ECCV 2022 | 清华&Meta提出HorNet,用递归门控卷积进行高阶空间相互作用
机器之心编辑部
来自清华大学和 Meta AI 的研究者证明了视觉 Transformer 的关键,即输入自适应、长程和高阶空间交互,也可以通过基于卷积的框架有效实现。
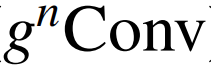 ),它用门卷积和递归设计进行高阶空间交互。新操作具有高度灵活性和可定制性,与卷积的各种变体兼容,并将自注意力中的二阶交互扩展到任意阶,而不引入显著的额外计算。
可以作为一个即插即用模块来改进各种视觉 Transformer 和基于卷积的模型。基于该操作,作者构建了一个新的通用视觉主干族,名为 HorNet。在 ImageNet 分类、COCO 对象检测和 ADE20K 语义分割方面的大量实验表明,HorNet 在总体架构和训练配置相似的情况下,优于 Swin Transformers 和 ConvNeXt。HorNet 还显示出良好的可扩展性,以获得更多的训练数据和更大的模型尺寸。除了在视觉编码器中的有效性外,作者还表明
可以应用于任务特定的解码器,并以较少的计算量持续提高密集预测性能。本文的结果表明,
可以作为一个新的视觉建模基本模块,有效地结合了视觉 Transformer 和 CNN 的优点。
),它用门卷积和递归设计进行高阶空间交互。新操作具有高度灵活性和可定制性,与卷积的各种变体兼容,并将自注意力中的二阶交互扩展到任意阶,而不引入显著的额外计算。
可以作为一个即插即用模块来改进各种视觉 Transformer 和基于卷积的模型。基于该操作,作者构建了一个新的通用视觉主干族,名为 HorNet。在 ImageNet 分类、COCO 对象检测和 ADE20K 语义分割方面的大量实验表明,HorNet 在总体架构和训练配置相似的情况下,优于 Swin Transformers 和 ConvNeXt。HorNet 还显示出良好的可扩展性,以获得更多的训练数据和更大的模型尺寸。除了在视觉编码器中的有效性外,作者还表明
可以应用于任务特定的解码器,并以较少的计算量持续提高密集预测性能。本文的结果表明,
可以作为一个新的视觉建模基本模块,有效地结合了视觉 Transformer 和 CNN 的优点。

-
论文地址:https://arxiv.org/abs/2207.14284 -
代码地址:https://github.com/raoyongming/HorNet
与各种核大小和空间混合策略兼容;3) 平移等变性。
完全继承了标准卷积的平移等变性,这为主要视觉引入了有益的归纳偏置。
,作者构建了一个新的通用视觉主干族,名为 HorNet。作者在 ImageNet 分类、COCO 对象检测和 ADE20K 语义分割上进行了大量实验,以验证本文模型的有效性。凭借相同的 7×7 卷积核 / 窗口和类似的整体架构和训练配置,HorNet 优于 Swin 和 ConvNeXt 在不同复杂度的所有任务上都有很大的优势。通过使用全局卷积核大小,可以进一步扩大差距。HorNet 还显示出良好的可扩展性,可以扩展到更多的训练数据和更大的模型尺寸,在 ImageNet 上达到 87.7% 的 top-1 精度,在 ADE20K val 上达到 54.6% 的 mIoU,在 COCO val 上通过 ImageNet-22K 预训练达到 55.8% 的边界框 AP。除了在视觉编码器中应用
