PKD-Bert:基于多层网络的Bert知识蒸馏
来自:NLP从入门到放弃
PKD[1]核心点就是不仅仅从Bert(老师网络)的最后输出层学习知识去做蒸馏,它还另加了一部分,就是从Bert的中间层去学习。
简单说,PKD的知识来源有两部分:中间层+最后输出,当然还有Hard labels。
它缓解了之前只用最后softmax输出层的蒸馏方式出现的过拟合而导致泛化能力降低的问题。
接下来,我们从PKD模型的两个策略说起:PKD-Last 和 PKD-Skip。
1.PKD-Last and PKD-Skip
PKD的本质是从中间层学习知识,但是这个中间层如何去定义,就各式各样了。
比如说,我完全可以定位我只要奇数层,或者我只要偶数层,或者说我只要最中间的两层,等等,不一而足。
那么作者,主要是使用了这么多想法中的看起来比较合理的两种。
PKD-Last,就是把中间层定义为老师网络的最后k层。
这样做是基于老师网络越靠后的层数含有更多更重要的信息。
这样的想法其实和之前的蒸馏想法很类似,也就是只使用softmax层的输出去做蒸馏。但是从感官来看,有种尾大不掉的感觉,不均衡。
另一个策略是 就是PKD-Skip,顾名思义,就是每跳几层学习一层。
这么做是基于老师网络比较底层的层也含有一些重要性信息,这些信息不应该被错过。
作者在后面的实验中,证明了,PKD-Skip 效果稍微好一点(slightly better);
作者认为PKD-Skip抓住了老师网络不同层的多样性信息。而PKD-Last抓住的更多相对来说同质化信息,因为集中在了最后几层。
2. PKD
2.1架构图
两种策略的PKD的架构图如下所示,注意观察图,有个细节很容易忽视掉:
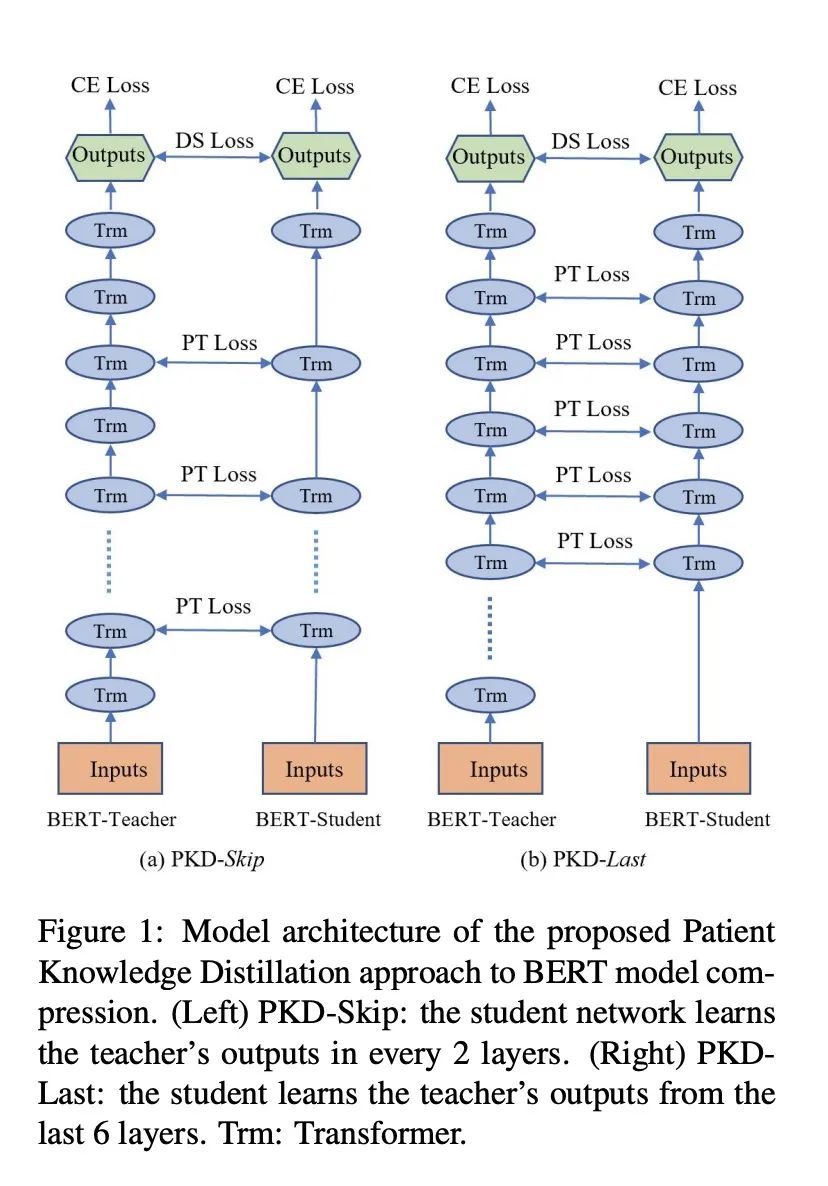
我们注意看这个图,Bert的最后一层(不是那个绿色的输出层)是没有被蒸馏的,这个细节一会会提到。
2.2 怎么蒸馏中间层
这个时候,需要解决一个问题:我们怎么蒸馏中间层?
