赛尔原创 | 基于新闻标题表示学习的超额收益预测
作者:哈工大SCIR博士生 段俊文
1 前言
由于新闻标题或摘要往往传递重要的信息,基于新闻摘要或标题的预测模型吸引了许多研究者的注意。传统预测模型往往使用词袋模型建模新闻标题。然而,这种方法无法对新闻标题事件中不同的参与者进行很好地区分。以财经新闻“耐克起诉沃尔玛专利侵权”为例,耐克和沃尔玛都是事件的参与者,但是事件对耐克和沃尔玛造成的影响却会不同。Ding 等人 [1, 2, 3] 的研究表明,相对于传统的基于词袋的模型,基于标题事件抽取的模型能有效提升股票预测的表现,并提出使用神经网络建模结构化的事件抽取结果的模型。然而,为了帮助读者理解新闻内容,新闻标题往往包含冗余的事件,使基于信息抽取的模型难以捕获关键的信息。例如,“Walgreen WAG.N , which operates the largest U.S. drugstore chain , raised its dividend on Monday.”。背景信息的加入使得包括使用序列模型在内的传统信息抽取建模其核心事件 Walgreen raised its dividend 时变得困难。
上述观察表明,我们的模型需要对更智能地、有选择地、并且能够关注长距离依赖地建模新闻标题。因为基于树结构的语义组合的方法可以潜在地捕获关键信息与其上下文之间的远距离的联系,这使得这类模型在新闻标题表示中很有前景。然而,以前对树结构进行操作的工作依赖于句法分析器或 Treebank 标注数据,它们要么在非正式文本中受到干扰,要么获得的成本较高。为了解决上述问题,我们 [4] 提出了基于强化学习的方法,该方法在树形结构上自动得到目标依赖的句子表示。通过基于 RNN 的编码器解码器结构,探索可能的二叉树结构和奖励机制,对能够提高预测结果的结构进行奖励,从而获得更好的新闻标题表示。
2 问题定义
我们将新闻标题表示问题定义为构造一颗二叉句法树并利用句法树的语义组合获得最终句子表示的问题。给定一个三元组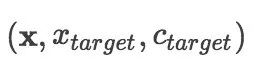
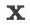
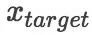
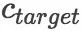
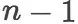
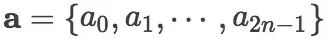
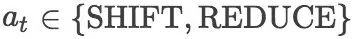
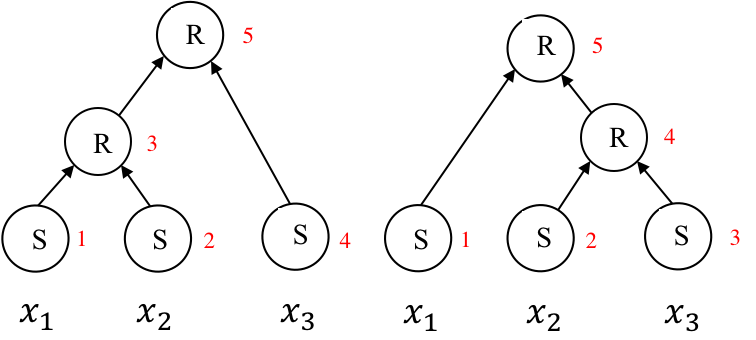
图1. 采用两种不同转移序列{S,S,R,S,R}和{S,S,S,R,R}得到两种不同的树
图1给出了两个通过使用SHIFT和REDUCE操作构造二叉树的例子。通过图1可以看出,通过改变SHIFT,REDUCE顺序,我们可以得到不同的二叉树。我们设计了1)一个转移序列生成器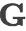
