硬刚无限宽神经网络后,谷歌大脑有了12个新发现

编辑 | 陈彩娴

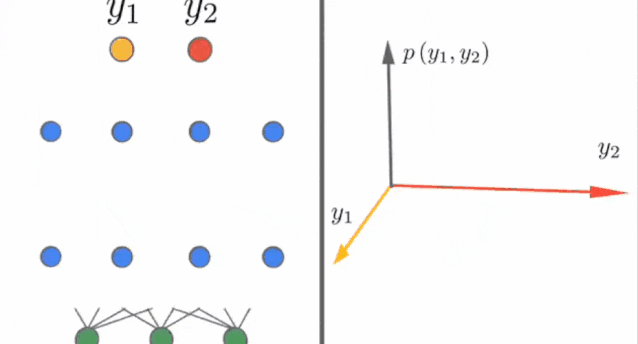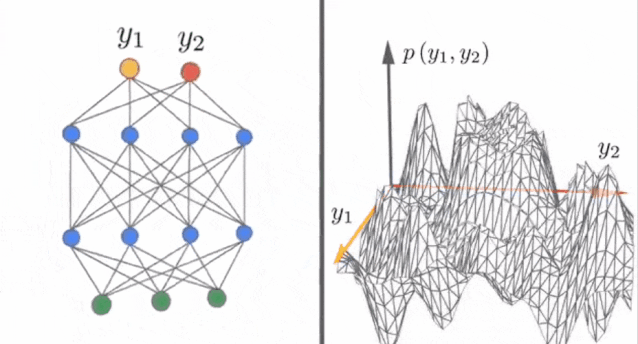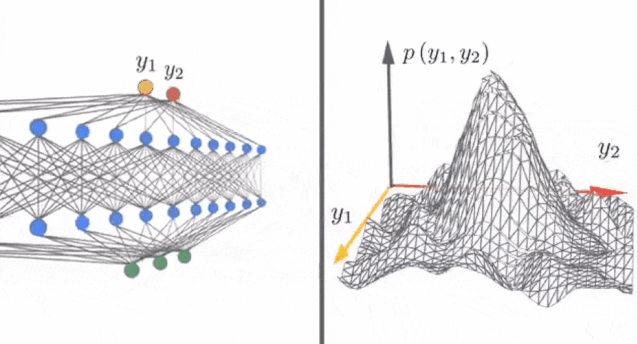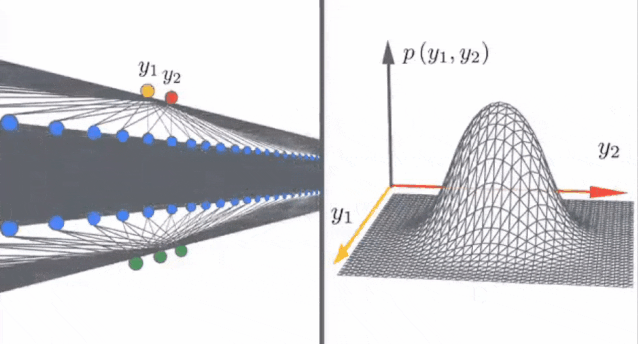
1
实验结果
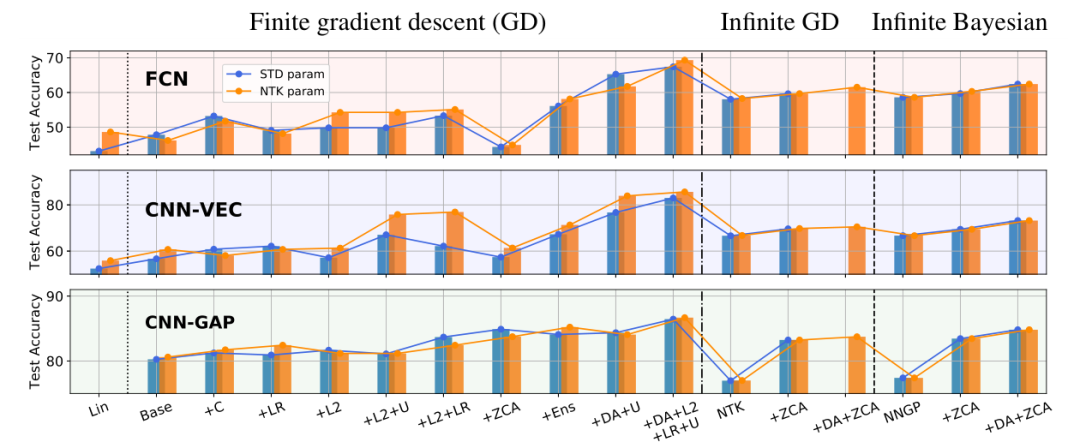 图1:有限宽和无限宽网络的CIFAR-10测试准确率变化。
图1:有限宽和无限宽网络的CIFAR-10测试准确率变化。
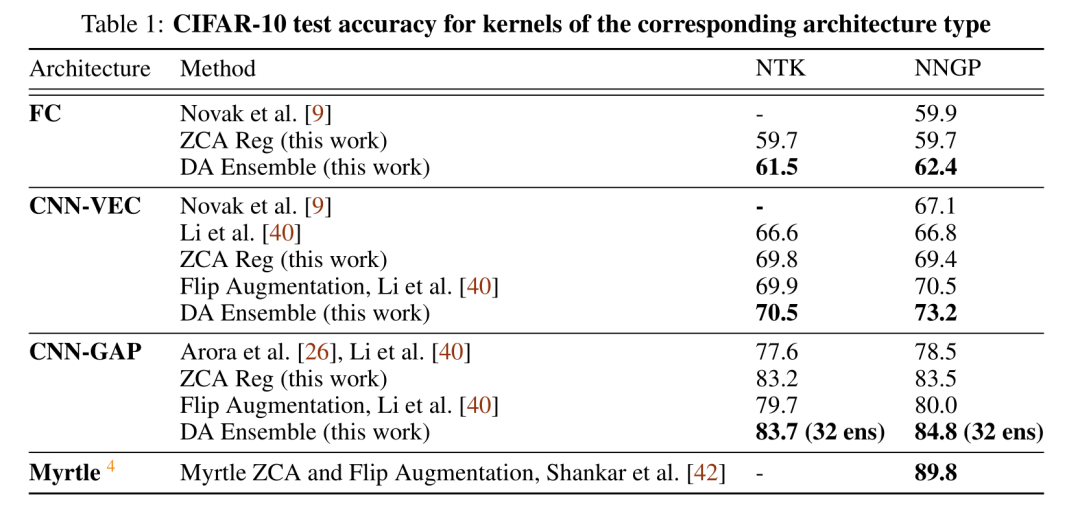
 图2:仔细调整对角正则化条件时,NNGP在图像分类任务中通常胜过NTK。
图2:仔细调整对角正则化条件时,NNGP在图像分类任务中通常胜过NTK。
 图3:中心化可以加快训练速度并提高表现。整个训练过程中的验证准确率适用于几种有限宽的架构。
图1:有限宽和无限宽网络的CIFAR-10测试准确率变化。
图3:中心化可以加快训练速度并提高表现。整个训练过程中的验证准确率适用于几种有限宽的架构。
