实战 | 手把手教你用苹果CoreML实现iPhone的目标识别

在WWDC 2017上,苹果首次公布了机器学习方面的动作。iOS系统早已支持Machine Learning 和 Computer Vision ,但这次苹果提供了更合理,容易上手的API,让那些对基础理论知识一窍不通的门外汉也能玩转高大上的前沿科技。
这篇文章介绍了通过苹果最新的API把YOLO模型集成到APP中的两种方法。此前,AI100(rgznai100)介绍过YOLO这个项目,它是一个用于摄像头的实时目标检测系统,详情请参阅:《YOLO一眼就能认出你:看一个神经网络如何全视野实时检测目标》
作者 | Matthijs Hollemans
编译 | AI100(rgznai100)
参与 | thinkdeeper、胡永波
几周前,我写了篇关于YOLO(一个用于目标检测的神经网络模型)的教程。并且我使用Metal Performance Shader和我的Forge神经网络库,实现了该版本的YOLO(实际上是Tiny YOLO)。
关于YOLO的教程
http://machinethink.net/blog/object-detection-with-yolo/
Forge神经网络库
https://github.com/hollance/Forge
此后,苹果公司宣布了可以在设备上应用机器学习的两种新技术:Core ML和MPS graph API(Core ML 构建于MPS之上,MPS更底层)。在这篇博文中,我们会使用这些新的API来实现Tiny YOLO。
在设备上应用机器学习的两种新技术
http://machinethink.net/blog/ios-11-machine-learning-for-everyone


快速回顾:YOLO是由9个卷积层和6个最大池化层组成的神经网络,但其最后一层不会像分类器那样输出概率分布。相反,最后一层产生13×13×125张量。
该输出张量描述了13×13个单元格。每个单元格预测5个边界框(每个边界框由25个数字描述)。然后,我们使用非最大抑制来找到最佳边界框。
您可以在GitHub上找到此博文的源代码
https://github.com/hollance/YOLO-CoreML-MPSNNGraph
注意:运行demo需要使用Xcode 9和运行iOS 11的设备。两者都处于测试阶段。此博客文章是Beta 2的最新版本 。如果您使用的是不同的测试版,可能会得到不同的结果。
YOLO与Core ML
我们从Core ML开始,因为大多数开发人员希望用此框架将机器学习放入他们的应用程序中。接下来,打开Xcode中的TinyYOLO-CoreML项目。
第一步是创建描述YOLO神经网络的.mlmodel文件。
好消息:YOLO的作者已经提供了一个预先训练的网络,所以我们不必自己做任何训练。
YOLO的作者
链接:http://pjreddie.com/darknet/yolo/
坏消息:它是Darknet格式。该Core ML 转换工具不支持Darknet,所以我们先把Darknet转换为Keras格式。然后我们可以从Keras转换为Core ML。
Core ML 转换工具
https://pypi.python.org/pypi/coremltools
步骤1:Darknet to Keras 1.2.2
在我以前的YOLO博文中,我使用YAD2K从Darknet转换为Keras 2.0。但是,Core ML转换工具只支持Keras 1.2.2版本。所以首先我需要修改YAD2K脚本来使用旧版本的Keras(这个被改过的YAD2K被包含在YAD2K github repo中)。
您可以在README文件中找到有关如何进行此转换的完整说明。
README文件中完整的转换说明
https://github.com/hollance/YOLO-CoreML-MPSNNGraph/blob/master/README.markdown
Darknet-to-Keras转换成功之后,会生成一个tiny-yolo-voc.h5文件(在yad2k / model_data /目录中)。这是我们在以前的博客文章中使用的模型完全相同,但与Keras 1.2.2兼容。
YAD2K
链接:https://github.com/allanzelener/YAD2K
步骤2:Keras 1.2.2到 Core ML
Core ML转换工具支持YOLO格式,我们可以编写一个Python脚本,将其转换成我们需要的.mlmodel文件。
注意:如果您只想运行演示应用程序,则不需要执行这些步骤。最终的TinyYOLO.mlmodel文件已经包含在repo中。之所以提这些步骤,是说明下如何做模型转换。如果你想在你自己的应用程序中使用预先训练的模型,那就是你必须要亲自手动尝试下。
Core ML转换工具需要在/usr/bin/python目录下的Python 2.7(macOS已默认安装了),而其他版本的Python会有问题。
由于还需要安装一些软件包,因此最好制作一个“virtualenv”或虚拟环境。我会解释下一步怎么做。
首先,确保安装了Xcode 9 beta版,并设置xcode-select来使用这个beta版。从终端运行此命令