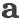
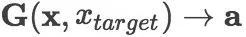

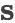
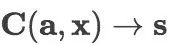
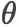
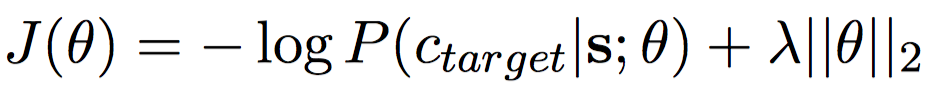
3 方法设计
我们提出的方法的结构如图 2所示, 由两个主要模块组成,即转移动作产生器

图2. 模型框架
3.1 转移动作生成器
转移动作产生器的基本思想是对不同的目标产生不同的转移序列。我们使用RNN编码器-解码器框架。标准RNN编解码器包含两个递归神经网络,一个用于将可变长度序列编码为向量表示,另一个用于将向量表示解码为另一个可变长度序列。
编码器
我们采用标准的长短期记忆网络作为我们的编码器。给定输入的句子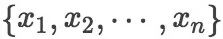
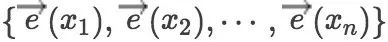
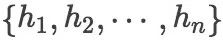
解码器
我们采用基于注意力机制的解码器。解码器将解码的每一步与编码的器的隐含状态对齐来获得上下文向量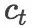

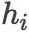
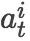


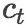
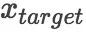
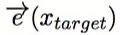
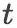
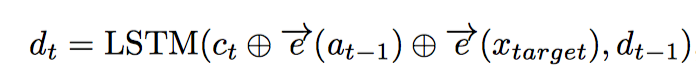
其中
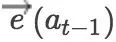
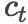
解码
在有监督的RNN解码器中,其每一步的目标是估计如下条件概率:
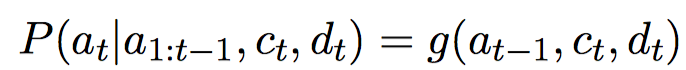
其中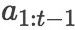
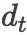
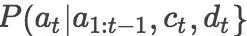
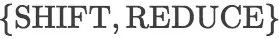

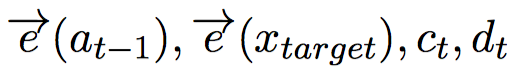
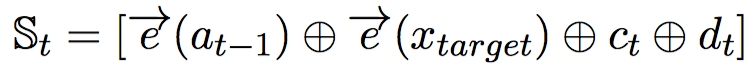
策略网络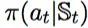