外,作者还进一步测试了在任务特定解码器上设计的通用性。通过将
添加到广泛使用的特征融合模型 FPN,作者开发了 HorFPN 来建模不同层次特征的高阶空间关系。作者观察到,HorFPN 还可以以较低的计算成本持续改进各种密集预测模型。结果表明,
是一种很有前景的视觉建模方法,可以有效地结合视觉 Transofrmer 和 CNN 的优点。
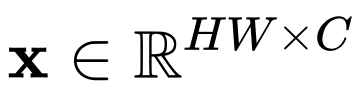 是输入特征,门卷积的输出
是输入特征,门卷积的输出
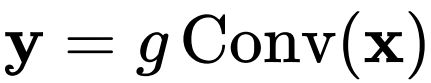 可以写成:
可以写成:
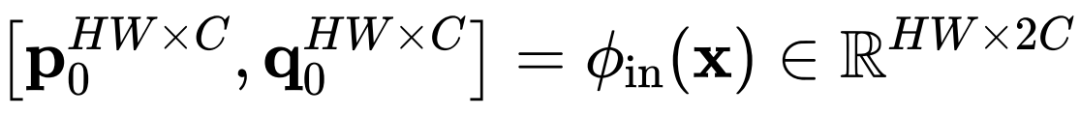
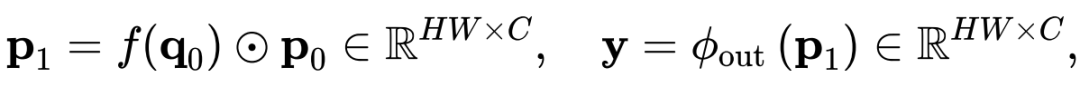
 ,
,
 是执行通道混合的线性投影层,f 是深度卷积。
是执行通道混合的线性投影层,f 是深度卷积。
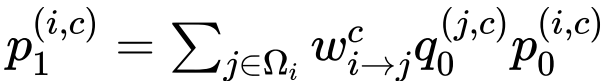 ,其中
,其中
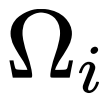 是以 i 为中心的局部窗口,w 表示 f 的卷积权重。因此,上述公式通过元素乘法明确引入了相邻特征
是以 i 为中心的局部窗口,w 表示 f 的卷积权重。因此,上述公式通过元素乘法明确引入了相邻特征
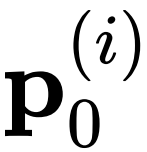 和
和
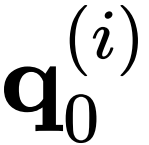 之间的相互作用。作者将 gConv 中的相互作用视为一阶相互作用,因为每个
之间的相互作用。作者将 gConv 中的相互作用视为一阶相互作用,因为每个
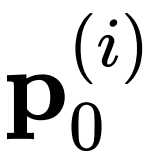 仅与其相邻特征
仅与其相邻特征
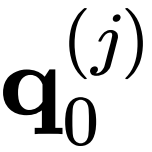 相互作用一次。
,这是一种递归门卷积,通过引入高阶相互作用来进一步增强模型容量。形式上,首先使用
相互作用一次。
,这是一种递归门卷积,通过引入高阶相互作用来进一步增强模型容量。形式上,首先使用
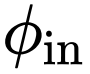 获得一组投影特征
获得一组投影特征
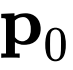 和
和
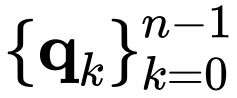 :
:


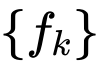 是一组深度卷积层,
是一组深度卷积层,
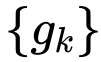 用于按不同阶匹配维数。
用于按不同阶匹配维数。
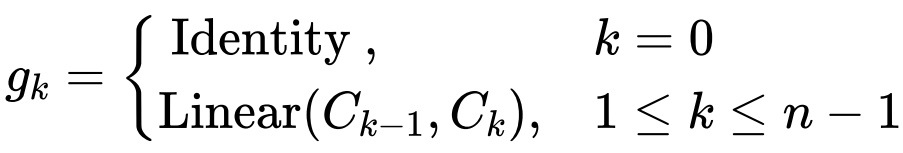
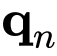 的输出馈送到投影层
的输出馈送到投影层
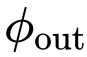 ,以获得