还要确保你已经pip安装。这是Python包管理器,您将使用它来安装其他软件包:

接下来,安装virtualenv包:

这些都是我们要用到的包。现在我们可以为Core ML创建一个虚拟环境。我们要把所有Python包装到这个虚拟环境 - 这样和其他版本的python相隔离,不会影响其他版本的python包。这可以让我们在同一个系统上运行不同版本的Python和Keras。
在这里,我们将虚拟环境放在home文件夹(~或/Users/yourname)中,但您可以将其放在任何你喜欢的地方(只是装完后不要随便移动,否则会导致异常)。
运行如下命令:

该-p标志告诉virtualenv使用系统版本的Python 2.7。正如我在上面指出的,这是至关重要的。如果您使用另一个Python版本(即使是2.7,必须是系统自带的版本),则coremltools包将给出错误。

这将激活刚刚创建的virtualenv。你会看到终端提示(coreml),这会告诉你你目前所处的环境。(要返回正常环境,可以键入命令deactivate)
现在我们可以安装我们需要的软件包:

这些软件包将被安装在~/coreml/lib/python2.7/site-packages/。安装完毕了。现在可以运行coreml.py转换脚本(请参阅在repo中转换文件夹)。这会读取tiny-yolo-voc.h5 Keras模型,在TinyYOLO-CoreML项目的文件夹中,生成TinyYOLO.mlmodel。
coreml.py脚本:

这是一个非常简单的脚本,但在调用coremltools.converters.keras.convert()时,设定对的参数很重要。
YOLO需要输入图像的像素为0和1,而不是0和255之间,所以我们必须以指定image_scale为1/255。不需要对输入图像进行任何其他预处理。
您不需要自己运行此转换脚本,因为repo已经包含TinyYOLO.mlmodel文件,但如果您好奇,想试试,运行如下命令即可:

该脚本输出一堆关于转换过程的信息。最后打印出模型的输出。看起来像这样:

显示YOLO需要大小为416×416像素的RGB图像。
该神经网络产生的输出是形状为125×13×13的“多数组”。这就说得通了。如你所知,YOLO的最后一层输出一个13×13个单元格,每个单元格包含125个数字,包含5个边界框的预测。
注意:转换脚本调用coremltools.converters.keras.convert()时不指定class_labels参数。当您指定class_labels时,转换器创建一个模型,输出一个字典(String, Double)与模型训练的类的概率。但是YOLO不是分类器。通过省略class_labels参数,转换工具不会以任何方式去计算最后一层的概率分布,我们直接访问最后一层的输出(feature map)。
太棒了!我们终于有一个TinyYOLO.mlmodel文件,我们可以安装到应用程序了。
步骤3:将模型添加到应用程序
将Core ML模型添加到应用程序很简单:只需将其拖放到Xcode项目中即可。然后,Xcode将生成一些代码,使其很容易使用模型。
将其拖放到Xcode项目中
http://machinethink.net/blog/ios-11-machine-learning-for-everyone/)
在我们的案例中,Xcode已经生成了TinyYOLO.swift。此文件不会显示在项目文件导航器中,但可以单击TinyYOLO.mlmodel,并从中查看此源文件。
我们大部分都是讲解TinyYOLO类:

这个类还有很多代码,我可以暂不关心。我们关心的是prediction(image)方法。此方法输入CVPixelBuffer(一个包含图像的对象)并返回一个TinyYOLOOutput对象。

