率还是召回率上都有了一定的提升,表现出后文信息对于关键词提取的重要性。即加入后文信息后,同时考虑一个词的上下文能够对当前词是否为关键词做出更为准确的判断。例如,在问句“谁知道2010世界杯6月11日北京时间几点开幕?”中,我们的TC-LSTM系统正确预测出“2010”是关键词,而LSTM系统并没有得到正确的结果。这是因为,当只考虑上文信息时,很难对于“2010”是否是关键词进行预测,而当我们考虑其后文信息时,因为看到了“世界杯”,因此“2010”被预测为了关键词。
通过观察实验结果,对于深度学习方法而言,我们发现了一个非常明显的错误,即当关键词没有对应的词向量表示的时候,我们的方法很难对关键词进行正确的判断。例如问句“2009快乐女声曾轶可个人资料详细介绍?”,在这个句子中,“曾轶可”应该被标注为关键词,但是我们的方法将其预测为“非关键词”。这主要是因为,在我们预训练的词向量中,并没有“曾轶可”对应的词向量,而在使用LSTM预测的时候,我们把每个词,包括当前词放入次序列中进行预测,当一个词找不到对应词向量的时候,会用零向量代替,因此可能导致错误的预测结果。
4 总结
我们提出了一种基于LSTM模型的关键词提取方法,利用LSTM构建神经网络层次,将目标词的上文信息和下文信息都输入到模型,对问句进行建模,更好地利用了词语的语义信息。我们利用一个简单有效的方法来自动生成大规模、不精确的关键词标注数据,解决了人工标注的训练数据不足,无法满足模型的训练需求的问题。实验证明,深度学习的关键词提取方法比以往机器学习的关键词提取方法更为有效,系统性能得到了提高。
本期责任编辑: 张伟男
本期编辑: 吴 洋
“哈工大SCIR”公众号
主编:车万翔
副主编: 张伟男,丁效
责任编辑: 张伟男,丁效,赵森栋,刘一佳
编辑: 李家琦,赵得志,赵怀鹏,吴洋,刘元兴,蔡碧波
长按下图并点击 “识别图中二维码”,即可关注哈尔滨工业大学社会计算与信息检索研究中心微信公共号:”哈工大SCIR” 。