的结果。从递归公式方程可以很容易地看出,
,以获得
的结果。从递归公式方程可以很容易地看出,
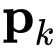 的交互阶在每一步后将增加 1。因此,可以看到,
实现了 n 阶空间相互作用。还值得注意的是,只需要一个 f 来执行深度卷积,以串联特征
的交互阶在每一步后将增加 1。因此,可以看到,
实现了 n 阶空间相互作用。还值得注意的是,只需要一个 f 来执行深度卷积,以串联特征
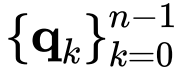 ,而不是像上面等式中那样计算每个递归步骤中的卷积,这可以进一步简化实现并提高 GPU 的效率。为了确保高阶交互不会引入太多计算开销,作者将每个阶中的通道维度设置为:
,而不是像上面等式中那样计算每个递归步骤中的卷积,这可以进一步简化实现并提高 GPU 的效率。为了确保高阶交互不会引入太多计算开销,作者将每个阶中的通道维度设置为:

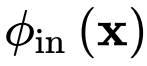 的通道维数正好为 2C,即使 n 增加,总的浮点也可以严格有界。
的通道维数正好为 2C,即使 n 增加,总的浮点也可以严格有界。
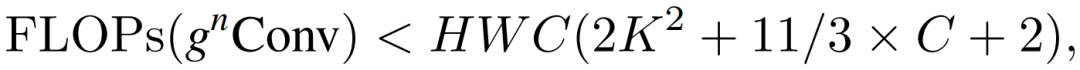 以与卷积层类似的计算成本实现高阶交互。
以与卷积层类似的计算成本实现高阶交互。
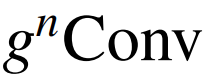 能够捕捉长期交互,作者采用了两种深度卷积 f 实现:
能够捕捉长期交互,作者采用了两种深度卷积 f 实现:
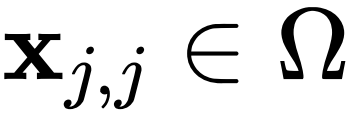 之间的相互作用感兴趣。视觉 Transformer 和以前架构之间的关键区别,即视觉 Transformer 在每个基本块中具有高阶空间交互。这一结果启发作者探索一种能够以两个以上阶数实现更高效和有效空间交互的架构。如上所述,作者提出的
可以实现复杂度有界的任意阶交互。还值得注意的是,与深度模型(如宽度和深度)中的其他比例因子类似,在不考虑整体模型容量的情况下简单地增加空间交互的顺序将不会导致良好的权衡。在本文中,作者致力于在分析精心设计的模型的空间交互阶数的基础上,开发一种更强大的视觉建模架构。对高阶空间相互作用进行更深入和正式的讨论可能是未来的一个重要方向。
之间的相互作用感兴趣。视觉 Transformer 和以前架构之间的关键区别,即视觉 Transformer 在每个基本块中具有高阶空间交互。这一结果启发作者探索一种能够以两个以上阶数实现更高效和有效空间交互的架构。如上所述,作者提出的
可以实现复杂度有界的任意阶交互。还值得注意的是,与深度模型(如宽度和深度)中的其他比例因子类似,在不考虑整体模型容量的情况下简单地增加空间交互的顺序将不会导致良好的权衡。在本文中,作者致力于在分析精心设计的模型的空间交互阶数的基础上,开发一种更强大的视觉建模架构。对高阶空间相互作用进行更深入和正式的讨论可能是未来的一个重要方向。
的计算与点积自注意有很大差异,但作者将证明
也实现了输入自适应空间混合的目标。假设 M 是通过多头自注意力(MHSA)获得的注意力矩阵,将 M 写为(