这个类的相关部分是MLMultiArray对象。它包含13×13网格的边框预测。(该属性被称作grid,是因为我们在转换脚本中,使用output_names='grid'这个参数指定了该属性。)
理想情况下,我们不会TinyYOLO直接使用这个类,而是通过Vision框架。不幸的是,我无法让它工作(在beta 1和2中)。
我们希望Vision给我们一个VNCoreMLFeatureValueObservation对象,此对象有个MLMultiArray子对象(有13×13网格)。但是目前,Vision并没有为这个Core ML模型返回任何东西。我的猜测是,在当前的测试版中不支持非分类器。
所以现在我们别无选择,只能跳过Vision并直接使用Core ML。这意味着我们需要将输入图像存入CVPixelBuffer这个缓冲区对象中,并将这个缓冲区的大小调整到416×416像素,否则Core ML将不会接受它。
得到一个CVPixelBuffer并不重要,因为我们使用AVFoundation来捕获实况视频,调用AVCaptureVideoDataOutput,可以简单地执行以下操作:
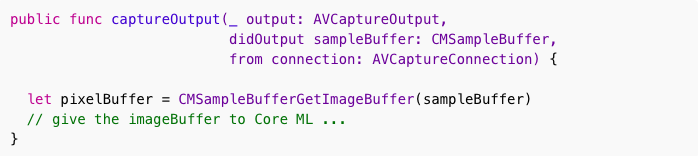
该CMSampleBufferGetImageBuffer()功能是,把CMSampleBuffer(包含相机像素数据的缓冲区)对象,转换为CVPixelBuffer。
但是,相机返回480×640图像,而不是416×416,所以我们必须调整相机输出的大小。不用担心,Core Image 有相关函数:

由于相机的图像高度大于宽度,所以会使图像稍微变形一些。这对于这个应用程序来说不算什么,但是可以使用Core Image在调整大小之前先裁剪中心正方形。
现在我们有一个CVPixelBuffer416×416的图像,我们可以预测这个图像了。
注意: 另一种调整图像大小的方法是,调用Accelerate框架中vImageScale_ARGB8888()。这段代码也在演示应用程序中,但它比使用Core Image工作量要大。
步骤4:预测
Core ML的预测很简单:
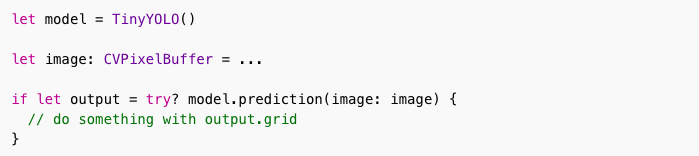
model.prediction(image)输出是MLMultiArray,描述了13×13网格的输出。
注意: MLMultiArray有点像NumPy数组,但其他功能很少。例如,没有办法转置轴或将矩阵重新形成不同的维度。
现在我们如何将MlMultiArray的边框,显示在应用程序中?
MLMultiArray对象为125×13×13。13×13网格中的每个单元格共有125个通道,因为每个单元格预测5个边界框,每个边界框由25个数字描述:
4个矩形坐标值
1个预测的概率值(例如“我是75.3%肯定这是一只狗”)
top-20 概率分布
该computeBoundingBoxes()函数将MLMultiArray转换为可以在屏幕上绘制的边框列表。用到的数学知识与前一篇博客文章的百分百一样,所以我建议您读下那个博客了解下细节。
前一篇博客文章:Real-time object detection with YOLO
http://machinethink.net/blog/object-detection-with-yolo/
不用显示整个函数,只突出显示与Metal版本不同的部分:
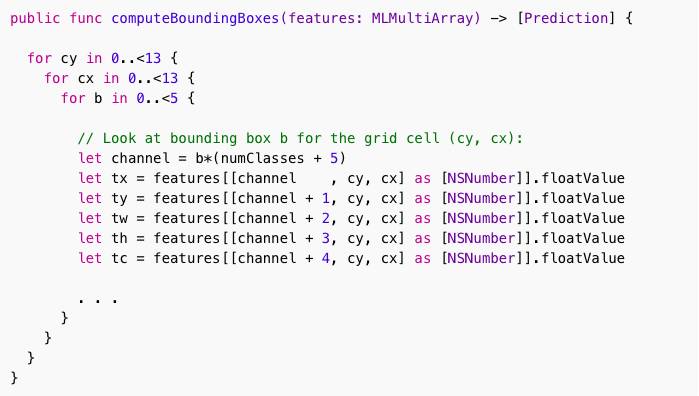
要获得一个边界框坐标tx,ty,tw,th和置信度得分tc,可以用下标索引遍历MLMultiArray。不幸的是,我们不能简单地写:
let tx = features[channel, cy, cx]
因为MLMultiArray是一个Objective-C对象,我们需要将索引包装在一个NSNumber类型的数组中。结果也是NSNumber类型,所以我们需要.floatValue用来把它改成一个Float。
我希望这可以在以后的betas中得到简化 - NSNumber调用方式并不优雅。
注意:使用正确的顺序索引多数组很重要。最初我写了features[[channel, cx, cy]],然后所有的边框都反了。浪费了一些时间才想明白...注意Core ML放入数据的顺序!
步骤5:试试吧!
嗯,让YOLO运行在Core ML确实需要点时间。但是,一旦完成了模型转换,预测就很容易了。
对于YOLO,只做预测是不够的。我们仍然需要对模型的输出进行一些额外的处理,需要操作MLMultiArray类。