图1:有限宽和无限宽网络的CIFAR-10测试准确率变化。
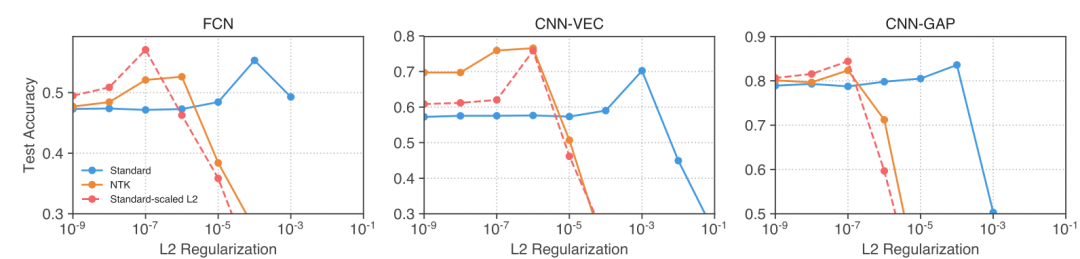 图5:NTK驱动的层级缩放使L2正则化在标准参数化网络中更有帮助。
图5:NTK驱动的层级缩放使L2正则化在标准参数化网络中更有帮助。
 图6:随着宽度的增加,有限宽网络通常表现得更好,但是CNN-VEC显示出惊人的非单调行为。L2:训练期间允许非零权重衰减 ,LR:允许大学习率。虚线表示允许欠拟合(U)。
图6:随着宽度的增加,有限宽网络通常表现得更好,但是CNN-VEC显示出惊人的非单调行为。L2:训练期间允许非零权重衰减 ,LR:允许大学习率。虚线表示允许欠拟合(U)。
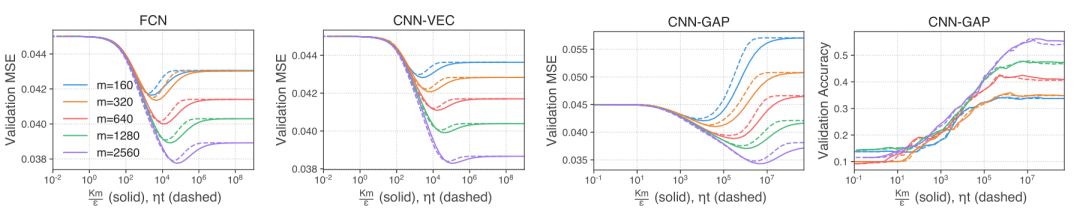 图7:对角核正则化的作用类似于 early stopping。实线对应于具有可变对角线正则化ε的NTK推断。虚线对应于梯度下降演化到特定时间后的预测。线颜色表示不同的训练集大小m。在时间t执行早期停止与系数ε的正则化密切相关,其中K=10表示输出类别的数量。
