时代聚焦AI安全——可解释性
云栖君导读: 随着人工智能的发展,越来越多的人开始关注人工智能的安全问题。今年的NIPS多集中人工智能安全上,作者列举了在会议上出现的解决人工智能安全问题的比较不错的论文。

今年的NIPS多集中在人工智能安全上,此外精彩的部分还有凯特·克劳福德关于人工智能公平性问题上被忽视的主题演讲、ML安全研讨会、以及关于“我们是否需要可解释性?”可解释ML讨论会辩论。
值校准文件
逆向奖励设计是为了解决RL代理根据人类设计的代理奖励函数推断出人类的真实奖励函数的一种设计。与反强化学习(IRL)不同,它可以让代理人从人的行为推断出奖励函数。论文中提出了一个IRD方法,假设人类选择一个可以导致训练环境中正确行为的代理奖励,代理人就奖励函数的不确定性遵循风险规避策略,模拟真实奖励的不确定性。
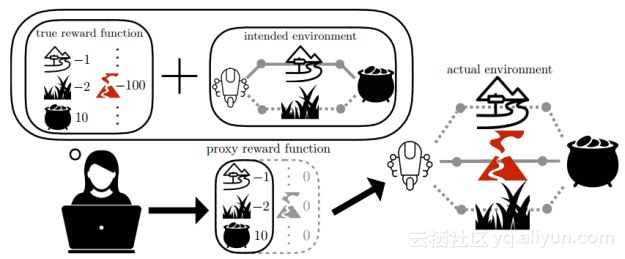
尽管目前还不清楚它们将如何推广到更复杂的环境,但是这篇论文中关于如何避免某些副作用和阻止奖励黑客行为的观点还是有些令人备受鼓舞的。这种方法也有可能过于规避一些新事物,但是在这种环境下看到一些安全探索的方法是非常棒的。
重复反向RL是指推导出包含安全标准的固有人类偏好的问题,并在许多任务中保持不变的。每个任务的奖励功能是任务不变内在奖励(代理人未观察到的)和特定任务奖励(代理人观察到的)的组合。这种多任务设置有助于解决反强化学习(IRL)中的可识别性问题,其中不同的奖励功能可以产生相同的行为。

作者提出了一种算法来推断内在奖励,同时最大限度地减少代理人犯错误的次数。他们证明了:“主动学习”案例的错误数量有上限,在错误数量的上限内,代理可以选择任务。如果超出这个错误数量的上限,则代理人无法选择任务。虽然它仍然存在很多人类难以解释的现象,但是综合来看,让代理人选择它所训练的任务似乎是个好主意。
来自人类偏好的深度RL(Christiano等人)是指利用人类反馈来教授深度RL代理人理解关于人类可以评估但可能无法证明的复杂事物(例如后空翻)。人类创造了代理行为的两个轨迹片段,并选择出哪一个更接近目标,这种方法可以非常有效地利用有限的人类反馈,使代理人学习更复杂的事物(如MuJoco和Atari所示)。

分散式多智能体RL的动态安全可中断性(EI Mhamdi等人)将安全可中断性问题推广到多智能体设置。不可中断的动态可以出现在任何一组代理人中,比如如果代理B收到代理A的中断影响并因此被激励以防止A被中断,则可能发生这种情况。多智能体定义的重点在于当存在中断的情况下保持系统动态性,而不是收集在多智能体环境中难以保证的最优策略。
Aligned AI研讨会
这场研讨会上有很多很有见解的会谈比如Ian Goodfellow的“对齐AI的对抗鲁棒性”和Gillian Handfield的“不完全契约和AI对齐”。
Ian提出的ML安全性对于长期的AI安全至关重要。敌对例子的有效性不仅受当前的ML系统(例如自驾车)的短期视角的影响,还受一些水平不高的参与人的影响。从长远角度来看,调整高级代理的价值也是一个坏消息,由于古德哈特定律,他可能会无意中寻找奖励函数的对抗性例子。因为敌对的例子会干扰代理人的判断,所以依靠代理人对环境或人类偏好的不能确保结果的准确性。

Gillian从经济学的角度来看待人工智能安全,将人造智能的目标与人类的合同的设计相对比。与造成合同不完整相同的问题(设计师无法考虑所有相关的偶然事件或者精确地制定所涉及的变量,以及激励当事方游戏系统)导致人为代理人的副作用和奖励黑客行为。

谈话的核心问题是如何利用不完全契约理论的见解来更好地理解和系统地解决AI安全中的规范问题,这是一个非常有趣的研究方向,客观规格问题似乎比不完整的合同问题更难。
人工智能系统的可解释性
作者在可解释的ML讨论会上就可解释性与长期安全性之间的关系进行了讨论,并探讨了何种形式的解释能够帮助在安全问题方面取得进展(相关幻灯片和视频)。
副作用和安全探索问题将从识别对应于不可逆状态的表示(如“破碎”或“卡住”)中受益。虽然现有的关于神经网络表示的研究着重于可视化,但与安全有关的概念往往难以形象化。
解释特定的预测或决定的本地解释性技术对安全也很有用。我们可以监测出训练环境特殊的特征或者表示与危险状态接近的特征是否会影响代理人的决定。
解释能力在很多方面对安全是有用的。作为解释性问题的基础-安全性可以为解释能力做些什么,似乎还没有人弄明白。正如研讨会的最后一场辩论中所争论的那样,在ML社区里,一直在进行着一场对话,试图制定一个模糊的解释性思想-它是什么,我们是否还需要它,什么样的理解是有用的,等等。但是我们需要记住最重要的:解释欲望在某种程度上是由我们的系统易出错所驱动的-理解我们的AI系统如果100%稳健且没有错误,那么它就不那么重要了。从安全的角度来看,我们可以将解释性的作用理解为帮助我们确保系统安全。
对于那些有兴趣将解释性锤子应用于安全钉或处理其他长期安全问题的人,FLI最近宣布了一个新的补助计划,现在是AI领域深入思考价值取向的好时机。正如Pieter Abbeel在主题演讲结束时所说的那样:“一旦你建立了非常好的AI装置,你如何确保他们的价值体系与我们的价值体系保持一致?因为在某些时候,他们可能比我们聪明,它们实际关心的关于我们所关心的东西可能很重要。”
更多精彩
-END-

云栖社区
ID:yunqiinsight
云计算丨互联网架构丨大数据丨机器学习丨运维


点此进入阅读推荐论文!