YOLO与MPSNNGraph
当你想跳过Core ML,或者当Core ML不支持你的模型类型 - 或者你只是想折腾 - 可以尝试下Metal。
注意:对于小型模型,如Logistic回归,Accelerate框架是比Metal更好的选择。一个前提是你想做深度学习。
在iOS 11中,现在有两种方法可以使用Metal Performance Shader来进行机器学习:
自己创建MPSCNN并将它们编码到commandBuffer(参见我的VGGNet帖子一个例子)
使用新的图形API描述您的神经网络,并让图形接口处理所有内容
VGGNet
链接:http://machinethink.net/blog/convolutional-neural-networks-on-the-iphone-with-vggnet
在博文的第二部分,我们将看看这个新的graph API。
代码是在TinyYOLO-NNGraph项目中,接下来打开这个项目。
步骤1:转换模型
是的,它也需要做一些转换。我们再次使用由YAD2K创建的Keras 1.2.2模型。(您可以使用Keras 2.0,因为我已经为Core ML制作了一个1.2.2模型,就使用它吧。)
在之前的YOLO帖子中,我们创建了一个转换脚本,将批量归一化参数“折叠”成卷积层的权重。必须这样做,因为Metal没有批量归一化层。
之前的YOLO帖子
http://machinethink.net/blog/object-detection-with-yolo/)
虽然MPS没有batch normalization 层,但MPS 可以通过“折叠"来做batch norm。所以这样就可以更简单地进行转换。
您可以在nngraph.py中看到相关代码:

首先加载我们用YAD2K制作的tiny-yolo-voc.h5模型。
然后,它遍历所有卷积层,并将权重与批次正则化参数一起放入单个文件中,每个层一个文件。这样做不是必须的,而且还会有大量的小文件。但这使得在应用程序中更容易加载这些数据。
运行转换脚本后,我们现在有conv1.bin,conv2.bin等文件。这些文件放置在TinyYOLO-NNGraph / Parameters文件夹中,并在构建应用程序时通过Xcode复制到应用程序包中。
步骤2:将模型添加到应用程序
MPSCNN API的一个重大变化是,当创建一个新层时,不再直接传入MPSCNNConvolutionDescriptor,也不会初始化权重。
相反,你需要传入MPSCNNConvolutionDataSource对象。该对象负责加载权重。
我们开始写数据输入类。由于我们的层都非常相似,所以我们DataSource将为所有层使用相同的类 - 但是每个层都有自己的实例。代码如下所示:

该MPSCNNConvolutionDataSource需要具有load()和purge()函数。在这里,我们只需将上一步导出的二进制文件(例如,conv1.bin)加载到Data对象中即可。
要获取此层的权重,该weights()函数将返回一个指向此Data对象的第一个元素的指针。我们的层没有偏置,所以biasTerms()可以返回nil(在使用批量正则时,因为“beta”参数已经作为偏置项了)。
DataSource类有趣部分是返回MPSCNNConvolutionDescriptor对象的函数:

使用iOS 10,可以将一个MPSCNNNeuron对象赋给给descriptor的neuron属性。但现在已经被弃用了,你应该使用neuronType枚举。这里我们要使用一个“leaky”ReLU,所以我们也把值设置neuronParameterA为0.1。
setBatchNormalizationParametersForInferenceWithMean()函数也是新的。这使得处理批量正则比以前容易得多。我们还在Data对象中存储mean,variance,gamma和β,通过设置正确的UnsafePointer,然后调用该方法。
MPS将自动处理批量正则化,我们不必再担心了。太好了!
现在,数据源被整理出来,我们可以开始构建图:

我们首先为输入图像声明一个节点,并将一个将该输入图像缩放到416×416。接下来每个层都使用source参数连接到前一个层。所以scale节点连接到inputImage,conv1被连接到scale.resultImage,等等。graph本身是一个MPSNNGraph对象,并连接到网络中最后一层的输出conv9。
如果您以前使用过MPSCNN,您会注意到,搭建神经网络并不复杂。然而,一些复杂性已被带到到你的数据源对象中。如果神经网络有点复杂,那么你最终可能会需要写几个不同的数据源类型。
在我第一次使用图形API实现YOLO之后,我尝试运行应用程序,所有的边框看起来都是正确的 - 除了它们向下移动和向右移动32像素。WTH?经过一系列的调试,结果发现层pool6上的填充(padding)错误。
这个pool6层与其他池层不同,因为它使用stride 1而不是stride 2.因此它需要不同类型的填充(padding)。要更改层的填充方式,需要paddingPolicy在节点上设置属性。像这样:

默认情况下,填充设为.alignCentered而不是.alignTopLeft。这就造成了池化层的输出不完全正确,特别是在图像的右侧和底部。
图像已经缩小到13×13像素,由于filter是2×2,因此在图像的右下边缘需要一个像素的填充。
事实证明,在我以前的实现中,我已经将填充kernel的边缘设置为“clamp”而不是“zero”。使用''zero",它会在图像的边缘(duh)加零填充,但是用"clamp"会复制边缘图像进行填充。(“clamp"比较适合max-pooling,尤其当值是负数的时候)。
使用graph API,无法让max-pooling层使用“clamp"填充。为此,必须编写自己的MPSNNPadding类。
现在,YOLO可能会以零填充而不是“clamp”填充,但由于整个练习是为了更好地了解graph API,所以我们自己实现填充类。看起来像这样:
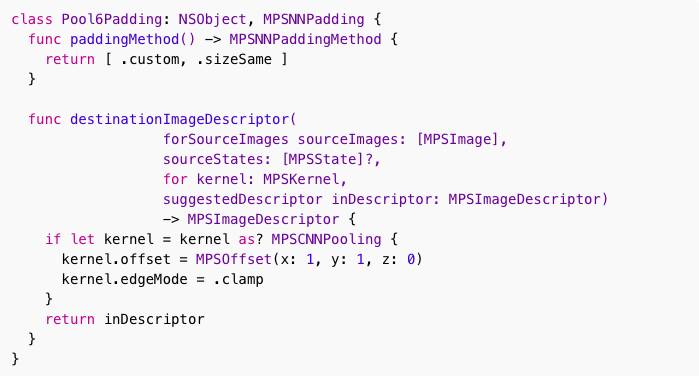
NSCoding以便您可以将图表序列化到文件,还有重要一点,在paddingMethod()我们返回.custom。这将使MPS调用destinationImageDescriptor(...)此函数。
在这个函数内部,我们可以访问底层MPSCNNPooling对象,以便我们可以设置其offset属性以获取.alignTopLeft行为,并将其设置edgeMode为.clamp。
现在,该graph computes 能得到与Forge版本完全相同的结果了。
步骤3:预测
使用Core ML,输入图像必须是一个CVPixelBuffer,但Metal需要MTLTexture。在下面代码中,我们可以轻松地将相机中的像素转换为texture:

一旦你拥有这个texture,你只需要做以下的事情进行预测:
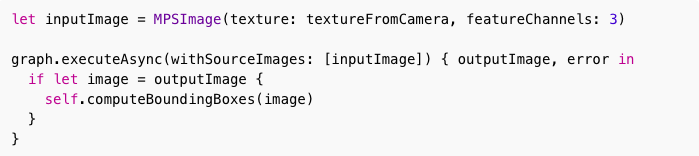
该executeAsync()函数会在后台处理所有Metal对象,并通知你何时完成。
我们调用computeBoundingBoxes()。这个方法和我以前的Metal实现的YOLO完全一样,所以我建议你阅读这篇博客文章来了解。
这篇博客文章
http://machinethink.net/blog/object-detection-with-yolo/
6月22日更新:在beta 1中没有MPSNNLanczosScaleNode,这意味着Metal不知道输入图像应该有多大。显然MPSNNGraph不需要知道这些信息,它会接受任何大小的图像。这很好,但是我们的特定神经网络输入图像必须是416×416像素 ,如果不是,我们将得不到13×13像素的网格。在beta2 中MPSNNLanczosScaleNode和MPSNNBilinearScaleNode解决了这个问题。
如果流程有很多不需要自定义的kernel,那么可以将graph编码为command buffer:

这样,您可以在graph之前或之后运行自己的compute kernels。
步骤4:试试吧!
运行应用程序,可以看到结果与Core ML版本完全相同。没有什么大惊喜,因为核心ML底层使用的Metal。

注意:运行这些类型的神经网络会消耗很大的电量。这就是为什么演示应用程序限制运行模型的频率。你可以setUpCamera()用这一行来改变它videoCapture.fps = 5。
结论
我希望这篇博文可以让您深入了解使用Core ML和Metal的图形API之间的区别。
至于速度差异,这不是重要的。这两个应用程序性能都差不多。然而,在beta 1中,Core ML版本非常慢。(我相信这会很快好起来的,因为早期的betas总是在缓慢的优化中。)
两种API之间的巨大区别在于易用性。使用Core ML,可以很容易让model上线。而MPSNNGraph复杂一些,你需要更多地了解模型的内部。但是,与“老式”MPS相比,这两者使用起来都容易得多。
Core ML最大的缺点是对模型运行时缺少灵活的控制。但说实话,甚至MPSNNGraph也并不能给你很多选择:
很难理解graph中发生了什么。可以print(graph.debugDescription)查看图中的节点,以及填充方法等等。但是,似乎没有办法检查图形自动产生的图像大小。6月22日更新:如果设置,graph.options = .verbose则图形将打印出图像的大小。这在beta 1中并不支持,但在beta 2中,可以设置MPS_LOG_INFO环境变量来解决这个问题。
您不能扩展graph API以添加自定义kernel。可以在graph之前或之后运行自定义kernel,或者将图形分为两部分,并在中间进行自己的kernel。但是,如果要在整个网络中使用自定义kernel,则graphAPI无法帮助您。
最后一点是一个主要的缺点。使用Core ML,需依赖mlmodel格式规范 - 如果模型某些部分,Core ML并不支持,则不能使用此API。MPSNNGraph也一样:如果你的模型需要做一些不包括在MPS中的东西,那么你不能使用graph API。
当你有一个简单的模型,或者想要使用一个久经考验的深度学习模型时,我认为Core ML是一个很好的解决方案。
但是,如果你想做一些深度学习的前沿模型,那么你必须使用底层api。这意味着您需要使用自定义kernel,所以MPSNNGraph也不能用。你仍然可以使用Metal,不过比较困难罢了。
点评:
Core ML 大大降低了开发者在苹果设备上使用机器学习技术的门槛。苹果制定了自己的模型格式,这样当前主流机器学习模型通过转换工具都能运用到APP当中。如果你是移动开发者,又看好机器学习,为什么不试一试呢?如果说前几年是智能机时代,有可能未来几年就是智能应用时代了。
原文地址
http://machinethink.net/blog/yolo-coreml-versus-mps-graph/
推荐阅读
研究 | YOLO一眼就能认出你:看一个神经网络如何全视野实时检测目标
招聘
AI100现招聘技术编辑、实习生,有意向请将简历投往:puge@ai100.ai
咨询请联系微信greta1314

课程结合实例介绍使用TensorFlow开发机器学习应用的详细方法和步骤,着重讲解了用于图像识别的卷积神经网络和用于自然语言处理的循环神经网络的理论知识及其TensorFlow实现方法,并结合实际场景和例子描述了深度学习技术的应用范围与效果。 所有案例均来自讲师团队工作中的亲身实践,所选案例均是深度学习的经典应用,非常具有代表性。
就差你还没关注这个号了
▼▼▼