图7:对角核正则化的作用类似于 early stopping。实线对应于具有可变对角线正则化ε的NTK推断。虚线对应于梯度下降演化到特定时间后的预测。线颜色表示不同的训练集大小m。在时间t执行早期停止与系数ε的正则化密切相关,其中K=10表示输出类别的数量。
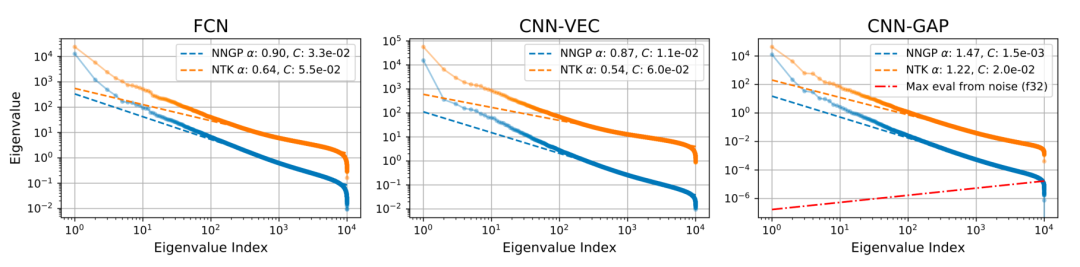 图8:无限网络核的尾部特征值显示幂律衰减。红色虚线表示宽度增大的核矩阵由于浮点精度而在特征值中预测的噪声比例。CNN-GAP结构的特征值衰减很快,当数据集大小为O(10^4)时,可能会被float32量化噪声所淹没。对于float64精度,在数据集大小为O(10^10)之前,量化噪声不会变得显著。
图8:无限网络核的尾部特征值显示幂律衰减。红色虚线表示宽度增大的核矩阵由于浮点精度而在特征值中预测的噪声比例。CNN-GAP结构的特征值衰减很快,当数据集大小为O(10^4)时,可能会被float32量化噪声所淹没。对于float64精度,在数据集大小为O(10^10)之前,量化噪声不会变得显著。
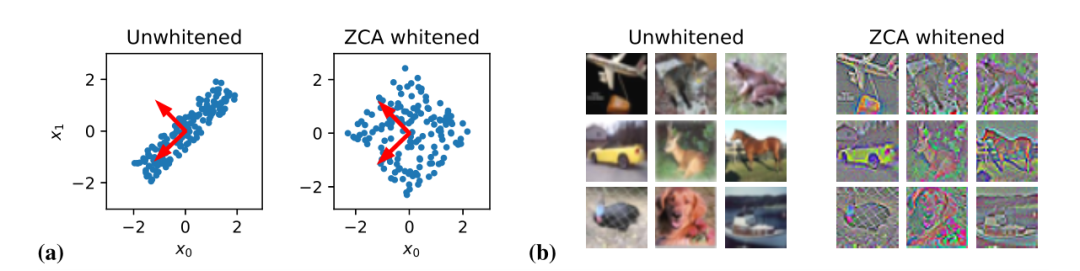
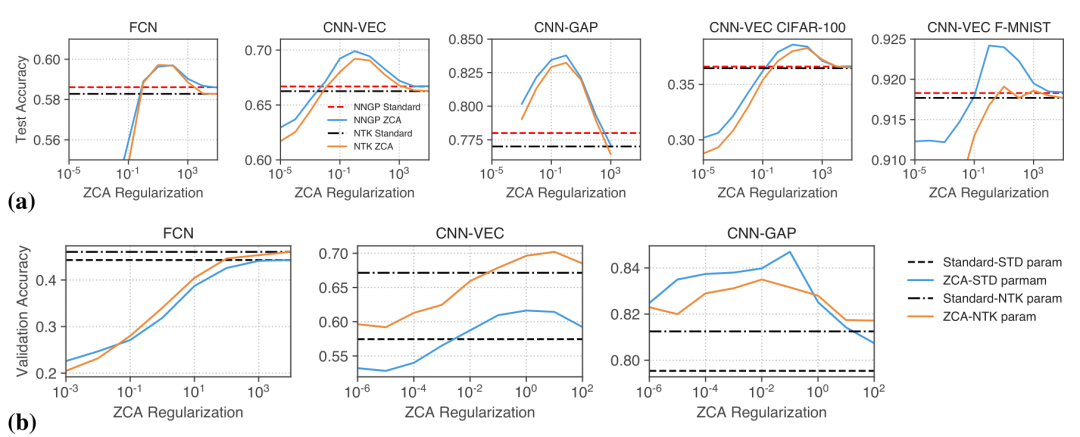 图9:正规化ZCA白化改善了有限宽度和无限宽度网络的图像分类性能。所有曲线均显示性能是ZCA正则强度的函数。