 ),因为混合权重可能在通道中变化。
位置 i 处第 c 个通道的空间混合结果(在最终通道混合投影之前)为:
),因为混合权重可能在通道中变化。
位置 i 处第 c 个通道的空间混合结果(在最终通道混合投影之前)为:
 的输出(在
的输出(在
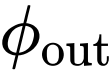 之前)可以写成:
的细节实现:
之前)可以写成:
的细节实现:
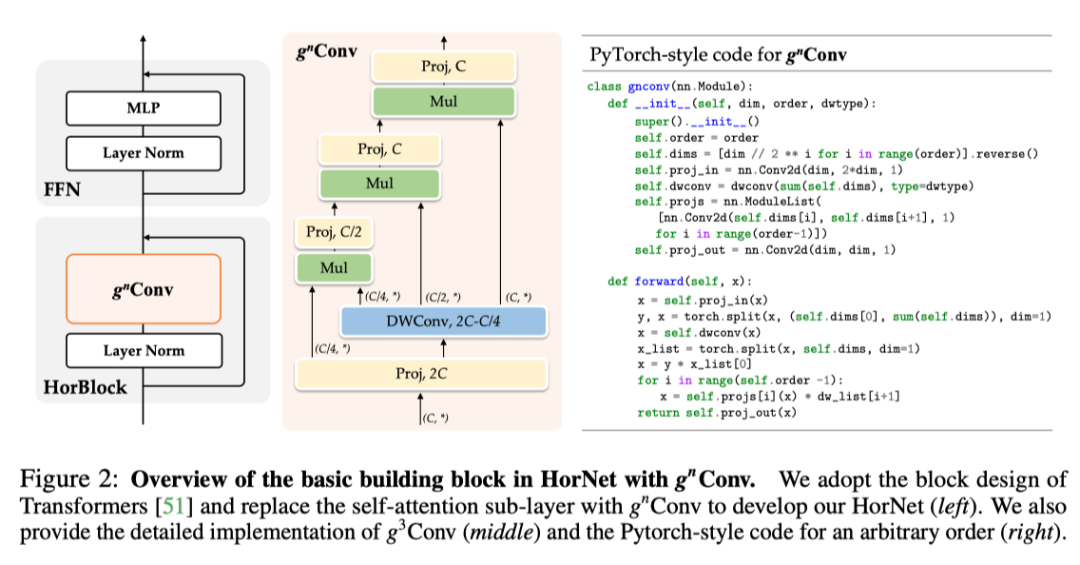 可以替代视觉 Transformer 或现代 CNN 中的空间混合层。作者遵循与以前的元架构来构建 HorNet,其中基本块包含空间混合层和前馈网络(FFN)。根据模型大小和深度卷积 f_k 的实现,有两个模型变体系列,分别命名为 HorNet-T/S/B/L 7×7 和 HorNet-T/S/B/L GF。作者将流行的 Swin Transformer 和 ConvNeXt 视为视觉 Transformer 和 CNN 基线,因为本文的模型是基于卷积框架实现的,同时具有像视觉 Transformer 一样的高阶交互。为了与基线进行公平比较,作者直接遵循 Swin Transformers-S/B/L 的块数,但在第 2 阶段插入一个额外的块,以使整体复杂度接近,从而在所有模型变体的每个阶段中产生 [2、3、18、2] 个块。只需调整通道 C 的基本数量,以构建不同大小的模型,并按照惯例将 4 个阶段的通道数量设置为[C、2C、4C、8C]。对于 HorNet-T/S/B/L,分别使用 C=64、96、128、192。默认情况下,将每个阶段的交互顺序(即中的 n)设置为 2,3,4,5,这样最粗阶C_0的通道在不同阶段中是相同的。
之外,作者发现本文的可以是标准卷积的增强替代方案,该方案考虑了基于卷积的各种模型中的高阶空间相互作用。因此,替换 FPN 中用于特征融合的空间卷积,以改善下游任务的空间交互。具体来说,作者在融合不同金字塔级别的特征后添加了。对于目标检测,作者在每个级别用 替换自顶向下路径后的 3×3 卷积。对于语义分割,作者简单地将多阶特征映射串联后的 3×3 卷积替换为,因为最终结果直接从该串联特征预测。作者同样提供了两个实现,称为 HorFPN 7×7 和 HorFPN GF,由f_k的选择决定。
可以替代视觉 Transformer 或现代 CNN 中的空间混合层。作者遵循与以前的元架构来构建 HorNet,其中基本块包含空间混合层和前馈网络(FFN)。根据模型大小和深度卷积 f_k 的实现,有两个模型变体系列,分别命名为 HorNet-T/S/B/L 7×7 和 HorNet-T/S/B/L GF。作者将流行的 Swin Transformer 和 ConvNeXt 视为视觉 Transformer 和 CNN 基线,因为本文的模型是基于卷积框架实现的,同时具有像视觉 Transformer 一样的高阶交互。为了与基线进行公平比较,作者直接遵循 Swin Transformers-S/B/L 的块数,但在第 2 阶段插入一个额外的块,以使整体复杂度接近,从而在所有模型变体的每个阶段中产生 [2、3、18、2] 个块。只需调整通道 C 的基本数量,以构建不同大小的模型,并按照惯例将 4 个阶段的通道数量设置为[C、2C、4C、8C]。对于 HorNet-T/S/B/L,分别使用 C=64、96、128、192。默认情况下,将每个阶段的交互顺序(即中的 n)设置为 2,3,4,5,这样最粗阶C_0的通道在不同阶段中是相同的。
