微信AI拿下NLP竞赛全球冠军,“二孩”智言团队的实习生立功了
乾明 发自 凹非寺
量子位 报道 | 公众号 QbitAI
又是中国团队夺冠全球AI竞赛。
这次来自腾讯,源自微信AI,拿下NLP领域全球桂冠。

近日,在第七届对话系统技术挑战赛(DSTC7)上,首次亮相的微信智言团队一路过关斩将,最终拿下冠军。
DSTC7挑战赛,由来自微软研究院、卡耐基梅隆大学的科学家与2013年发起,分为三个赛道。
来自微信模式识别中心的微信智言参加的是其中之一,基于Fact(比如百科文章、Blog评论)与对话上下文信息,自动生成回答。
在这次比赛中,微信智言提出了一种基于多方位注意力机制,能够“阅读” Fact与对话上下文信息,并利用原创动态聚类解码器,产生与Fact和上下文相关并且有趣的回答。
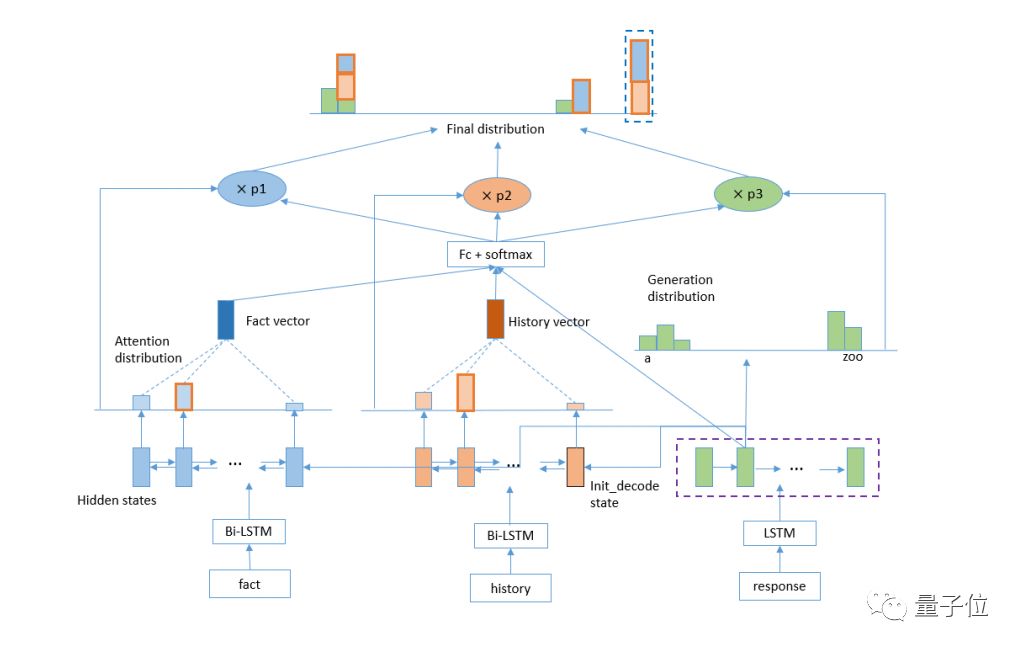
在自动和人工评测都取得最佳成绩,力压赛道中其他竞争对手。
但外界可能有所不知的是,如此成绩背后,向来低调著称的微信,原动力主要为锻炼队伍。
微信智言团队告诉量子位,核心参赛组员,仅一名来自CMU的T4专家为指导,一名实习生为主力,最后为微信证明实力。
或者更具体来说——为微信智言证明实力。
微信AI“二孩”
微信智言,是继微信智聆之后,微信团队推出的又一AI技术品牌,专注于智能对话和自然语言处理等技术的研究与应用,被称为微信AI“二孩”。
在2017年12月开始筹备,2019年1月份微信公开课正式亮相。与腾讯AI Lab相比,微信智言更加聚焦于NLP领域,不论是文本分类、问答、对话,还是语义解析,都有大量投入。
虽然亮相较晚,但实力一点不差。

目前,微信智言团队由来自微软和CMU的T4专家坐镇,共有10多名成员,全部来自国外内顶尖高校的硕士及博士,且都具备学术研究能力与开发能力。
微信智言透露,团队每两个月都会请第三方机构对团队的对话系统实力进行评估。
结果表明,从对话、用户满意度角度来说,微信智言基本上处于第一梯队。
不过,微信智言也强调:竞赛成绩能够展现研究实力,但团队最主要重心,始终在业务上。
瞄准四大领域
微信智言的目标,是打造“对话即服务”平台。现已在智能硬件、PaaS、行业云和AI Bot等四大领域进行了业务部署。
智能硬件
在这一领域,微信智言推出了技术平台“小微”,并面向开发者提供硬件SDK、云服务和APP端接入的一站式开发集成方案。
接入小微平台后,设备可通过智能对话使用音乐、新闻和视频等内置技能,也可通过开放技能平台创建配置自定义技能。
目前已有近百款硬件产品接入小微对话系统,比如哈曼旗下的的JBL等,服务范围涉及运动户外、家居生活、智能车载、智慧产业和新兴市场等领域。

PaaS&行业云
与腾讯云合作,微信智言搭建了PaaS和行业云的语义服务。
其中,PaaS是以云服务为基础的智能语义平台,第三方开发者可以通过API搭建自己的应用和服务,基于行业特点构建出不同的服务和能力。代表性的案例有香格里拉和雅朵合作的智能酒店应用等等。
行业云面向企业客户提供完整的解决方案。为企业快速搭建智能客服平台和行业任务智能对话系统。代表案例有微信支付和春秋航空等。

AI Bot
在微信智言的计划中,未来将提供基于微信生态的语音助手服务。
微信智言表示,AI Bot不仅仅是一个语音助手,还是用户在微信生态下链接内容和服务的入口。不仅能够听懂语音指令,还能将微信生态中的优质内容和服务推送给你。
微信智言成长进行时
虽然已经取得了不小的成果,但其仍旧在成长的过程中。
接下来,微信智言主要发力三个方向:
第一,服务好外部第三方的音箱等智能设备市场,以音箱市场为排头兵,不断迭代,提升效果,满足用户需求。
第二,为腾讯内部业务提供支持,和各个BG合作, 提升产品体验。
第三,继续在学术领域对真正有价值的问题进行探索和解决,产学研结合,将微信智言打造成国内NLP领域的第一梯队。
本次参加竞赛,就是为了在学界进一步锤炼技术水平,同时吸引更多人才加盟。
而且微信也用了“心思”,比如带队实习生的导师,是腾讯技术级别不低的T4专家,诚意之至,可见一斑。
另外,微信智言方面也说了,这只是一个小小体现,更多惊喜,欢迎你亲自去发现。
最后,附上微信智言团队的论文传送门:
Cluster-based Beam Search for Pointer-Generator Chatbot Grounded by Knowledge
http://workshop.colips.org/dstc7/papers/03.pdf
— 完 —
长按二维码,关注我们