其g是一个一层的非线性前馈神经网络。我们通过从策略网络得到的分布中采样得到转移动作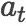
组合函数
在生成句子的有效二叉树时,我们使用组合函数来获得两个节点组合后的表示。组合函数中,我们维护了队列和栈两个数据结构,队列中存储有待处理的单词,栈中存储部分完成的子树。最初,堆栈是空的,队列中存储着句子中的所有单词。SHIFT 和 REDUCE 动作对应的操作如下。开始逐项
对于 SHIFT 动作,弹出队列中最前位置的单词并将其压入到栈的顶部。
对于 REDUCE 动作,栈的最上面两个元素被弹出并进行语义组合,组合的结果被再次压入堆栈顶端。
为了生成一个有效的二叉树,我们参考JuraMata等人[5],在队列为空时禁止SHIFT动作,而在堆栈中不超过两个元素时禁止REDUCE动作。
我们使用树结构LSTM对堆栈的前两个元素进行语义组合。树状结构的LSTM的定义如下:
其中
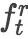
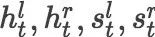
使用REINFORCE训练
模型训练的目标是优化转移动作产生器和组合函数的参数
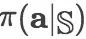
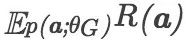
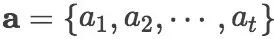
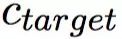
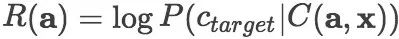
然而,直接计算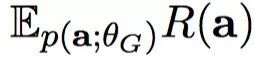
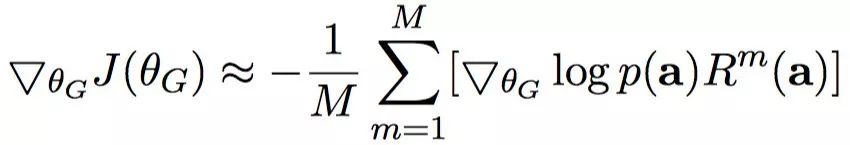
,这样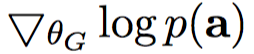
4 实验步骤
4.1 任务介绍
企业特定累积超额收益(CAR)预测任务致力于研究新信息对特定企业的影响。多个企业可能参与同一个新的事件,然而,事件可能会给这些企业带来不同的影响。从概念上讲,超额收益是股票实际收益与预期收益之间的差额,例如,如果一只股票预期上涨5%,但在事件当天,它上涨2%,虽然它给出了正回报,但是其超额回报为是-3%。预期收益可由每日指数(如S&P 500指数)来近似。
累积超额收益是事件窗口中累积的超额收益。我们使用三天的窗口(-1, 0, 1),表示为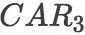
4.2 实验数据
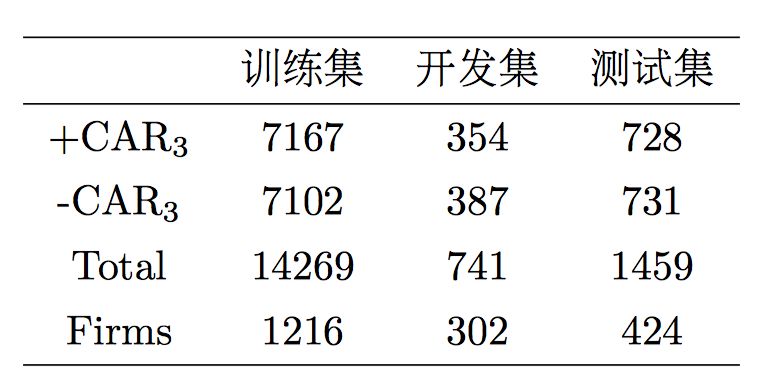
我们使用与Chang等[6]2016相同的新闻数据集。为了更好地解释我们的方法,我们使用事件周期内只含有一条新闻的公司,该子数据集覆盖了原数据集中超过70%的例子。最终的数据集总共产生16469个实例,包括1291家公司,其中10%用于验证,20%用于测试。在表1中列出了正、负
表1. 数据集的统计数据
4.3 基线方法