之外,作者发现本文的可以是标准卷积的增强替代方案,该方案考虑了基于卷积的各种模型中的高阶空间相互作用。因此,替换 FPN 中用于特征融合的空间卷积,以改善下游任务的空间交互。具体来说,作者在融合不同金字塔级别的特征后添加了。对于目标检测,作者在每个级别用 替换自顶向下路径后的 3×3 卷积。对于语义分割,作者简单地将多阶特征映射串联后的 3×3 卷积替换为,因为最终结果直接从该串联特征预测。作者同样提供了两个实现,称为 HorFPN 7×7 和 HorFPN GF,由f_k的选择决定。
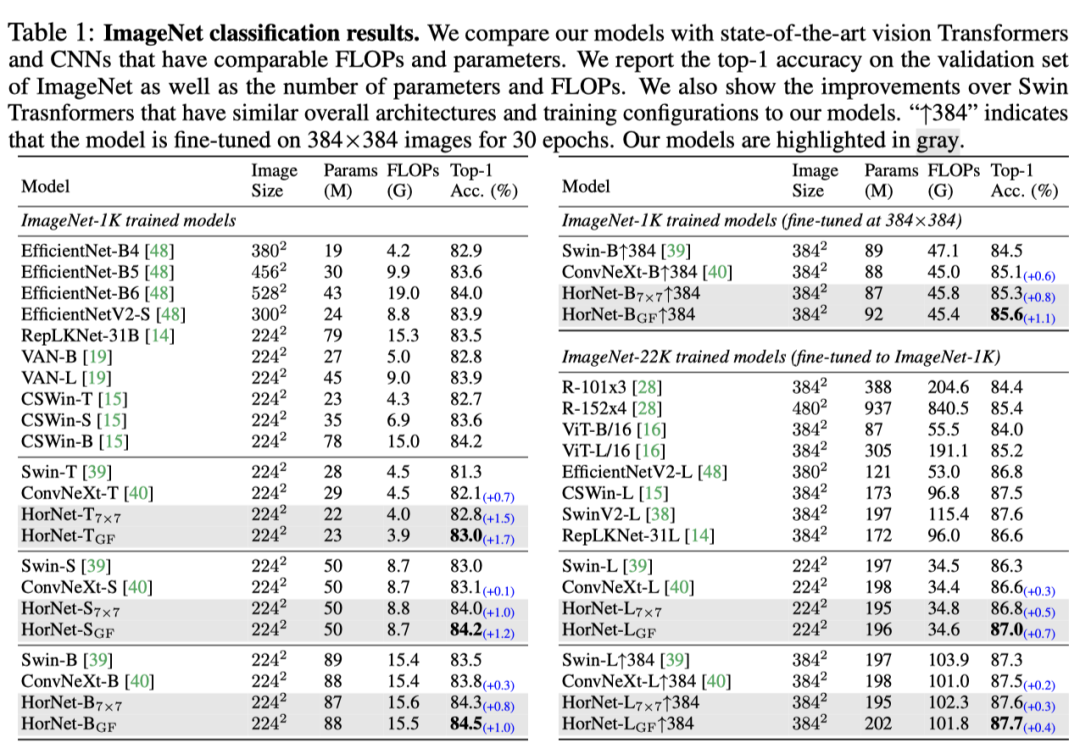

 的另一个应用,即作为更好的融合模块,可以更好地捕获密集预测任务中不同级别特征之间的高阶交互。具体而言,作者直接修改了分别用于语义分割和对象检测的 FPN,如 SuperNet 和 Mask R-CNN。在上表中显示了结果,其中作者比较了本文的 HorFPN 和标准 FPN 在不同主干上的性能,包括 ResNet-50/101、Swin-S 和 HorNet-S 7×7。对于语义分割,作者发现 HorFPN 可以显著减少 FLOPs(∼50%),同时实现更好的 mIoU。
的另一个应用,即作为更好的融合模块,可以更好地捕获密集预测任务中不同级别特征之间的高阶交互。具体而言,作者直接修改了分别用于语义分割和对象检测的 FPN,如 SuperNet 和 Mask R-CNN。在上表中显示了结果,其中作者比较了本文的 HorFPN 和标准 FPN 在不同主干上的性能,包括 ResNet-50/101、Swin-S 和 HorNet-S 7×7。对于语义分割,作者发现 HorFPN 可以显著减少 FLOPs(∼50%),同时实现更好的 mIoU。

 ),它与门卷积和递归设计进行有效、可扩展和平移等变的高阶空间交互。在各种视觉 Transformer 和基于卷积的模型中,可以作为空间混合层的替代品。在此基础上,作者构建了一个新的通用视觉骨干 HorNet 家族。大量实验证明了和 HorNet 在常用视觉识别基准上的有效性。
),它与门卷积和递归设计进行有效、可扩展和平移等变的高阶空间交互。在各种视觉 Transformer 和基于卷积的模型中,可以作为空间混合层的替代品。在此基础上,作者构建了一个新的通用视觉骨干 HorNet 家族。大量实验证明了和 HorNet 在常用视觉识别基准上的有效性。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
登录查看更多
相关内容
专知会员服务
14+阅读 · 2022年3月19日
专知会员服务
36+阅读 · 2020年1月12日
专知会员服务
16+阅读 · 2019年11月17日
Arxiv
0+阅读 · 2022年11月22日

相关VIP内容
专知会员服务
14+阅读 · 2022年3月19日
专知会员服务
36+阅读 · 2020年1月12日
专知会员服务
16+阅读 · 2019年11月17日
相关资讯
相关论文
Arxiv
0+阅读 · 2022年11月22日