仔细想一下Bert的架构,假设最大长度是128,那么我们每一层Transformer encoder的输出都应该是128个单元,每个单元是768维度。
那么在对中间层进行蒸馏的时候,我们需要针对哪一个单元?是针对所有单元还是其中的部分单元?
首先,我们想一下,正常KD进行蒸馏的时候,我们使用的是[CLS]单元Softmax的输出,进行蒸馏。
我们可以把这个思想借鉴过来,一来,对所有单元进行蒸馏,计算量太大。二来,[CLS] 不严谨的说,可以看到整个句子的信息。
为啥说是不严谨的说呢?因为[CLS]是不能代表整个句子的输出信息,这一点我记得Bert中有提到。
2.3蒸馏层数和学生网络的初始化
接下来,我想说一个很小的细节点,对比着看上面的模型架构图:
Bert(老师网络)的最后一层 (Layer 12 for BERT-Base) 在蒸馏的时候是不予考虑;
原因的话,其一可以这么理解,PKD创新点是从中间层学习知识,最后一层不属于中间层。当然这么说有点牵强附会。
作者的解释是最后一层的隐层输出之后连接的就是Softmax层,而Softmax层的输出已经被KD Loss计算在内了。
比如说,K=5,那么对于两种PKD的模式,被学习的中间层分别是:
PKD-Skip: ;
PKD-Last:
还有一个细节点需要注意,就是学生网络的初始化方式,直接使用老师网络的前几层去初始化学生网络的参数。
2.4 损失函数
首先需要注意的是中间层的损失,作者使用的是MSE损失。如下:
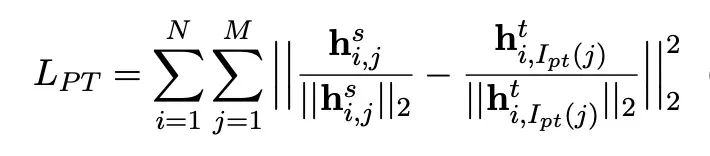
整个模型的损失主要是分为两个部分:KD损失和中间层的损失,如下:
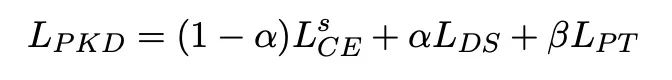
超参数问题:
3. 实验效果
实验效果可以总结如下:
-
PKD确实有效,而且Skip模型比Last效果稍微好一点。 -
PKD模型减少了参数量,加快了推理速度,基本是线性关系,毕竟减少了层数
除了这两点,作者还做了一个实验去验证:如果老师网络更大,PKD模型得到的学生网络会表现更好吗?
这个实验我很感兴趣。
直接上结果图:
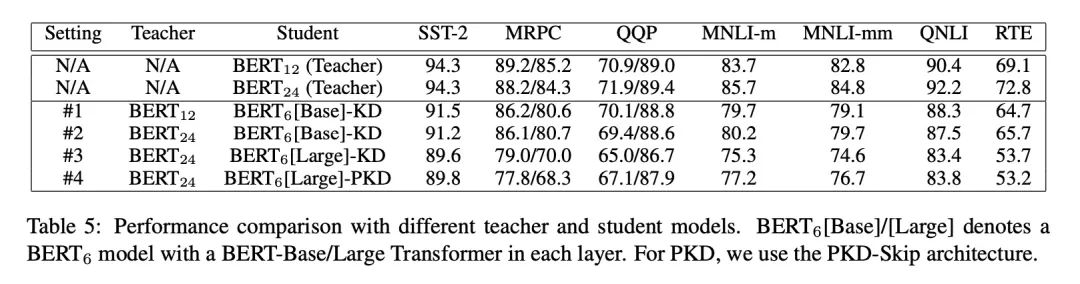
KD情况下,注意不是PKD模型,看#1 和#2,在老师网络增加的情况下,效果有好有坏。这个和训练数据大小有关。
KD情况下,看#1和#3,在老师网络增加的情况下,学生网络明显变差。
作者分析是因为,压缩比高了,学生网络获取的信息变少了。
也就是大网络和小网络本身效果没有差多少,但是学生网络在老师是大网络的情况下压缩比大,学到的信息就少了。
更有意思的是对比#2和#3,老师是大网络的情况下,学生网络效果差。
这里刚开始没理解,后来仔细看了一下,注意#2 的学生网络是 ,也就是它的初始化是从 来的,占了一半的信息。
好的,写到这里
下载一:中文版!学习TensorFlow、PyTorch、机器学习、深度学习和数据结构五件套!
![]()
![]()
![]()
后台回复【五件套】
下载二:南大模式识别PPT
![]()
后台回复【南大模式识别】




由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
整理不易,还望给个在看!