(a)对CIFAR-10,Fashion-MNIST和CIFAR-100上的内核方法的输入进行ZCA白化。(b)对有限宽度网络的输入进行ZCA白化(图S11中的训练曲线)。
图9:正规化ZCA白化改善了有限宽度和无限宽度网络的图像分类性能。所有曲线均显示性能是ZCA正则强度的函数。(a)对CIFAR-10,Fashion-MNIST和CIFAR-100上的内核方法的输入进行ZCA白化。(b)对有限宽度网络的输入进行ZCA白化(图S11中的训练曲线)。
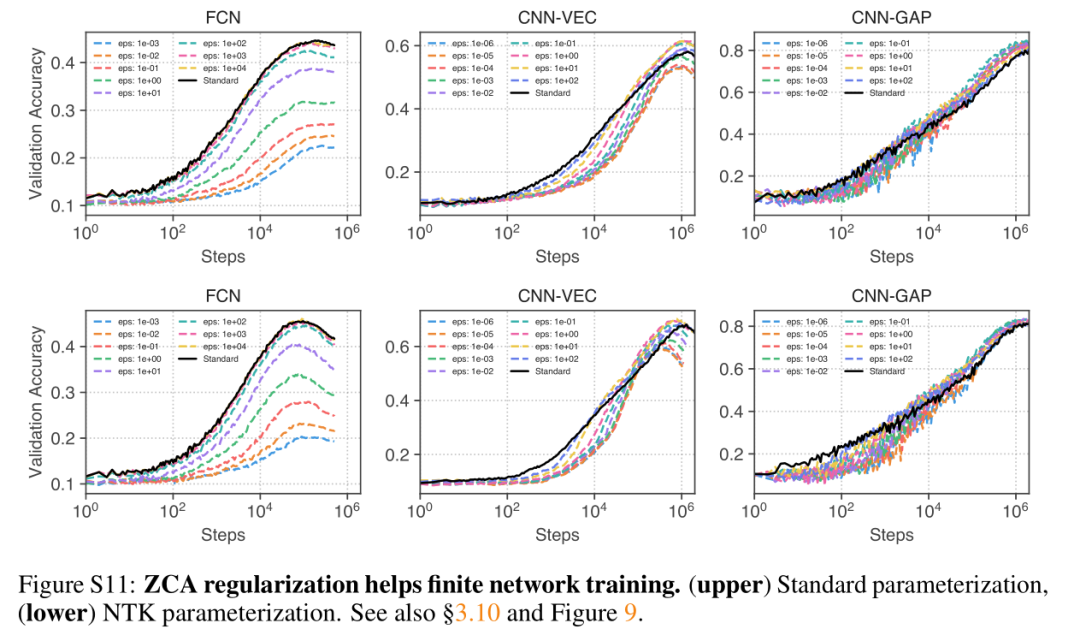

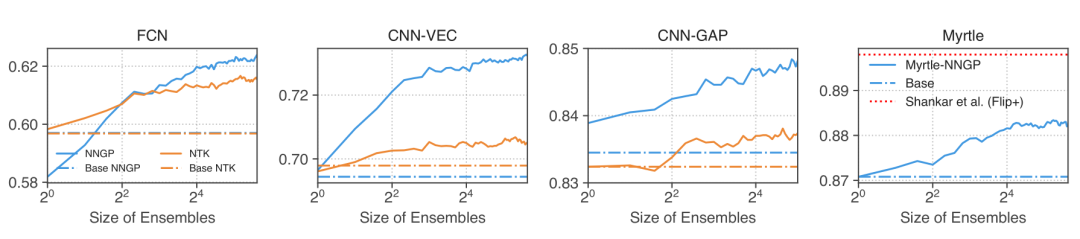 图11:集成内核预测变量使从大型增强数据集进行的预测易于计算。
图11:集成内核预测变量使从大型增强数据集进行的预测易于计算。
2
论文信息
![]()
2
论文信息
![]()


登录查看更多
相关内容
Arxiv
8+阅读 · 2018年11月21日
Arxiv
4+阅读 · 2018年4月30日




相关VIP内容
相关资讯
相关论文
Arxiv
8+阅读 · 2018年11月21日
Arxiv
4+阅读 · 2018年4月30日