为了评估我们在正式新闻文本上的表现,我们与最新的目标独立和目标依赖基线进行比较。在基线中,Sentiment-based和Bi-LSTM是目标独立的,它们学习句子的通用表示,而Bi-LSTM+Att和TGT-CTX-TLSTM是目标相关的。
4.4 实验结果
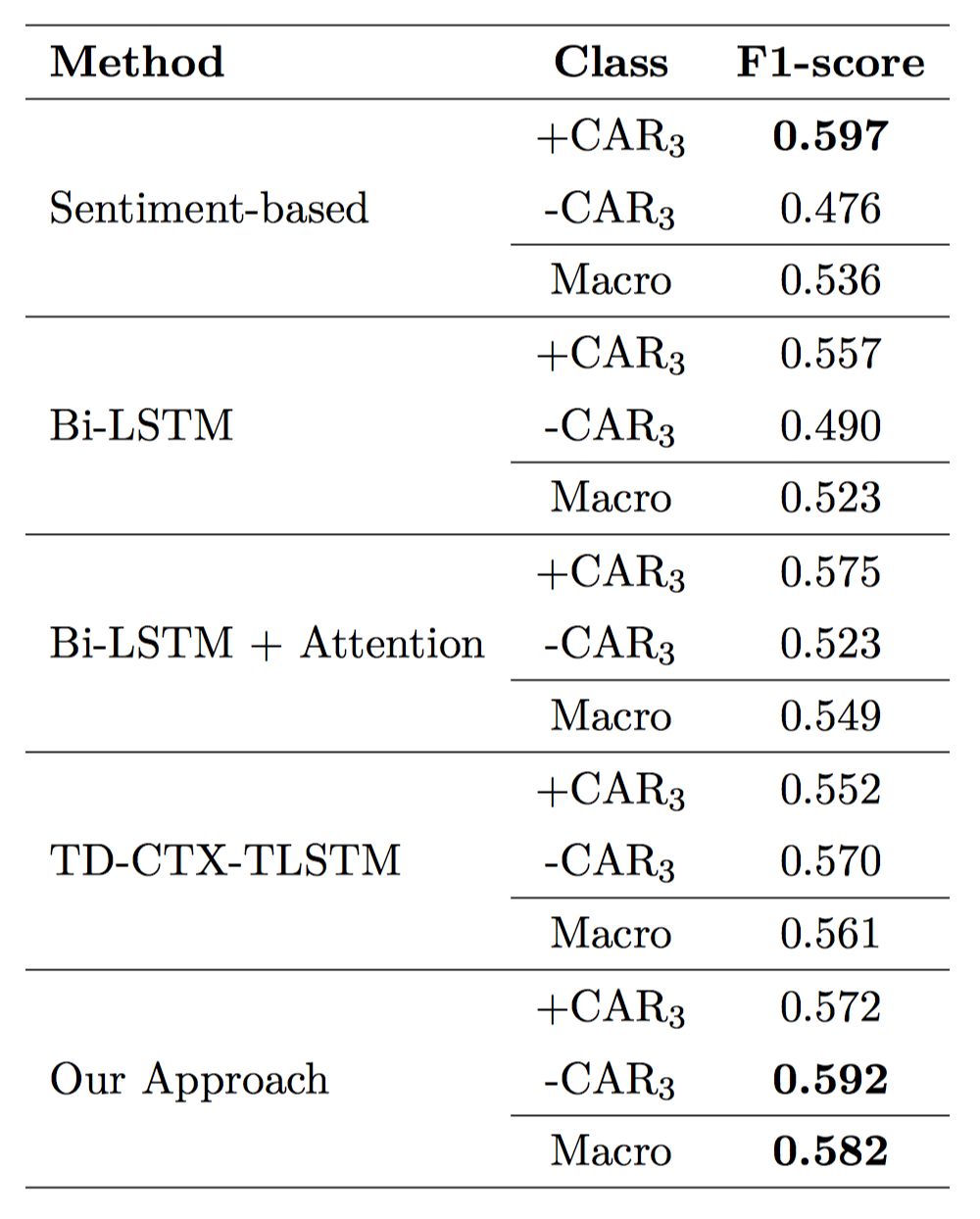
我们的方法和基线的Macro-F1分数在表2中给出。基于情感的方法在正类中给出了最高的Macro-F1得分。然而,它在负类上的表现却很差,这表明它倾向于错误地将句子归类为正类。Bi-LSTM+Attention优于传统模型,并且在正负分析中都非常稳定。我们的方法获得了58.2%的Macro-F1,在正类和负类的Macro-F1分别为57.2%和59.2%。与采用依存分析器得到树结构的模型TGT-CTX-TLSTM相比,获得了超过2%的提升。
表2. 累积超额收益预测任务上的结果
4.5 准确率与句子长度的关系
较长的句子对于句法解析器来说更具挑战性。为了深入了解我们的方法处理长句的性能,我们进一步检查了不同句子长度的准确性。如图3所示,我们与基线TGT-CTX-TLSTM进行比较。我们把句子分成七组,每组都包含长度为[5*i,5 *(i+1)]的句子。TGT-CTX-TLSTM对长度较短的句子具有较高的准确性,而对于长度大于30的句子,其准确性急剧下降。我们的方法在长句和短句上更一致。随着句子长度的增加,模型的准确率逐渐增加,显示了它在不同长度的句子中的鲁棒性和有效性。
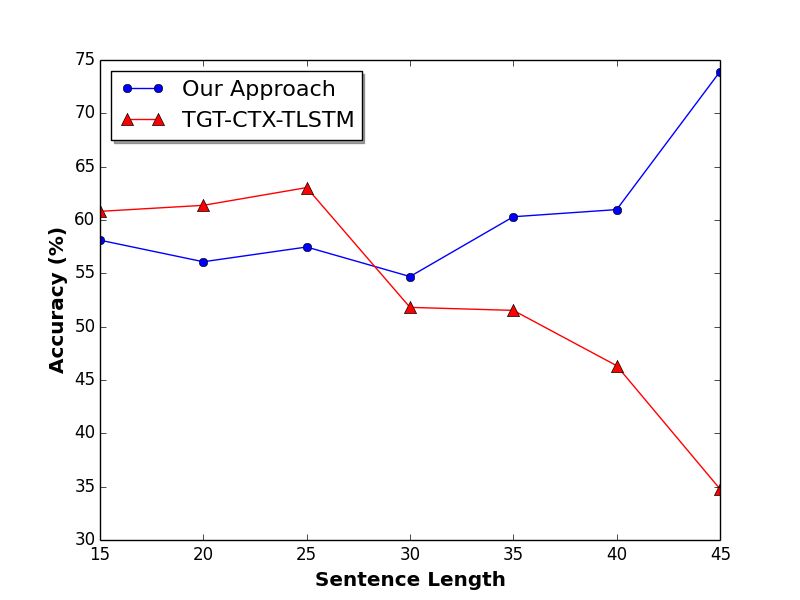
图3. 模型相对于句子长度的准确率
4.6 案例分析
为了进一步了解我们模型生成的结构,我们检查我们的方法产生的二叉树。我们在图4给出了两个例子。对于句子"Nike NKE.N has sued Wal-Mart WMT.N, saying the world's largest retailer is selling athletic shoes that infringe on its design patents'', 句子的核心部分"Nike sued Wal-mart"以及句子的其他部分被分入两棵子树,这减少关键事件在组成句子表示时潜在的信息损失。类似地,对于句子"Walgreen WAG.N , which operates the largest U.S. drugstore chain , raised its dividend on Monday.", 模型学习到将目标"Walgreen"以及核心事件"raised its dividend on Monday"在树中的距离接近,尽管他们在顺序结构中有许多词。这些是我们的模型得到的较好的例子,我们也发现很多的树形结构是严重左倾或右倾的,这类结构等价于顺序结构中的前向和后向的长短期记忆网络。

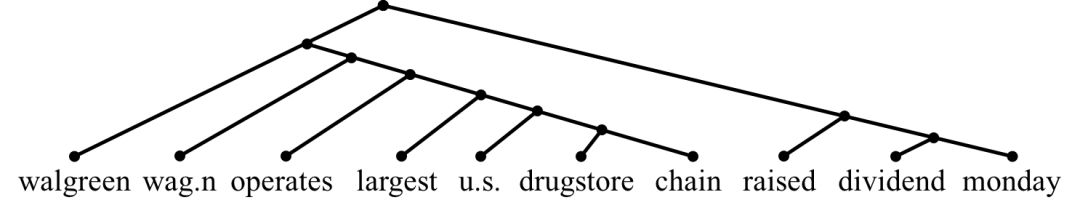
图4. 我们模型的得到的树形结构。我们去掉了停用词和标点。上面的树结构是句子 "Nike NKE.N has sued Wal-Mart WMT.N, saying the world ’s largest retailer is selling athletic shoes that infringe on its design patents" 而下面的结构为句子 "Walgreen WAG.N , which operates the largest U.S. drugstore chain , raised its dividend on Monday."
5 结论
本文中,为了建模新闻对所涉及的不同公司的影响,我们提出了一种基于强化学习句子表示方法,该方法通过生成目标依赖的树结构,并在生成的树结构上进行句子语义表示。实验结果表明,相对于基线方法,我们在任务中取得更好的表现。对实验结果的分析表明,树形结构在建模较长句子以及捕获远距离依赖时相对于顺序结构更有优势。
参考文献
[1] Xiao Ding, Yue Zhang, Ting Liu, and Junwen Duan. Using structured events to predict stock price movement: An empirical investigation. In EMNLP, 2014.
[2] Xiao Ding, Yue Zhang, Ting Liu, and Junwen Duan. Deep learning for event-driven stock prediction. In IJCAI, 2015.
[3] Xiao Ding, Yue Zhang, Ting Liu, and Junwen Duan. Knowledge-driven event embedding for stock prediction. In COLING, 2016.
[4] Junwen Duan, Xiao Ding, and Ting Liu. Learning sentence representations over tree structures for target-dependent classification. In NAACL, 2018.
[5] Dani Yogatama, Phil Blunsom, Chris Dyer, Edward Grefenstette, and Wang Ling. Learning to compose words into sentences with reinforcement learning. arXiv preprint arXiv:1611.09100, 2016.
[6] Ching-Yun Chang, Yue Zhang, Zhiyang Teng Teng, Zahn Bozanic, and Bin Ke. Measuring the information content of financial news. In COLING, 2016.
本期责任编辑:刘一佳
本期编辑:吴 洋
“哈工大SCIR”公众号
主编:车万翔
副主编: 张伟男,丁效
责任编辑: 张伟男,丁效,刘一佳,崔一鸣
编辑: 李家琦,吴洋,刘元兴,蔡碧波,孙卓,赖勇魁
长按下图并点击 “识别图中二维码”,即可关注哈尔滨工业大学社会计算与信息检索研究中心微信公共号:”哈工大SCIR” 。




